






关注公众号,发现CV技术之美
本篇分享论文SC4D: Sparse-Controlled Video-to-4D Generation and Motion Transfer,华中科技大学、阿里达摩院提出 SC4D: 基于稀疏控制点的单视角视频到 4D 生成及运动迁移框架。
项目主页:https://sc4d.github.io/
代码仓库:https://github.com/JarrentWu1031/SC4D
论文链接:https://arxiv.org/abs/2404.03736
1. 背景
1.1 任务设置
4D生成目标在于生成一个动态的物体或场景,当给定一个时间相关的相机轨迹时,通过对得到的4D目标进行投影可以渲染出相应的动态视频。本文针对的任务为从一个单视角视频中生成对应的动态物体,由于输入是单视角视频,目标物体有大面积不可见区域,保持生成动态物体与参考视频的高对齐度、时空一致性和动作的合理性十分具有挑战。
1.2 相关方法
由于当下真实4D数据的稀缺,直接生成4D物体是非常困难的。得益于近两年2D/3D基础生成模型的发展,通过对2D/3D模型的蒸馏来实现4D生成成为当下主流的方案。Consistent4D[1],4DGen[2]通过SDS[3]方式对Zero123[4]中的先验知识进行蒸馏,并提出了相应的约束保持时域一致性。
2. 本文方案
2.1 研究动机
本文认为,4D表征对于单动态物体优化过程十分重要。在早前的工作中,Consistent4D[1]和4DGen[2]分别使用动态NeRF和稠密4d高斯作为表征。
然而,由于NeRF的隐式特性,以及稠密高斯运动学习的困难性。上述工作在与参考视频的高对齐度、时空一致性和动作的合理性上难以达到较好的平衡。
受启发于近期的动态场景重建工作SC-GS[5],本文提出了一种基于稀疏控制点的单视角视频到4D物体的框架SC4D,通过对动作和外观的分离建模,减少了两者在学习过程中的模糊性和冲突。
对于在学习过程中由于控制点和稠密高斯的不对齐导致的形状外观退化问题,本文提出了一种适应性高斯(AG)初始化方法以及高斯对齐(GA)损失,保证了最终4D结果的优越性。
2.2 Video-to-4D生成
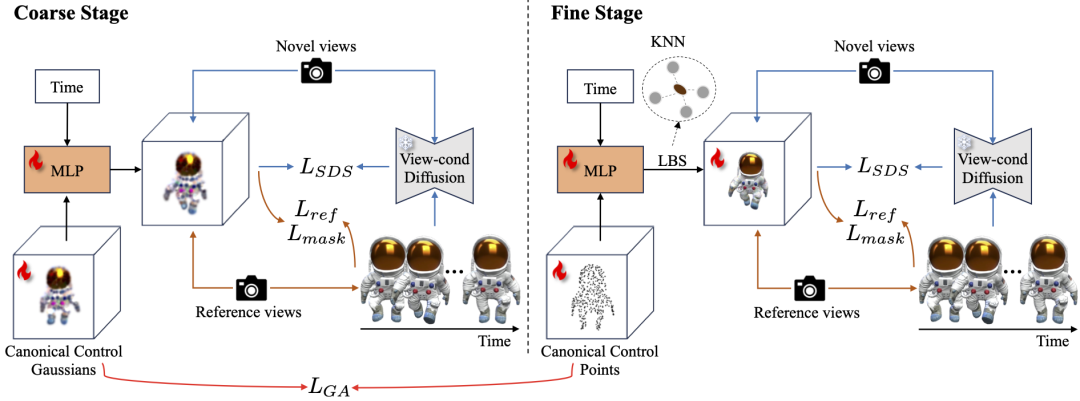
SC4D框架分为两阶段。在第一阶段,稀疏控制点会被初始化为显式的3D高斯球体,并由一个MLP来学习每个高斯的运动。
对于参考视角,使用与参考视频帧的重建损失以及掩码损失进行优化。
对于随机采样的新视角,使用送入Zero123中计算的SDS损失对目标4D物体进行优化。该过程会学习出一个与目标视频动作大致对齐,外观粗糙的目标物体。
