






关注公众号,发现CV技术之美
本篇分享论文MonST3R: A Simple Approach for Estimating Geometry in the Presence of Motion,探索在运动状态下估算几何图形的简单方法——MonST3R。作者来自UC伯克利、DeepMind等。

论文链接:https://arxiv.org/abs/2410.03825
代码链接:https://github.com/Junyi42/monst3r
项目链接:https://monst3r-project.github.io/
演示链接:https://monst3r-project.github.io/page1.html
视频结果展示:
摘要
从动态场景中估计几何形状,尤其是物体随时间移动和变形的情景,仍然是计算机视觉中的一个核心挑战。目前的方法通常依赖多阶段管道或全局优化,将问题分解为深度和光流等子任务,使得系统复杂且容易出错。
本文提出一种新的以几何为中心的方法—— Motion DUSt3R(MonST3R),直接从动态场景中估计每个时间步的几何形状。其中关键见解是,通过简单地为每个时间步估计点图,可以有效地将 DUST3R 的表示(之前仅用于静态场景)适应于动态场景。然而,这种方法面临一个重大挑战:缺乏适合的训练数据,即带有深度标签的动态视频。
但作者表示,通过将问题视为微调任务,识别多个合适的数据集,并在有限的数据上有策略地训练模型,也能成功使模型能够处理动态场景,即使没有明确的运动表示。基于此,针对几个下游视频特定任务引入了新的优化,并在视频深度和相机姿态估计方面表现出色,超越了之前的工作,展现出更高的鲁棒性和效率。此外,MonST3R 在前馈 4D 重建方面也显示出良好的结果。
方法
本文利用 DUSt3R 的点图表示来直接估计动态场景的几何形状。DUSt3R 的点阵图表示法:估算两帧的 xyz 坐标,并以第一帧的相机坐标对齐。但对于 DUSt3R 是否可以有效地处理带有移动物体的视频数据。作者发现 DUSt3R 训练数据分布存在两个重大限制。
如下图所示:

左图:DUSt3R 对齐了移动的前景主体,但由于只在静态场景中进行了训练,因此对齐了背景点。
右图:DUSt3R 无法估计前景主体的深度,将其置于背景中。
但引起这些局限的主要问题是数据缺失,因此通过对一小部分动态视频进行微调,可以使 DUSt3R 适应动态场景,效果出人意料地好。

