






关注公众号,发现CV技术之美
今天介绍我们在多模态大模型领域的一篇原创工作Reconstructive Visual Instruction Tuning,目前 Ross 已被 ICLR 2025 接收,相关代码已开源,有任何问题欢迎在 GitHub 提出。

arXiv Paper: https://arxiv.org/pdf/2410.09575
Project Page: https://haochen-wang409.github.io/ross/
GitHub Code: https://github.com/haochen-wang409/ross
Huggingface Checkpoint: https://huggingface.co/HaochenWang/ross-qwen2-7b
我们针对多模态大模型的视觉部分设计了重建原图形式的监督信号,该监督能够显著提升模型细粒度理解能力以及减轻幻觉。我们认为这是多模态大模型的 MAE 时刻,如何针对多模态大模型设计更好的 visual pre-text task 是后续研究的重点。
1. Motivation
在当今的多模态学习领域,多模态大模型尽管希望处理的是视觉数据,但其核心训练过程却几乎完全依赖于文本监督,即 “images --> CLIP --> LLM <== text supervision” 的架构。
这种做法缺乏对原始视觉信号的充分利用,模型的性能也很大程度上受限于被视觉表征的好坏。
为了突破这一瓶颈,我们提出了一种全新的方法——Reconstructive Visual Instruction Tuning (Ross)。
