







接下来正式介绍DETR的网络结构。
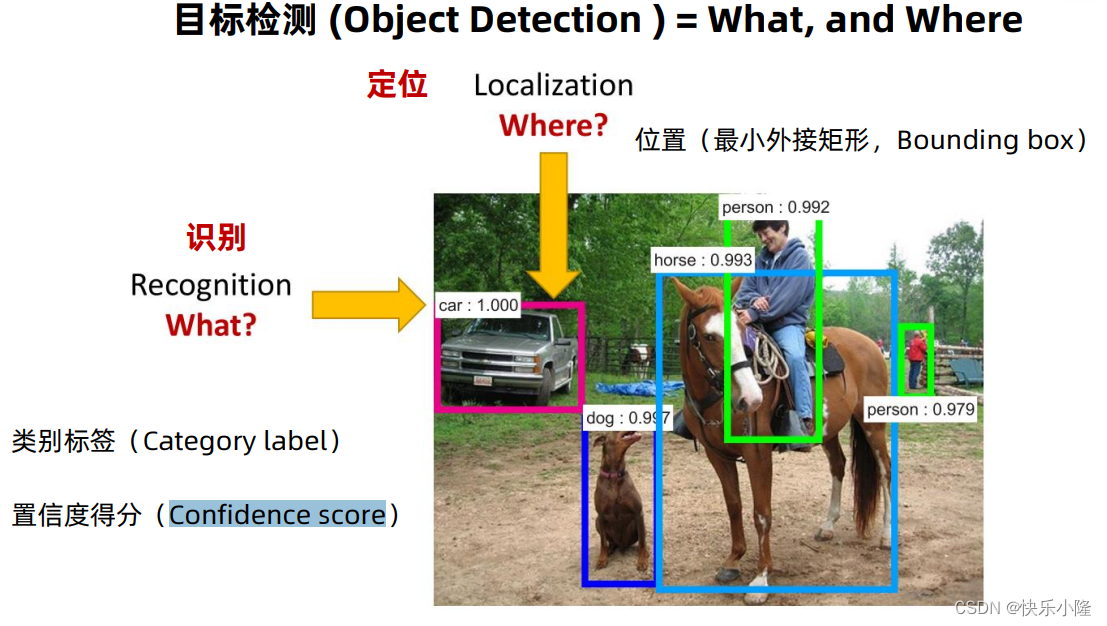
先来回顾一下目标检测,目标检测就是要定位和识别。定位就是要找到物体所在位置,即Bounding box,边界框,识别就是确定物体是什么,要给出物体标签(Category label)和置信度得分(Confidence score)。比如下图就给出了物体的类别、置信度标签和位置边界框。
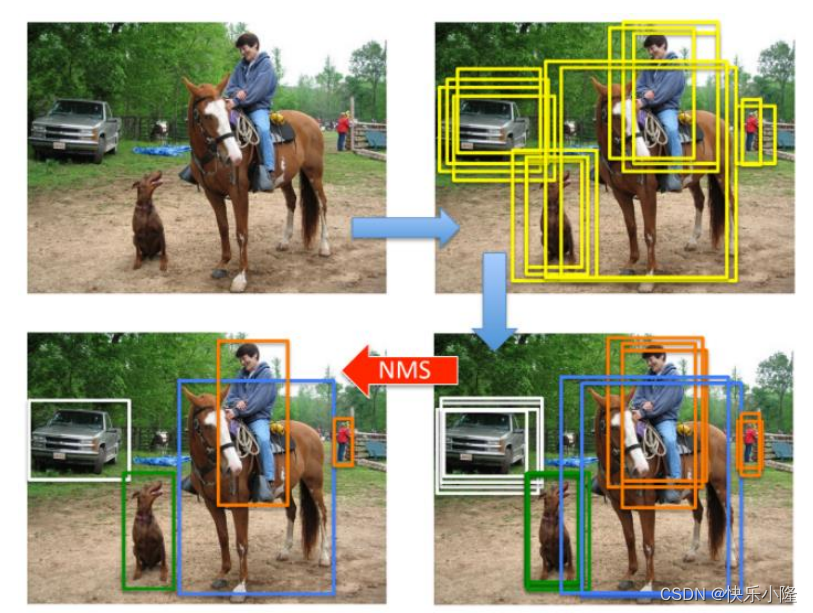
对于目标检测,卷积神经网络的方法,它会确定图片中物体所在的边界框,但是这样的边界框可能有多个,所有需要后处理,进行非极大抑制处理,然后得到目标边界框
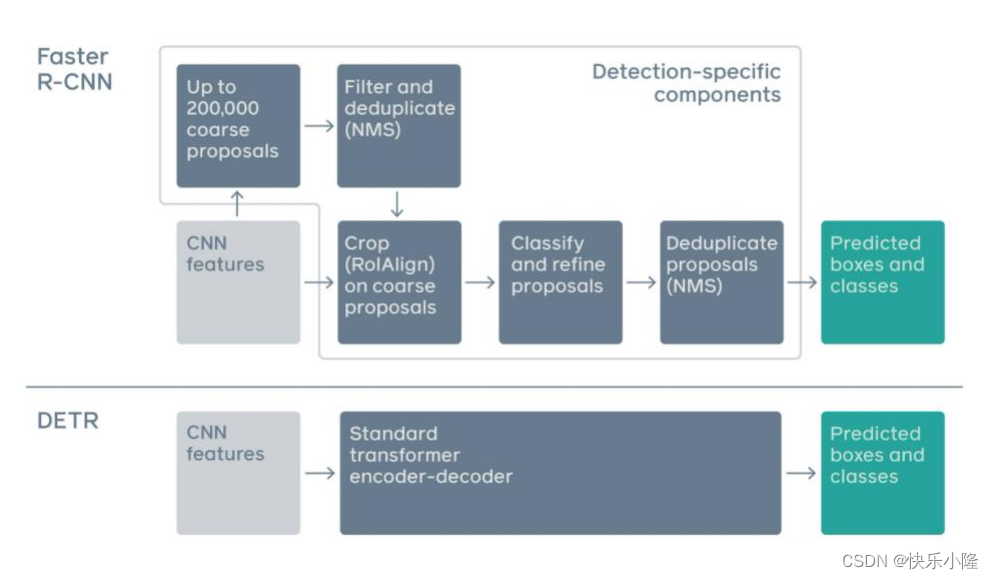
下图展示了基于Faster R-CNN和DETR的目标检测。
Faster R-CNN是一个两阶段目标检测,
第一阶段,它根据CNN得到目标特征,可以得到很多粗糙的建议框(proposals),
第二阶段它会做RolAlign操作,就是对这些proposals进行感兴趣区域的对准。对于proposals做二分类,分前景和背景,以及proposals位置的精细化。
然后再做NMS后处理,就是去除多余的proposals。
最终得到Predicted boxes and classes,从而确定物体的分类和位置。
对于DETR,可以看到,它简单了很多。
首先通过CNN得到物体的目标特征,然后送入标准的transformer进行处理,然后就可以得到Predicted boxes and classes。所以它不需要NMS的后处理