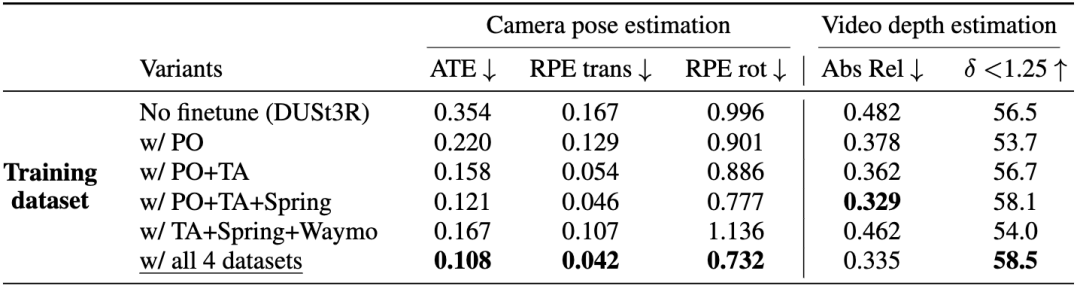
主要贡献:
提出 Motion DUSt3R (MonST3R),一种几何优先的动态场景方法,它能以点图的形式直接估计几何图形,即使是移动的场景元素也不例外。为此,确定几个合适的数据集,可喜的是,小规模的微调也能够实现动态场景直接几何估计的良好结果。
MonST3R 在多个下游任务(视频深度和相机位姿估计)上取得了令人满意的结果。与之前的工作相比,MonST3R 尤其具有以下主要优势:
鲁棒性更强,尤其是在具有挑战性的场景中;
与基于优化的方法相比,速度更快;
在视频深度估计、相机位姿估计和密集重建方面,与专门技术相比,结果更具竞争力。
实验结果
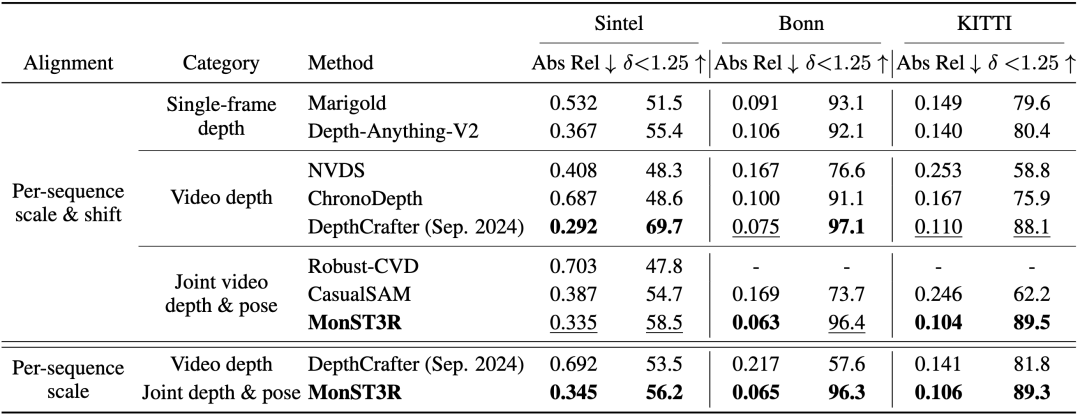
video depth estimation(视频深度估计)
定量结果
从定量结果来看,视频深度估计与该特定任务方法相比性能仍有竞争力,甚至与最近发布的DepthCrafter相当。
定性结果
从定性结果来看,MonST3R 与真实深度的对齐效果更好,如下图 Bonn 数据集中第一行的结果。