在第二阶段开始前,本文发现,稠密高斯的初始化方式会很大程度上影响最终的生成效果。主要原因在于,一阶段的控制高斯在二阶段会转为隐式控制点,若二阶段稠密高斯初始化方式未与控制点对齐,则会导致优化初期控制点运动和形状的效果变差。
为了解决上述问题,本文提出了一种适应性高斯(AG)初始化方法,如下图所示:
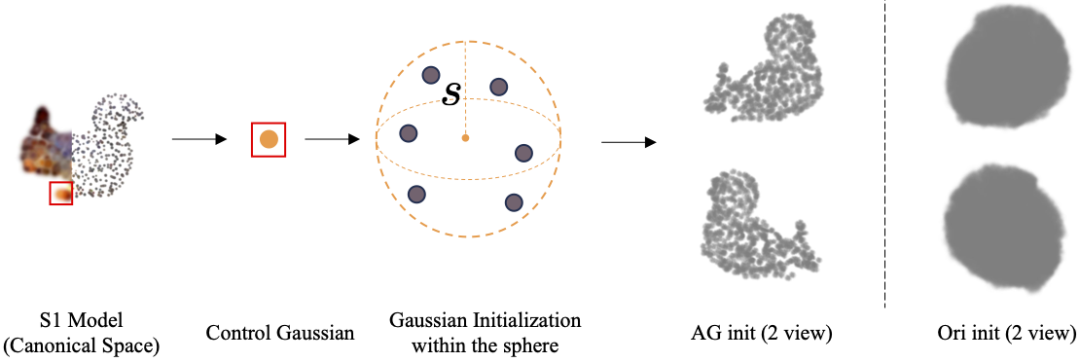
AG 初始化对于每个一阶段的控制点高斯,以其 scale 参数为半径随机初始化 K 个稠密高斯,这些稠密高斯保证相互不重叠。假设共有 M 个控制点,则初始化后会得到 N=M * K 个稠密高斯。
由图中可以看到,经过 AG 初始化后的稠密高斯在开始阶段就很好继承了一阶段的形状,并与相应控制点对齐得很好。对于每个稠密高斯,其运动由其最近邻的四个控制点的运动插值得到。
除开在第二阶段初期控制点与稠密高斯不对齐导致的形状退化问题外,最终的动态物体仍可能发生变厚、位置偏移、纹理变差等问题。
造成这些问题的原因在于,在使用SDS从Zero123中蒸馏物体新视角的先验时,在训练前期当加噪尺度较大时,蒸馏得到的分数会着重于对物体形状的优化。
而在训练后期,为了加强纹理的优化,加噪尺度的减小会导致蒸馏分数无法保持物体的正常形状,从而导致物体变厚、位置偏移等问题。
为了解决上述问题,本文提出了一种简单有效的损失函数:高斯对齐(GA)损失。由于一阶段中不用考虑细节纹理的优化,其蒸馏所用加噪系数是相对更大的,这也使得一阶段控制点的位置和运动是更能还原物体的形状的。
对于某采样时刻t,高斯对齐损失会计算t时刻下的当前控制点位置与第一阶段对应时间的控制点位置的L2距离作为能量函数:
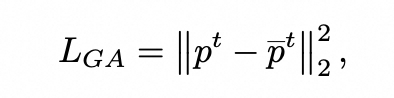
有了 AG 初始化和 GA 损失作为保证,最终生成的 4D 物体便拥有了合理的动作和外观。
2.3 动作迁移
本文还设计了一种基于控制点的运动迁移框架,如下图所示:
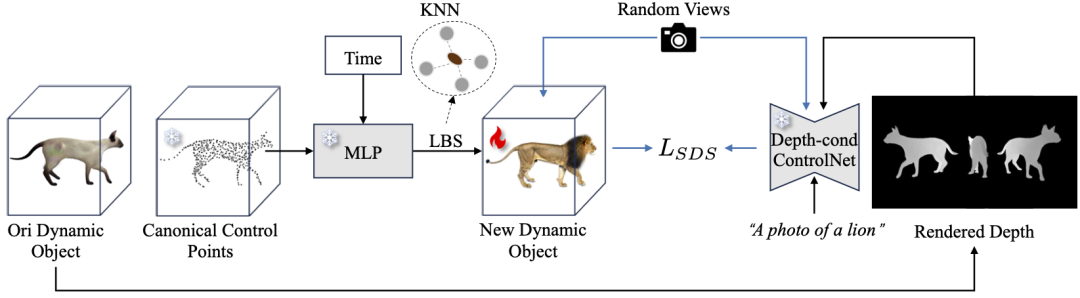
假设已经拥有Video-to-4D生成过程中得到的控制点及稠密高斯,本文固定代表运动的所有参数,并使用AG初始化得到迁移个体的初始化高斯。
随后,以原4D物体在采样t时刻指定视角下渲染出的深度以及对外观的文本描述作为监督,借助Depth-Condition的ControlNet[6]计算SDS损失来优化代表外表的稠密高斯的参数。
在训练的后半程,本文将Depth源替换为了保存的中间状态的新4D个体,这样能够在最终的纹理细节和动作一致性上有更好的表现。
3. 实验结果
3.1 Video-to-4D生成

