







本文如无特殊说明,所有文字均匹配的是文字下方的第一张图片。
接下来来介绍Teansformer的Decoder。
对于Decoder,如果把中间部分拿掉的话(下图画红圈部分),它和Encoder block就比较相似了。中间是一个Multi-Head Attention。之前有介绍过,这是Decoder和Encoder之间的Cross Attention。其中K、V来自于Encoder,而Q来自于Decoder。
另外Decoder和Encoder的不同还有,Decoder的Multi-Head Attention是Masked Multi-Head Attention。Masked表示不使用未来的信息,它只关注输出序列比较早的位置信息,这个“比较早”是指比当前位置早的位置。具体操作上是这么实现的:把未来的位置设置为负无穷大(-inf),在经过softmax之后,再变为0.
可以看出,Decoder是一个词一个词的输出的,因为当前的词不知道后续的词,所以要进行一个Mask。

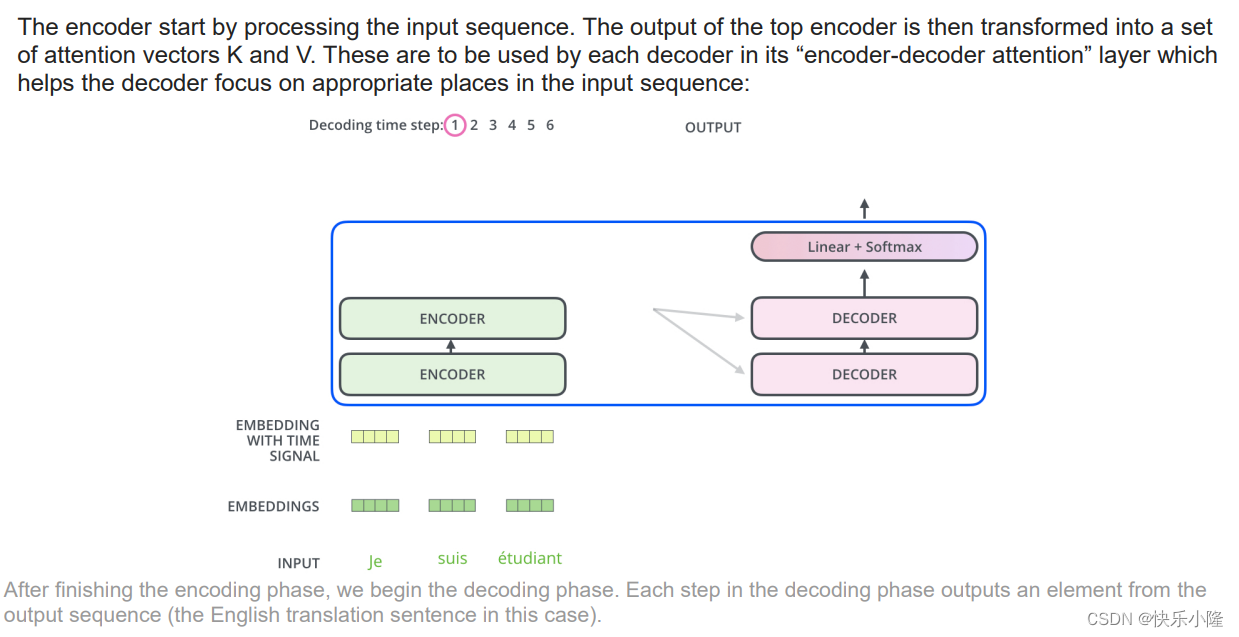