作者在论文中首先分析了现存方案的一些问题。事实上,作者认为,目标检测是关于预测边界框任务和物体标签类别任务的一个集合。当前的处理方案是一种非直接方案(indirect way),它会确定 proposals, anchors, or window centers这几种边界框比较大的集合,在这几种边界框的基础上做一个替代(surrogate)的回归和分类问题。
这种做法的性能就会受到后处理步骤(postprocessing steps)的影响而且也会收到anchors的影响。
作者那篇论文就是简化了pipelines,提出了直接集合预测方法(a direct set prediction approach ),这样做跳过了替代的任务,采用的是一种端到端的理念(end-to-end philosophy),这种理念在机器翻译和语音识别中都得到应用,但是还没用到目标识别上。填补了这个空白。

再探讨一下作者的技术方法思路。刚刚有提到,把目标检测问题作为一个直接的集合预测问题,从而避免采用非极大值抑制(non-maximum suppression),也不需要锚框产生的步骤(anchor generation)。
作者的框架主要是DETR,这个框架有两点要说明的
第一点,采用基于集合的总的损失函数(set-based global loss)来做二分匹配(bipartite matching),从而得到唯一的预测结果。
第二点,采用了transformer encoder-decoder 这样的架构。
在这个架构中,比较有特点的是可学习的目标查询(learned object queries),通过”可学习的目标查询“,可以找的目标和全局的图像上下文之间的关系,来直接并行输出最终预测的集合。