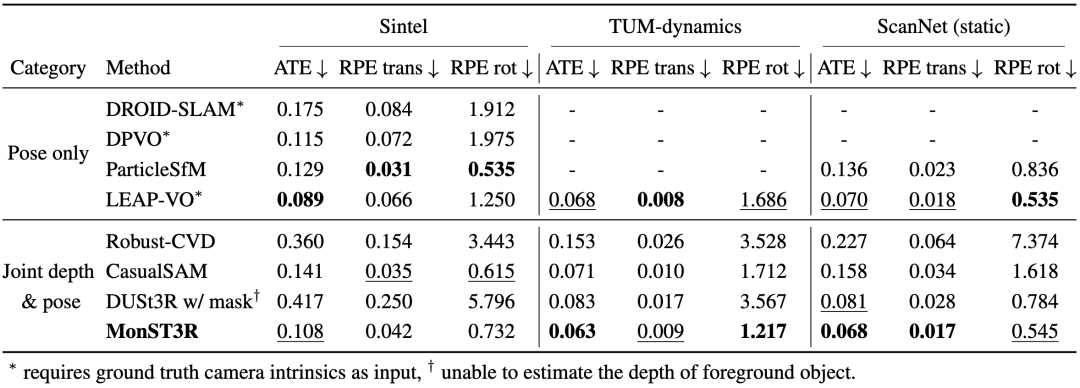
camera pose estimation(相机位姿估计)
定量结果
从定量结果来看,相机位姿估计结果在与任务特定方法的比较中同样具有竞争力。
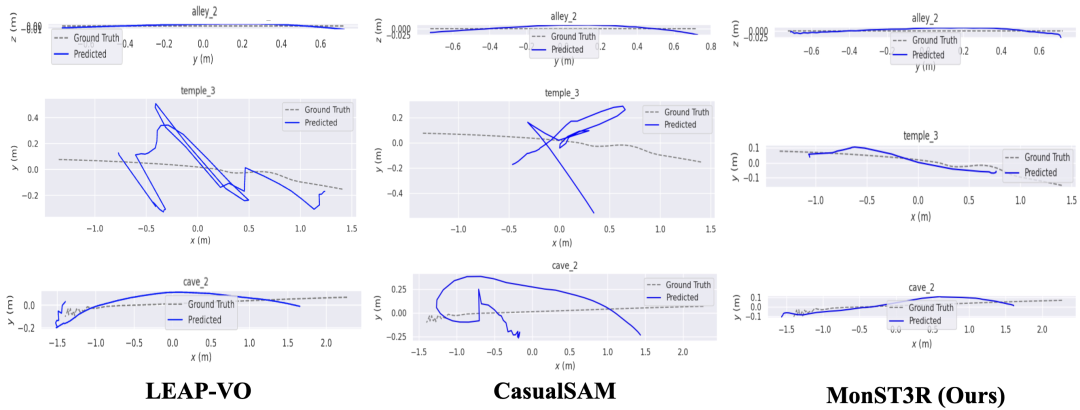
定性结果
从下图的定性结果看,MonST3R 在具有挑战性的场景中表现更具鲁棒性,例如 Sintel 中的 cave_2 和 temple_3。
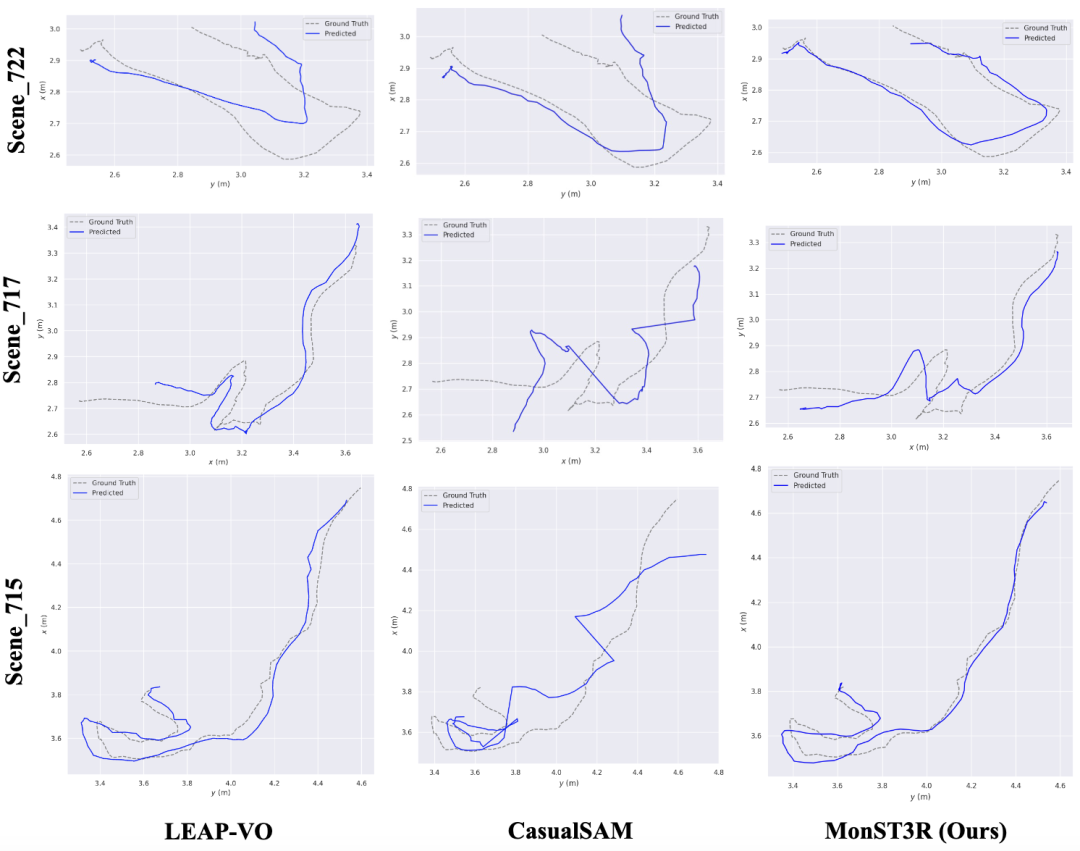
joint dense reconstruction and pose estimation(联合密集重建和位姿估计)
定性结果
从下图定性结果来看,MonST3R同时输出可靠的相机轨迹和动态场景的几何形状。