Ross 引入了视觉监督。它让大型多模态模型(LMMs)直接从输入图像中学习,通过重构图像来指导自身的优化过程。这种方式不仅充分利用了图像本身的丰富细节,还能够显著提升模型对细粒度视觉特征的理解能力。
2. Method
既然输入的图像本身就蕴含着大量的细节信息,为什么不直接利用它们来指导模型的学习呢?通过重构输入图像作为监督信号,我们鼓励模型保持对低级细节的关注,从而增强了其细粒度的理解能力,并减少了幻觉现象的发生。
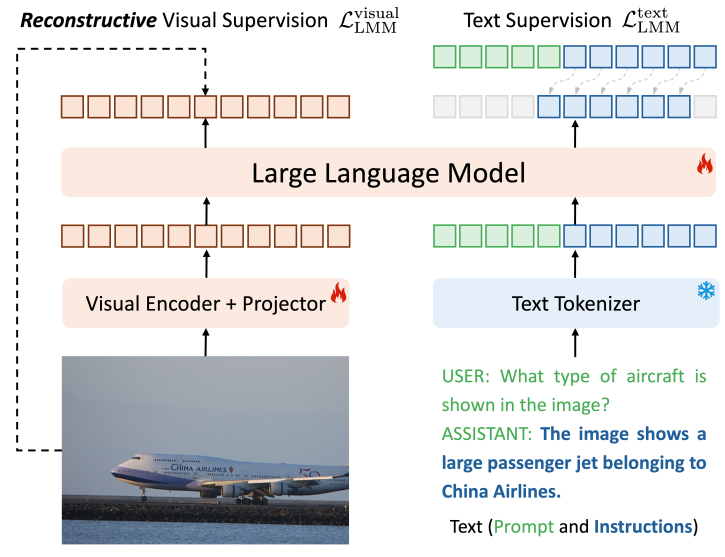
上图展示了 Ross 的 high-level idea。不同于传统的多模态大模型只利用了右半部分的 text supervision,Ross 引入了左半部分的 visual supervision。
在这个过程中,自然图像的空间冗余性,难以为 LLM 直接提供有意义的监督信号。为此,我们系统性地研究了 (1) 重建目标 (2) 重建损失,最终得到了一个巧妙的解决方案:采用去噪目标来重构隐特征,如下图所示。
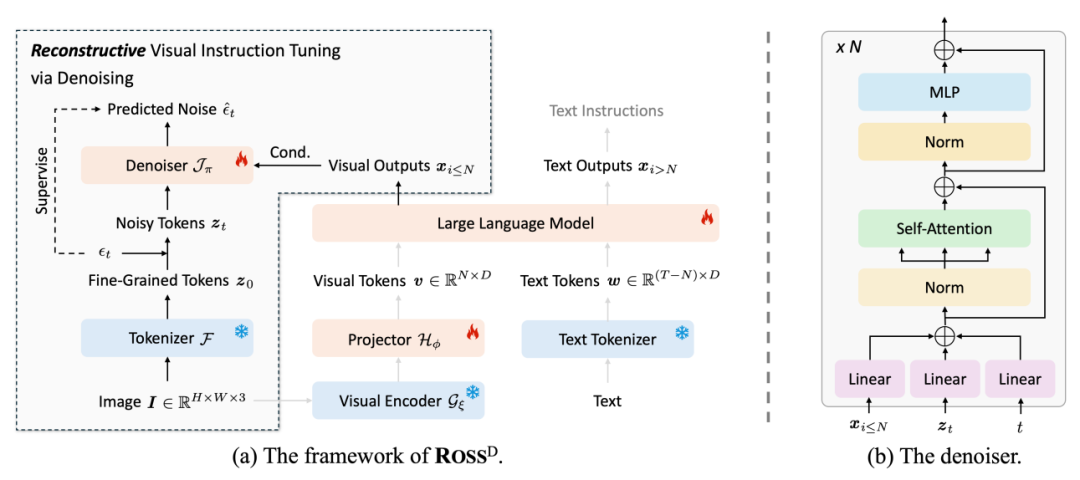
3. Experiments
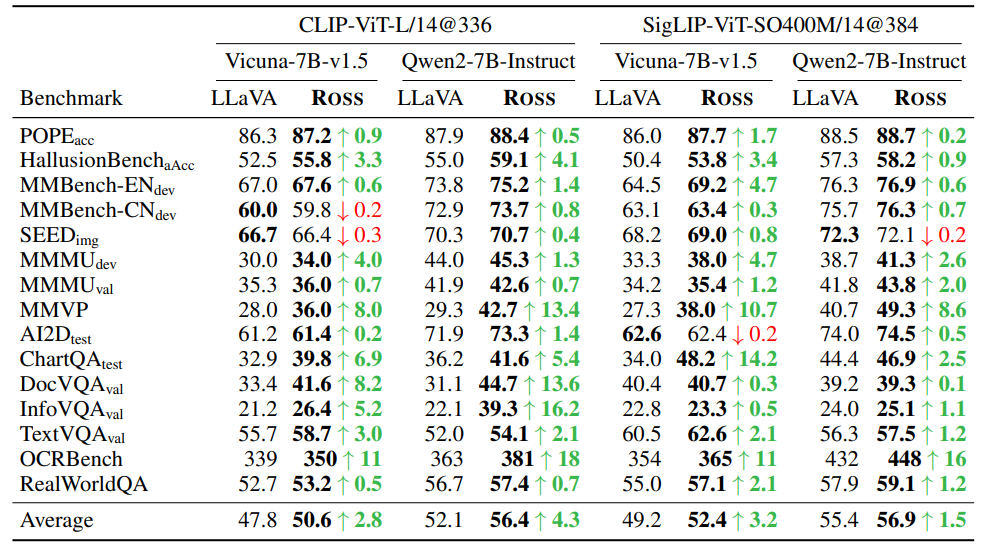
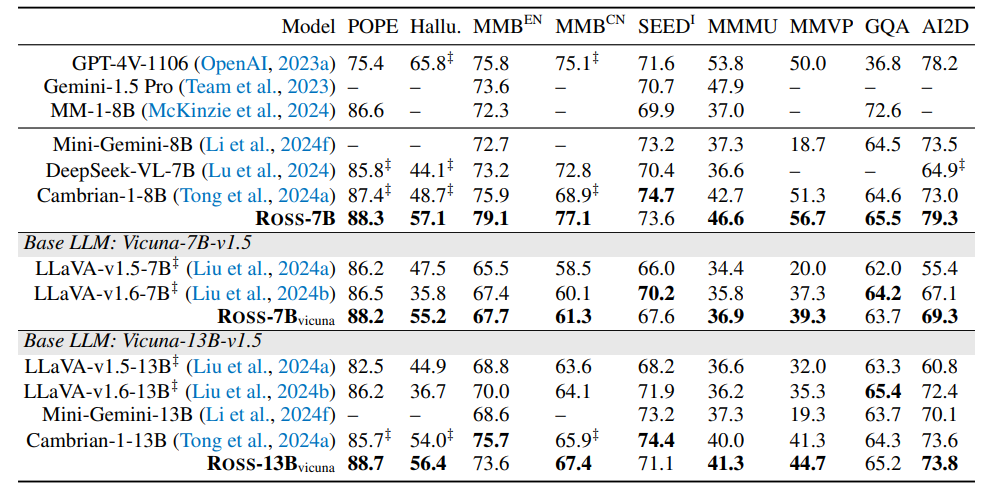
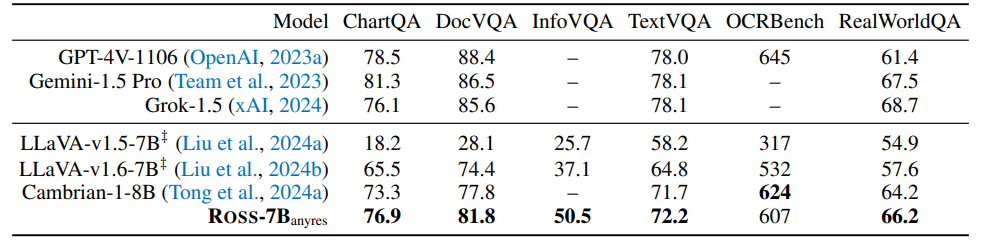
4. In-Depth Analysis
绝对的数字并不是最关键的,我们更应该关注为什么 Ross 这类视觉监督能 work。我们得出了以下的结论:
