






关注公众号,发现CV技术之美
深圳市大数据研究院提出了一种标签高效式地细胞核图像分割方法 (Which Pixel to Annotate: a Label-Efficient Nuclei Segmentation Framework),被医学图像分析顶级期刊IEEE Transactions on Medical Imaging接收。
该方法包括三个部分:一个基于一致性的样本选择算法、基于单个样本对的有条件生成器、一个半监督图像分割网络模型。该方法仅使用不到5% 的标注的情况下,在多个病理图像数据集上达到了接近全监督方法的细胞核分割性能。
文章链接:https://arxiv.org/abs/2212.10305
代码链接:https://github.com/lhaof/NuSeg
01
问题背景介绍
细胞核分割任务,是指标记出病理图像中每一个属于细胞核的像素。细胞核分割的结果可以提供基本的细胞核视觉信息和形态学特征例如尺寸,形状或者颜色。这些信息和特征不仅有助于病理图像的进一步处理(例如分类或者组织分割),也有助于病理医生诊断分析病情的发展(例如癌症的诊断评估和预后)。
因此,细胞核分割在计算机辅助诊疗系统中是至关重要的一环。然而,病理图像复杂的背景,细胞核杂乱的分布都极大地增加了精确分割细胞核的难度。同时,训练一个精确分割细胞核的模型通常需要大量的有标注数据(细胞核的数量达到数万级别),这也显著地增加了病理医生标注的负担和时间经济成本。
为了解决现有技术需要大量标注数据的问题,本文提出了一种基于一致性的样本块选择算法。该算法挑选极少量的具有高代表性和内部纹理一致性的无标签样本块进行标注。为了解决现有技术在标注较少时分割性能较差的问题,本文提出了一种有条件输入的基于单对训练图片的对抗生成模型CSinGAN来对训练数据进行扩增。为了充分利用大量的无标签数据,本文通过和半监督方法-伪标签生成的结合来利用无标签数据。实验证明文提出的框架利用不到百分之五的标注,在三个公开数据集上达到了接近全监督方法的性能。
02
方法介绍
 图1. 标签高效式的细胞核图像分割方法流程图
图1. 标签高效式的细胞核图像分割方法流程图
2.1 整体框架
本文提出的标签高效式的细胞核图像分割框架的框架如图1所示。从左到右,首先进行无标签病理图像数据的采集。其次,通过本文提出的基于一致性的样本块选择算法,少量的小尺寸的病理图像样本块将会被选择并且由病理医生进行标注,标注之后的掩膜和选择的样本块将会组成样本对。
每一对样本对将会作为本文提出的有条件输入的基于单对训练图片的对抗生成模型的训练样本。经过对抗生成模型的训练,大量的训练样本对将会被模型生成并且加入分割训练集。最后,所有的标注的真实样本对加上模型生成的伪样本对将会输入基于伪标签的半监督细胞核分割模型进行训练,得到能够精准分割病理图像细胞核的模型。

图2. 基于一致性的样本块选择算法
2.2 基于一致性的样本块选择算法(CPS)
为了定位最有益于细胞核分割任务的病理图像样本块区域,我们定义两种挑选参数。一种叫做代表性,另一种叫做内部一致性。代表性指的是被挑选样本块与整个数据集中的其他的样本块之间的关系。为了减轻对抗生成模型生成伪样本的复杂程度,我们还考虑选择内部一致性更高的样本块。内部一致性是指样本块内部各区域具有相似的纹理和细胞核形态。高内部一致性有助于减少对抗生成模型学习的难度,减少干扰,有助于模型的收敛,也能够更有效生成高质量的图片。
CPS算法可以分成三部分:1.小尺寸样本块采样;2.双层聚类;3.分数计算。在小尺寸样本块采样部分,我们从原始的病理图片数据集中利用滑动窗口均匀地采样样本块。在双层聚类部分,执行了两次K-means聚类。第一次聚类为粗聚类,将小尺寸样本块聚类成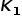 个聚类簇。为了计算内部一致性,每一个聚类簇中的小尺寸样本块又会被再裁切成四个更小的子区域进行第二次聚类得到
个聚类簇。为了计算内部一致性,每一个聚类簇中的小尺寸样本块又会被再裁切成四个更小的子区域进行第二次聚类得到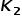 个聚类簇,也叫作细聚类。经过两次聚类,最终可以得到
个聚类簇,也叫作细聚类。经过两次聚类,最终可以得到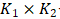 个聚类簇。在分数计算部分,对每一个粗聚类得到的聚类簇
个聚类簇。在分数计算部分,对每一个粗聚类得到的聚类簇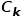 ,我们会计算该簇中所有的小尺寸样本块的代表性和内部一致性分数,最终选择一个分数最高的样本块。计算公式如图2的右半部分所示。基于一致性的样本选择算法最后会为粗聚类的每一类挑选一个样本块,最终得到
,我们会计算该簇中所有的小尺寸样本块的代表性和内部一致性分数,最终选择一个分数最高的样本块。计算公式如图2的右半部分所示。基于一致性的样本选择算法最后会为粗聚类的每一类挑选一个样本块,最终得到 个样本块。
个样本块。