解码器端:编码器首先处理输入序列。然后将顶部编码器的输出转换为一组注意向量 K 和 V。这些将由每个解码器在其“编码器-解码器注意”层中使用,这有助于解码器将注意力集中在输入序列中的适当位置:
完成编码阶段后,我们开始解码阶段。解码阶段的每一步都从输出序列(本例中的英文翻译句子)中输出一个元素。
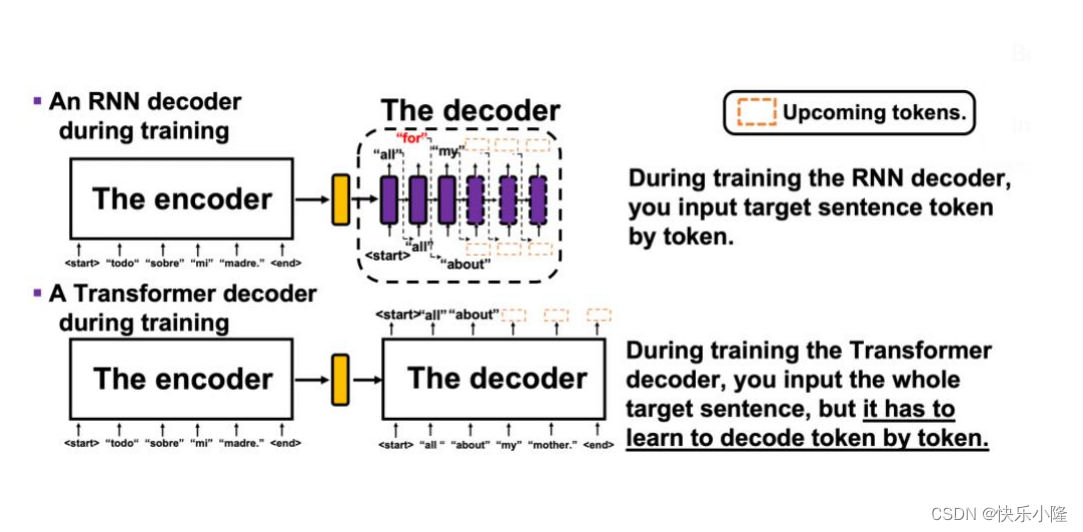
接下来比较一下RNN和Transformer。
RNN训练的时候,输入的target sentence 是token by token。Transformer训练的时候,可以输入整个target sentence,但是训练的时候,也必须学习token by token的译码。
接下来讲一下Transformer的Decoder中,是如何学习token by token的输出的。
我们可以把整个句子都交给Transformer进行训练,但是我们比如让Transformer一个词一个词的进行输出。
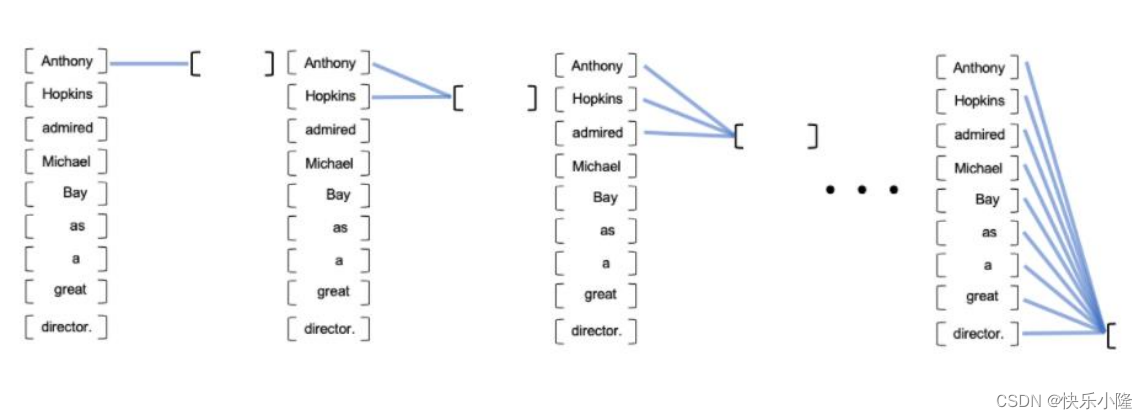
采用的方法就是Masked Multi-Head Attention。