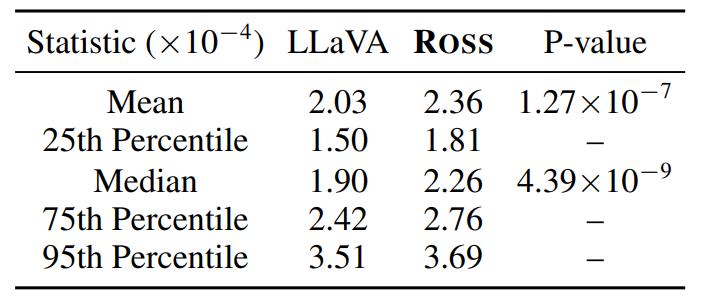
引入视觉监督能带来更高的 attention values,多模态大模型更加看图了
引入视觉监督能带来更合理的 attention map,多模态大模型更能关注到正确的区域

引入视觉监督能让模型的特征包含足够的细粒度信息,把 frozen Ross-7B 的 feature 作为 condition,仅将 denoiser 在 ImageNet-1K 上 fine-tune 5 个 epoch,就能重建出图!

其中,最后一点是我们认为最有趣的发现,该结果表明,image --> SigLIP --> Qwen2 之后得到的特征,通过 Ross 这样的训练后,竟然还能被映射回原始的 RGB pixel space。这说明 Ross 对于图像信息的压缩较少,保留了细粒度理解所需要的细节信息。
5. Discussion and Future Work
我们认为 Ross 的成功,是多模态大模型的 MAE 时刻,如何针对多模态大模型设计更好的 visual pre-text task 将是后续研究的重点,LMM 的范式不应该只是 text 端的 next-token-prediction!
当然,Ross 还有很多非常 straightforward 的拓展,例如拓展至生成领域,真正做到生成帮助理解。
最新 AI 进展报道
请联系:amos@52cv.net

END
欢迎加入「大模型」交流群👇备注:LLM


















 6183
6183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









