







关注公众号,发现CV技术之美
本篇分享论文『Semantically Self-Aligned Network for Text-to-Image Part-aware Person Re-identification』,华南理工提出多模态ReID新数据集,语义自对齐网络SSAN达到SOTA性能!代码数据集均已开源!
详细信息如下:

论文地址:https://arxiv.org/pdf/2107.12666.pdf[1]
代码地址:https://github.com/zifyloo/SSAN[2]
01
摘要
文本到图像的人物再识别(ReID)旨在使用文本描述搜索包含感兴趣人物的图像。然而,由于在文本描述中存在显著的模态差异和较大的类内差异,文本到图像ReID仍然是一个具有挑战性的问题。
因此,在本文中,作者提出了一种语义自对齐网络(SSAN)来处理上述问题。首先,作者提出了一种新的方法,自动提取其相应视觉区域的部分级文本特征。其次,设计了一个多视图非局部网络,捕捉身体部位之间的关系,从而在身体部位和名词短语之间建立更好的对应关系。第三,引入了一种复合排序(CR)损失,该损失利用相同身份的其他图像的文本描述来提供额外的监督,从而有效地减少了文本特征的类内方差。最后,为了加快文本到图像ReID的未来研究,作者建立了一个新的数据库ICFG-PEDES。
大量实验表明,SSAN在很大程度上优于最先进的方法。
02
Motivation
文本部到图像人物再识别(ReID)是指根据自然语言描述搜索包含感兴趣人物(例如失踪儿童)的图像。当没有目标人的探测图像并且只有文本描述可用时,它是一个重要而强大的视频监控工具。与使用预先定义的属性的ReID作品相比,文本描述包含了更多的信息,因此描述了更多样化和更细粒度的视觉模式。不幸的是,现有的大多数ReID文献都关注基于图像的ReID,文本到图像的ReID仍处于起步阶段。
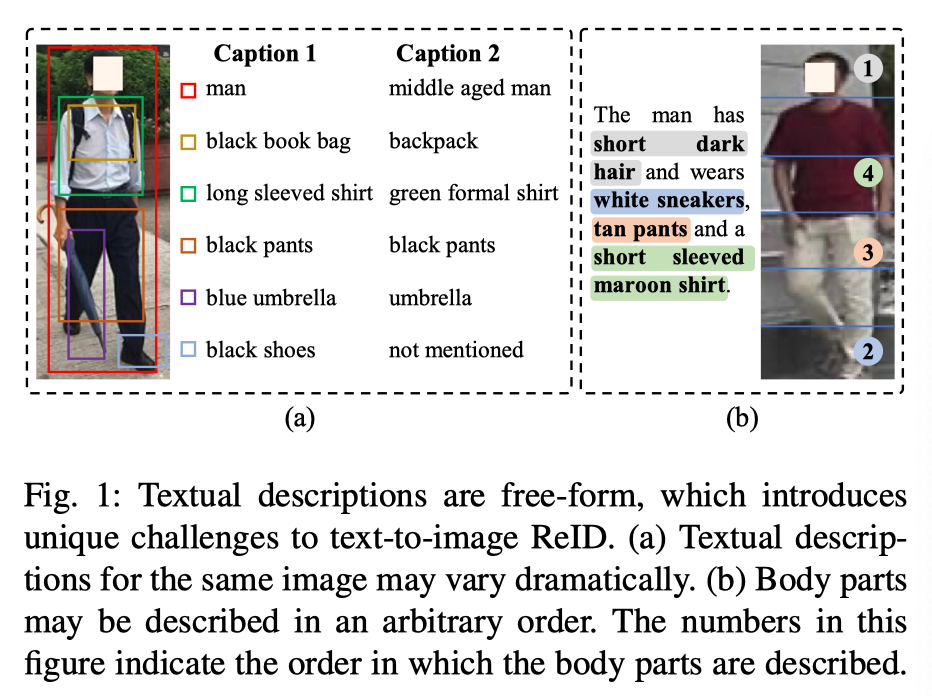
文本到图像的ReID比基于图像的ReID更具挑战性。其中一个主要原因是文本描述是自由形式的,这造成了两个主要问题。首先,如上图(a)所示,同一图像的文本描述可能会发生显著变化,导致文本特征的类内差异很大。其次,身体部位通常是和行人检测对齐良好;然而,如上图(b)所示,身体部位可以用不同数量的单词以任意顺序进行描述,因此在从两种模式中提取语义对齐的部件级特征时存在困难。
因此,跨模态对齐对于文本到图像ReID至关重要。一种流行的跨模态对齐策略涉及采用注意力模型来获取身体部位和单词之间的对应关系。然而,该策略依赖于每个图像-文本对的跨模态操作,这在计算上很昂贵。
另一种直观的策略是使用外部工具,例如自然语言工具包
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3679
3679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