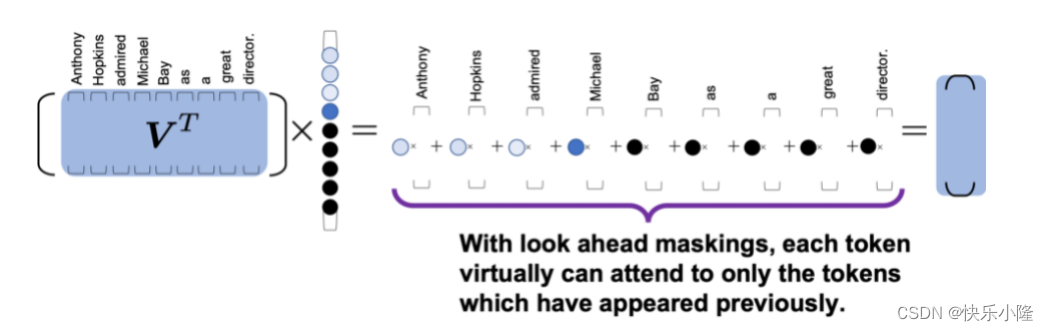
示意图上可以看到,有黑色的圆圈,黑色的圆圈代表要把后面的词遮蔽掉(mask掉)。比如第一个实验步骤,我们只考虑第一个token,第二个实验步骤,可以看两个token,但是后面依旧也是要遮蔽掉的。随着运算次数的增加,逐渐可以看到所有的token。
运算处理的时候可以用一个矩阵来表示,矩阵只有下三角有意义,上三角是被mask掉的。
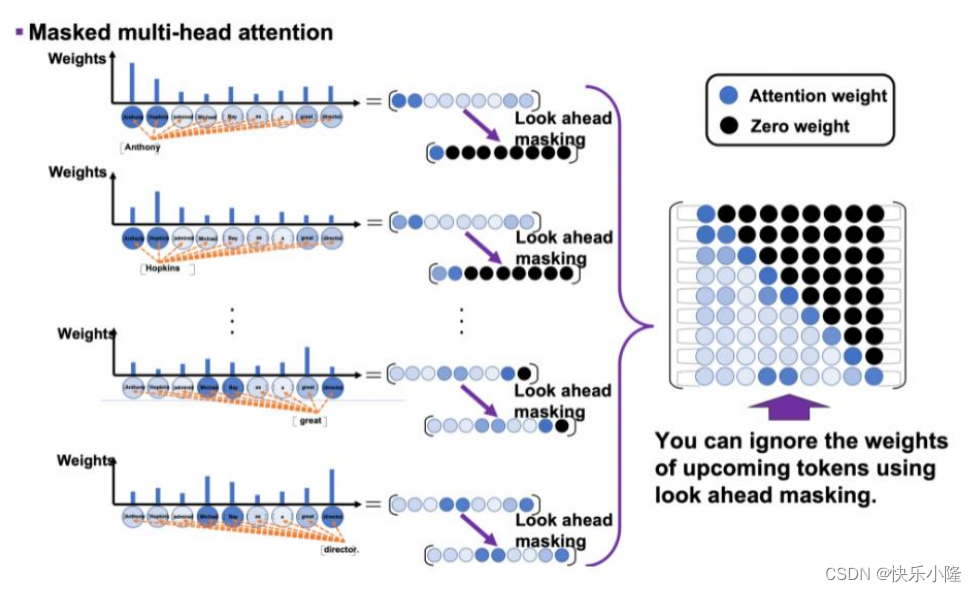
接下来进一步的讲解Masked Multi-Head Attention的过程。
如果在计算的过程中,把V进行了转置,那它就会变成上三角矩阵了。
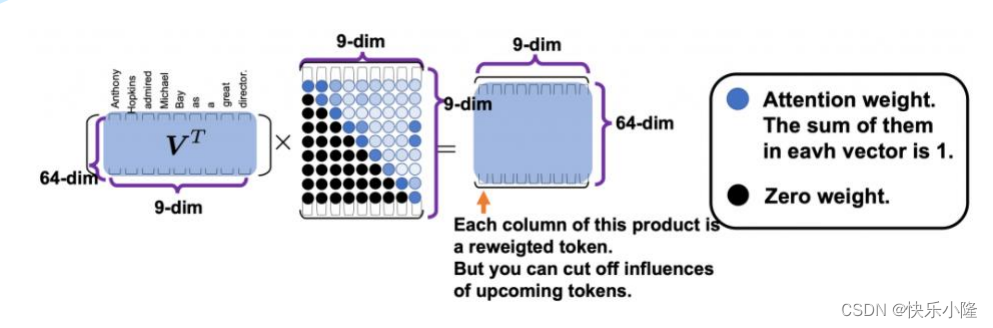
经过下图这样的矩阵运算可以看出,句子的每一个token在每一个时间步,只能看到前面的token,后面的token是被遮蔽掉的。所以这就是look ahead maskings。
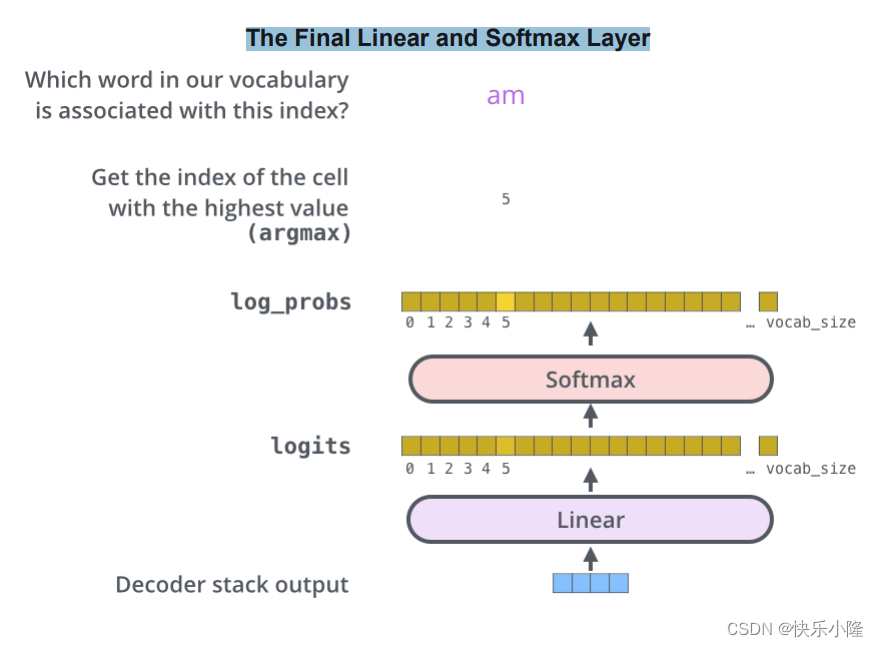