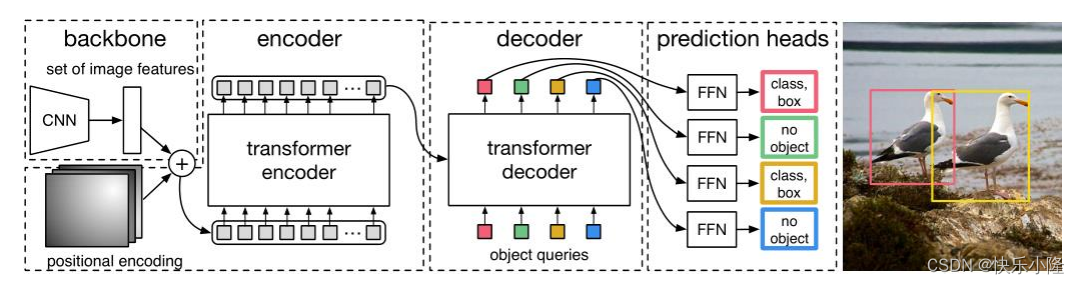
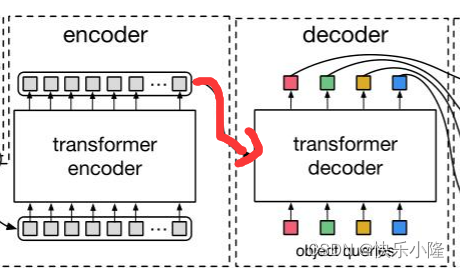
下图就是DETR的架构
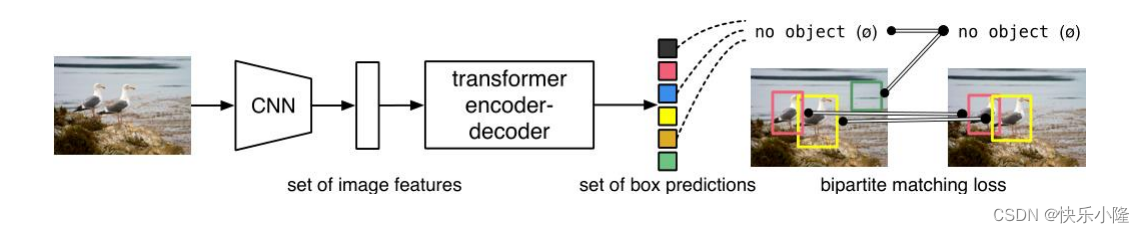
可以看到首先送入图片输入CNN骨干网得到图像特征
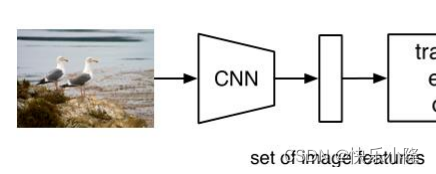
然后送入transformer encoder-decoder处理
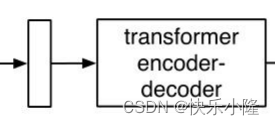
处理完得到一个预测集合
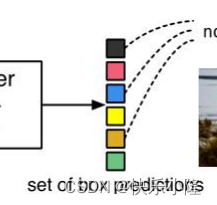
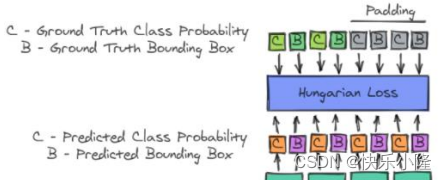
这个预测集合在训练的时候要和ground truth做匹配,匹配的时候就要采用bipartite matching loss。匹配的时候在上一步预测出来的集合的数目可能要比ground truth多,所以有一些box要匹配到no object。其实就是把他当作背景。总体来看DETR结合了CNN和transformer架构。
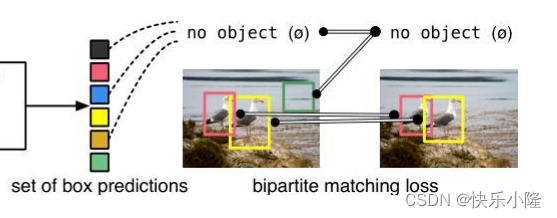
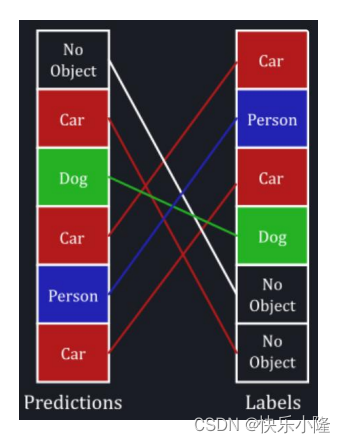
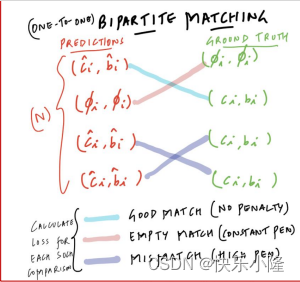