在Video-to-4D生成任务,本文对比了现有的两种方法:Consistent4D以及4DGen。如上图所示,在与参考视角的符合程度、时空一致性、动作合理度上本文提出的SC4D都要优于对比的两种方法。
在定量对比中,SC4D同样超过了其他两种方法:

3.2 消融实验

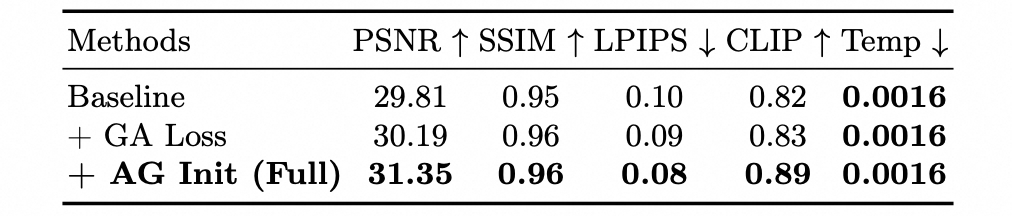
由上图和表中可以看到,本文提出的GA损失和AG初始化都对最终结果形状和动作的准确性有至关重要的作用
3.3 动作迁移

以上展示了部分本文方法进行动作迁移的例子。可以看到,生成的结果拥有和目标贴合的动作,并且外观能够根据文本灵活切换,且效果逼真。更多的例子请见:
项目主页https://sc4d.github.io/
参考文献
[1] Jiang Y, Zhang L, Gao J, et al. Consistent4d: Consistent 360 {\deg} dynamic object generation from monocular video[J]. arXiv preprint arXiv:2311.02848, 2023.
[2] Yin Y, Xu D, Wang Z, et al. 4dgen: Grounded 4d content generation with spatial-temporal consistency[J]. arXiv preprint arXiv:2312.17225, 2023.
[3] Poole B, Jain A, Barron J T, et al. Dreamfusion: Text-to-3d using 2d diffusion[J]. arXiv preprint arXiv:2209.14988, 2022.
[4] Liu R, Wu R, Van Hoorick B, et al. Zero-1-to-3: Zero-shot one image to 3d object[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2023: 9298-9309.
[5] Huang Y H, Sun Y T, Yang Z, et al. Sc-gs: Sparse-controlled gaussian splatting for editable dynamic scenes[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 4220-4230.
[6] Zhang L, Rao A, Agrawala M. Adding conditional control to text-to-image diffusion models[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 3836-3847.
最新 AI 进展报道
请联系:amos@52cv.net

END
欢迎加入「4D生成」交流群👇备注:生成



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