接下来我们来解释一下The Final Linear and Softmax Layer。即最后的Linear和Softmax Layer。
我们知道decoder输出之后,要首先经过一个Linear,再经过Softmax Layer。经过Linear层得到的是logits,这个logits值经过Softmax层变成概率值(log_probs),然后挑选一个最大的Softmax的值(即argmax)的索引。比如下图所展示的时间步挑出来最大的索引(index)是5,它所对应的词是am。
接下来总结一下训练。
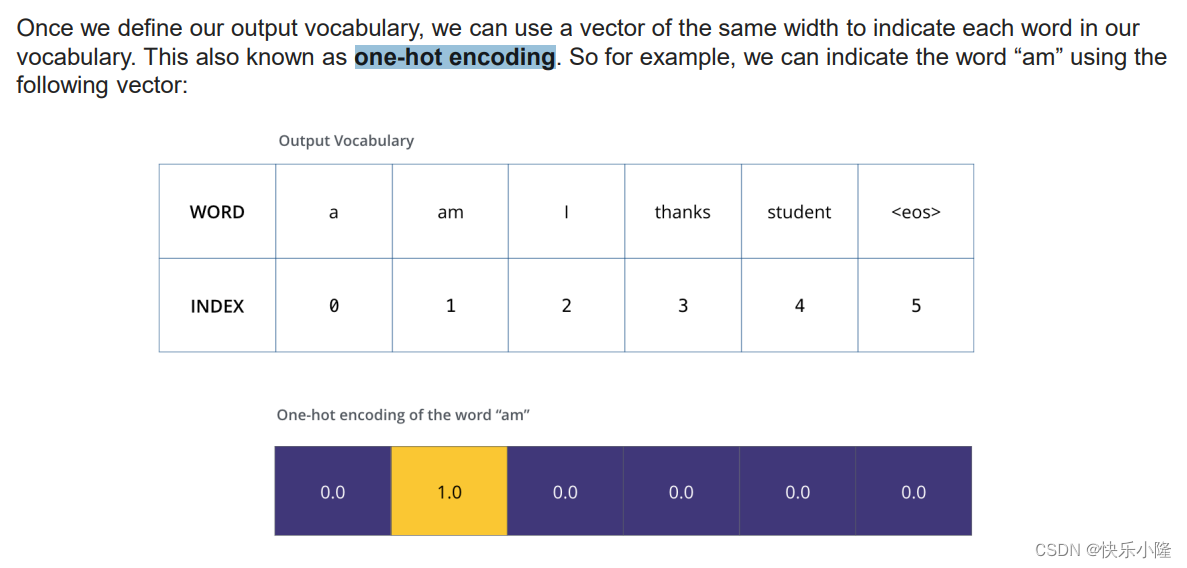
假设输出的词汇(output vocabulary)只包含6个词,就是下图那6个词<eos>表示‘end of sentence的缩写。从表可看到output vocabulary的word和index有相应的对应关系。

上图是做一个基础的介绍,接下来说一下具体的训练过程。
下面来解释一下什么叫one-hot encoding。
首先在有了一个Ground Truth之后,要对对应的词进行编码。
