







End-to-End Object Detection with Transformers
Abstract
提出了一种将目标检测视为直接集预测问题的新方法。简化了检测管道,有效地消除了对许多手工设计组件的需求,如非极大值抑制和锚的生成。新框架的主要组成部分,Detection Transformer,是一个基于集合的全局损失,通过二分匹配和transformer的编码器-解码器体系结构强制进行唯一预测。给定一组固定的小范围学习对象query,DETR根据对象之间的关系和全局图像上下文直接并行输出最终的预测集。DETR的精度和运行时性能与高度优化的Faster RCNN基线在COCO对象检测数据集上表现一致。此外,DETR可以很容易地推广到全景分割。
1、Introduction

图1:DETR通过将普通CNN与transformer结构相结合,直接(并行)预测最终检测集。在训练期间,二分匹配使用地面真值框唯一地分配预测。不匹配的预测应产生“no object”(∅) 类别预测。
通过将目标检测视为一个直接集预测问题,我们简化了训练管道。我们采用了一种基于Transformer的编码器-解码器架构。transformers的自我关注机制明确地模拟了序列中元素之间的所有成对交互,使这些体系结构特别适合于集合预测的特定约束,例如消除重复预测。DETR一次预测所有对象,并使用集损失函数进行端到端训练,该函数在预测对象和ground truth之间执行二分匹配。
DETR通过丢弃多个手工设计的编码先验知识的组件(如锚和非极大值抑制),简化了检测管道。与大多数现有的检测方法不同,DETR不需要任何自定义层,因此可以在包含标准CNN和transformer类的任何框架中轻松复制
与以前大多数关于直接集预测的工作相比,DETR的主要特点是二分匹配Loss和Transformer与(非自回归)并行解码的结合。相比之下,以前的工作侧重于RNN的自回归解码。我们的匹配损失函数唯一地将预测分配给ground truth对象,并且对预测对象的排列保持不变,因此我们可以并行地运行它们。
2、Related Work
2.1 Set Prediction集预测
2.2 transformer和并行解码
2.3 object detection
3、DETR模型
在检测中,直接集预测有两个要素是必不可少的:
(1)集预测损失,强制预测和地面真值框之间的唯一匹配;
(2)(在一次过程中)预测一组对象并对其关系建模的结构。
3.1 目标检测集预测损失
DETR在通过解码器的一次过程中推断出一个固定大小的包括N个预测的集合,其中N被设置为显著大于图像中对象的数量。
训练的主要困难之一是根据gt对预测对象(类别、位置、大小)进行评分。我们的损失在预测和gt之间产生最佳的二分匹配,然后优化特定对象(边界框)的损失。
y是ground truth,yhat是N个预测,yhat比y多,所以用no object将y补充到N个
为了找到这两个集合之间的二分匹配,我们寻找一种排列,使下面的式子最小
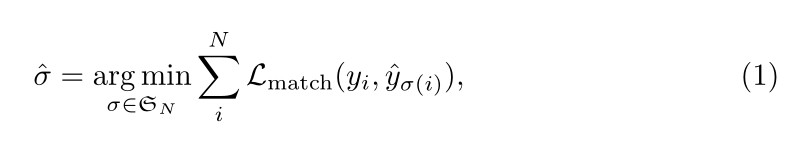
Lmatch是一个成对匹配成本,在ground truth yi和某一个预测结果yhat之间。这个yhat是排列后的顺序
如何得到这种排列呢?
L同时计算类别预测以及两个box之间的相似性。yi可以表示为(ci,bi),ci是类别标签,bi是box的位置。对hat值,ci使用概率 p σ ( i ) ( c i ) ^ \begin{array}{c} \hat{p_{\sigma(i) } (c_{i} )} \end{array} pσ(i)(ci)^,bi使用 b σ ( i ) ^ \begin{array}{c} \hat{b_{\sigma (i)} } \end{array} bσ(i)^,然后将Lmatch定义为
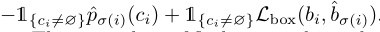
这种寻找匹配的过程与之前的检测器中用于将proposal或anchor匹配到ground truth的启发式分配规则的作用相同。主要的区别在于,我们需要找到一对一的匹配来进行无重复的直接集预测。
第二步是计算损失函数,即上一步匹配的所有对的匈牙利损失。我们对损耗的定义类似于普通物体探测器的损耗,即类别预测的负对数似然和后面定义的box损失的线性组合:
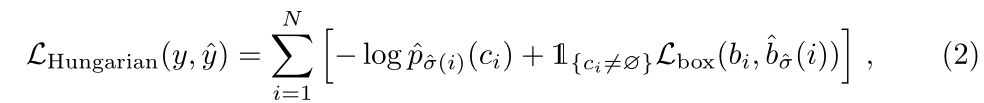
其中,σ是(1)中计算的最佳分配。在实践中,我们降低了yi为no object时对数项的权重,使这一项的cost成为一个常数。这类似于faster RCNN训练过程中下采样以平衡正负proposal。
Lbox使用了L1损失和广义IoU的线性组合
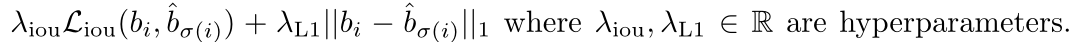
3.2 DETR结构
整个DETR架构非常简单,如图2所示。它包含三个主要组件,我们将在下面描述:用于提取紧凑特征表示的CNN主干、编码器-解码器转换器和用于进行最终检测预测的简单前馈网络(FFN)。

图2:DETR使用传统CNN主干来学习输入图像的2D表示。模型将其展平,并在将其传递到transformer编码器之前使用位置编码对其进行补充。然后,transformer解码器将少量固定数量的已学习位置嵌入(我们称之为对象查询)作为输入,并另外处理编码器输出。我们将解码器的每个输出嵌入传递给共享前馈网络(FFN),该网络预测检测(类和边界框)或“无对象”类。
主干
输入图片3H0W0,输出CHW,C=2048,H=H0/32,W=W0/32
Transformer 编码器
11卷积 输出dHW,压缩为dHW的特征图
每层编码器都由一个多头自注意力模块和一个前馈网络(FFN)组成
由于transformer架构是置换不变(没有空间位置关系)的,因此我们使用固定的位置编码对其进行补充,这些编码添加到每个注意层的输入中。
Transformer 解码器
解码器将N个形状为d的嵌入并行解码为输出嵌入
因为置换不变,所以加入object query进行补充,也添加到注意层的输入中
前馈网络(FFN)
三层包含ReLU的感知机,维度为d,和一个线性投影层和softmax
预测box的标准化中心坐标、高度和宽度,以及类别标签
辅助解码loss
在训练时,在每个解码器层之后添加预测FFN和匈牙利损耗
4、实验


表2:编码器尺寸的影响。每一行对应于一个模型,该模型具有不同数量的编码器层和固定数量的解码器层。随着编码器层的增加,性能逐渐提高。

DETR所使用的Transformer结构















 3447
3447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