另外,作者在社交媒体上表示,该结果的速度比以前的方法快 10 倍。
Pairwise prediction(成对预测)
最后,还展示了前馈成对点图预测的结果,如下图。

第一行表明,即使经过微调,所提出方法仍然能够处理不断变化的相机内参。简言之就是可以可以处理动态焦点。
第二行和第三行表明,所提出方法能够处理“impossible”的对齐情况,即两帧图像几乎没有重叠,即使在有运动的情况下也是如此,而不像 DUSt3R 会根据前景物体进行错误对齐。简言之,可以在动态场景中进行“不可能匹配”。
第四行和第五行表明,除了使模型能够处理运动之外,微调还提高了模型表征大尺度场景的能力,而 DUSt3R 预测大尺度场景是平面的。简言之,可以更好地估计大场景中的几何图形。
4D 在线演示
特别值得一提的是,作者还提供了一个有趣的 4D 在线演示,可以探索 MonST3R 对各种动态场景的 4D 重建结果,感兴趣的小伙伴可以前来了解!
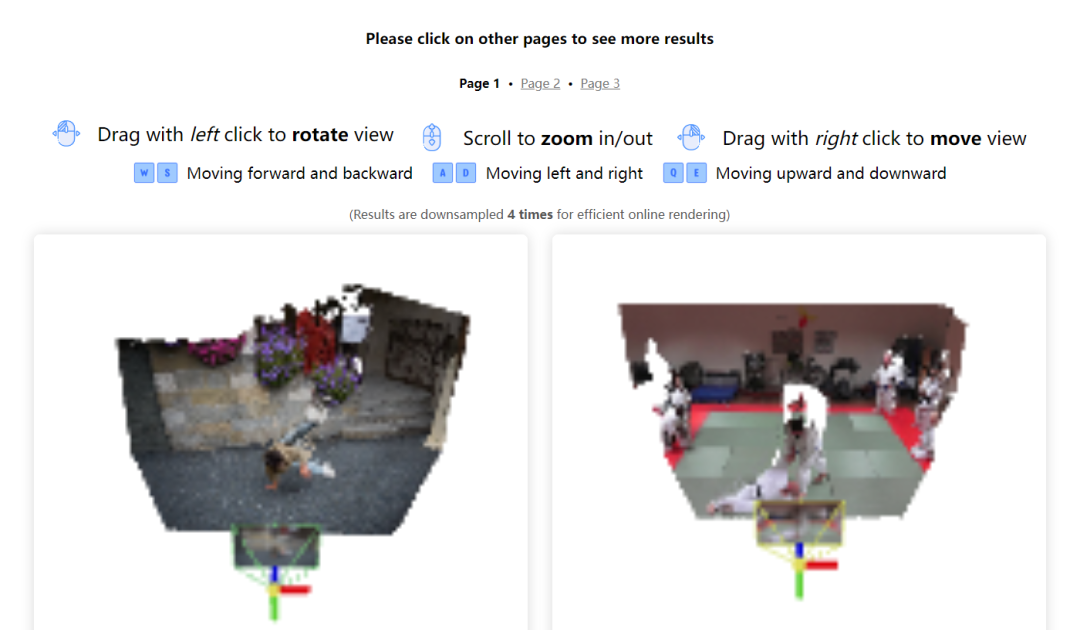
可交互结果展示:https://monst3r-project.github.io/page1.html
结论
MonST3R,是一种直接估算动态场景几何图形并提取相机姿态和视频深度等下游信息的简单方法。
MonST3R 利用每个时间步长的点图作为动态场景的强大表示法。尽管在相对较小的训练数据集上进行了微调,但 MonST3R 在下游任务上仍然取得了令人印象深刻的结果,甚至超过了之前最先进的特定技术。
最新 AI 进展报道
请联系:amos@52cv.net

END
加入「计算机视觉」交流群👇备注:CV


















 245
245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