比如“am”,“am”的index是1。它的编码是一个矢量(下图的0.0| 1.0 | 0.0 | 0.0 | 0.0 | 0.0部分),可以看到,所有位置中只有第二个位置是1.0,其余都是0.0,这种就被称作为one-hot encoding。意思是:1.0那个位置比较hot
下面要进行训练了。
训练的时候,对于未训练的模型的输入,可能是比较随机的。那我们,正确的对某个位置呢它就有独特的编码 可以进行一个操作,使得每个位置都有正确的独特编码。
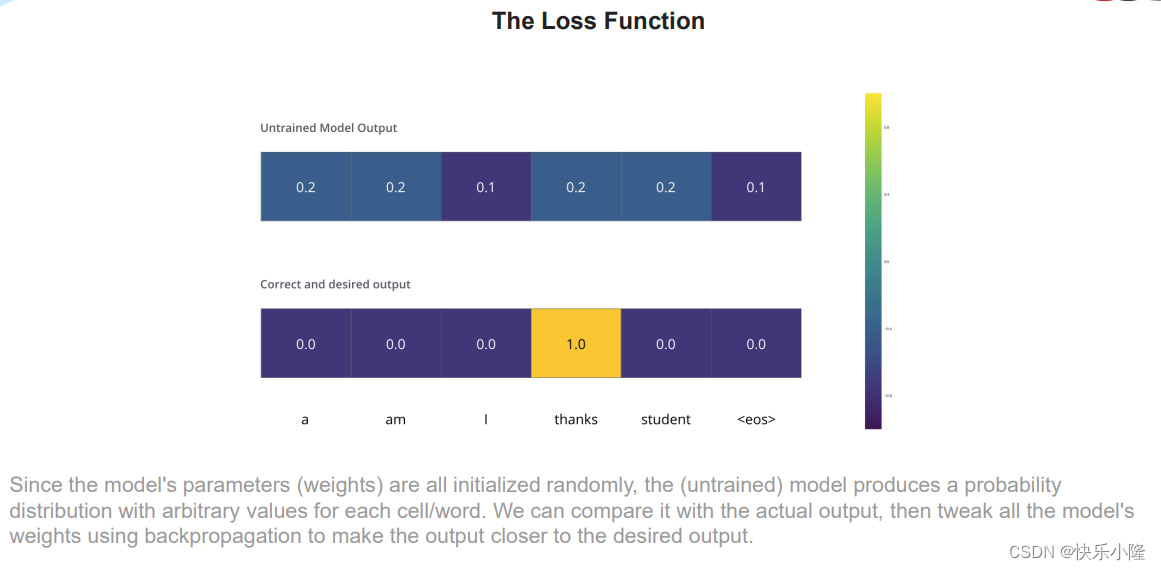
在训练的时候,对于不同的position,它的Ground Truth是有不同的独特编码的,比如,position1是i。
接下来是针对Transformer的训练部分讲解了,对于DETR的理解不听也行,然后我就没打字,视频是在第三节的9:00开始。
















 847
847











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