图3. 有条件输入的基于单对训练图片的对抗生成模型
2.3 有条件输入的基于单对训练图片的对抗生成模型(CSinGAN)
在得到标注好的小尺寸样本块之后,本文提出了一个有条件输入的基于单对训练图片的对抗生成模型(CSinGAN)对每一对样本块分别进行数据增强。每个CSinGAN模型会使用一对标注好的样本块和本文内方法大量简单构建的伪掩膜。其结构如图3所示,该模型包含一个多尺度的生成器和一个多组件的判别器。生成器和判别器分别表示为 和
和 。多尺度有条件生成器可以表示为公式(1):
。多尺度有条件生成器可以表示为公式(1):
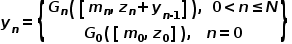 (1)
(1)
其中, 和
和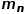 表示真实的标注掩膜和本文构建的伪掩膜。当计算
表示真实的标注掩膜和本文构建的伪掩膜。当计算 时,所有的
时,所有的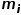 (
(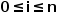 )都是通过改变
)都是通过改变 的尺寸得到的。
的尺寸得到的。 和
和 表示三通道的高斯噪声图像。每个尺度的生成器和判别器都会计算一个重建损失和判别损失来优化模型,如公式(2)所示:
表示三通道的高斯噪声图像。每个尺度的生成器和判别器都会计算一个重建损失和判别损失来优化模型,如公式(2)所示:
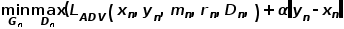 ) (2)
) (2)
其中,第二项 为重建损失,
为重建损失,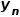 为生成图像,
为生成图像,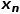 则为真实图像。对于判别损失,本文设计了一种新型的多组件的判别器。该判别器将输入图像分离为前景,背景和原图三类图像分别进行判断。判别器包含三个子网络,分别对三类图像进行判别,彼此之间互不参数共享。整个判别过程可以用如下公式(3)表示:
则为真实图像。对于判别损失,本文设计了一种新型的多组件的判别器。该判别器将输入图像分离为前景,背景和原图三类图像分别进行判断。判别器包含三个子网络,分别对三类图像进行判别,彼此之间互不参数共享。整个判别过程可以用如下公式(3)表示:
 (3)
(3)
其中, 指第n个尺度下的伪掩膜,
指第n个尺度下的伪掩膜, 指真实掩膜。
指真实掩膜。 指按元素相乘操作,
指按元素相乘操作,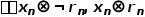 指的就是提取
指的就是提取 的背景区域和前景区域。这样不同的子网络
的背景区域和前景区域。这样不同的子网络 就会关注于不同的生成区域的真实程度。这有助于生成和伪掩膜中细胞核位置精确对应的生成图像。
就会关注于不同的生成区域的真实程度。这有助于生成和伪掩膜中细胞核位置精确对应的生成图像。
2.4 基于伪标签的半监督训练方法(Plabel)
在得到大量的生成的伪训练图片对之后,本文引入了基于伪标签的半监督训练方法来充分利用无标签数据。伪标签方法通常使用一个预训练的模型来对无标签数据进行预测。预测出来的结果可以和原始数据结合作为一种标签参与新一轮的训练来提升模型的性能。实验证明,本文可以结合其他的半监督方法或细胞核分割模型使用来提升性能。
03
实验结果
3.1与全监督方法的比较
 表1. 本文框架和全监督方法比较
表1. 本文框架和全监督方法比较
如表 1 所示,本文整体框架结合先前分割方法在使用不到5%标注的情况下,在TCGA-KUMAR数据集上和最强的全监督方法Hover-net仅差距0.2%分割指标AJI,在TNBC数据集上达到了超过Hover-net的效果。在MoNuSeg数据集上得到了略低于Hover-net约1.17% AJI的结果。这充分显示了本文在缺少标签的病理图片分割应用场景的优势,即极大了减少了标注成本。
3.2 各组件的效果
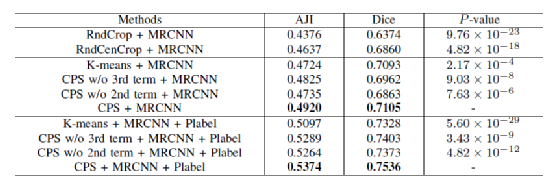
表2. 使用不同组件在TCGA-KUMAR数据集上的结果
如表2所示,CPS表示基于一致性的样本选择算法,MRCNN指的是分割模型Mask-RCNN,CSinGAN指的是有条件输入的基于单对训练图片的对抗生成模型,Plabel表示伪标签训练方法。从结果可以看出,CSinGAN方法使分割模型在TCGA-Kumar数据集上提升了1.34% AJI。本文提出的样本选择算法CPS相较随机采样方法提升了约2.83% AJI。加入基于伪标签的半监督训练方法之后,本文的分割性能可以进一步提升4.54% AJI。
3.3 CSinGAN方法对比同类生成方法

表3. CsinGAN比较其他样本生成方法。
如表3所示,在使用CPS挑选的样本进行样本生成,使用Mask-RCNN作为分隔模型的情况下。CSinGAN相较主流的样本生成方法cycleGAN有约1% AJI的提升。
04
总结
本文构建了一种全新的标签高效式的细胞核分割框架能够使用不到百分之五的标注达到或接近全监督方法的分割效果。其次,本文提出了一种基于一致性的样本选择算法,该算法挑选的样本能够使模型分割精度更高。此外,本文提出了一种新颖的组件式判别器,大大提高了生成对抗模型的图像生成质量。本文显示了样本选择的重要性,为使用少量标注训练医学影像模型提供了新的思考。

END
欢迎加入「医学影像」交流群👇备注:Med
















 448
448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