接下来讲一下bipartite matching。下图就是一个bipartite matching的例子。在匹配的时候,左边那列是预测的,右边那列是ground truth Labels。在匹配的时候bipartite matching是一对一的匹配,如果预测处理的目标比ground truth多,有一些预测就要分到No Object,比如左列的Car。
接下来仔细看一下DETR的架构。
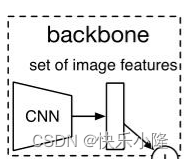
首先它有一个骨干网(backbone)CNN,比如:res-net。用这个骨干网来得到图像的特征。
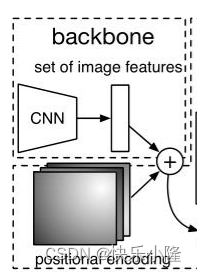
图像的特征要加上位置编码(positional encoding)
然后展平送入transformer encoder
之后把transformer encoder的输出送入transformer decoder进行处理
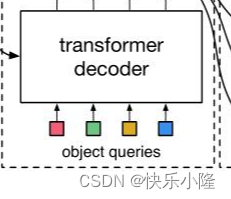
transformer decoder部分可以看到有一个object queries的输入。object queries是一个固定数目的可学习的位置嵌入,具体是数目可以是一个超参数,比如对COCO数据集作者是设为了100个。
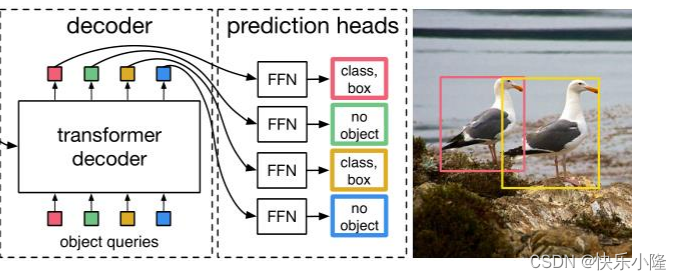
然后再把transformer decoder的输出送入prediction heads进行处理,prediction heads中有前馈神经网络FFN(feed forward network)来预测目标或者是no object,有目标的时候可以得到物体的类别和边界框。
接下来介绍一下DETR中的transformer的架构。
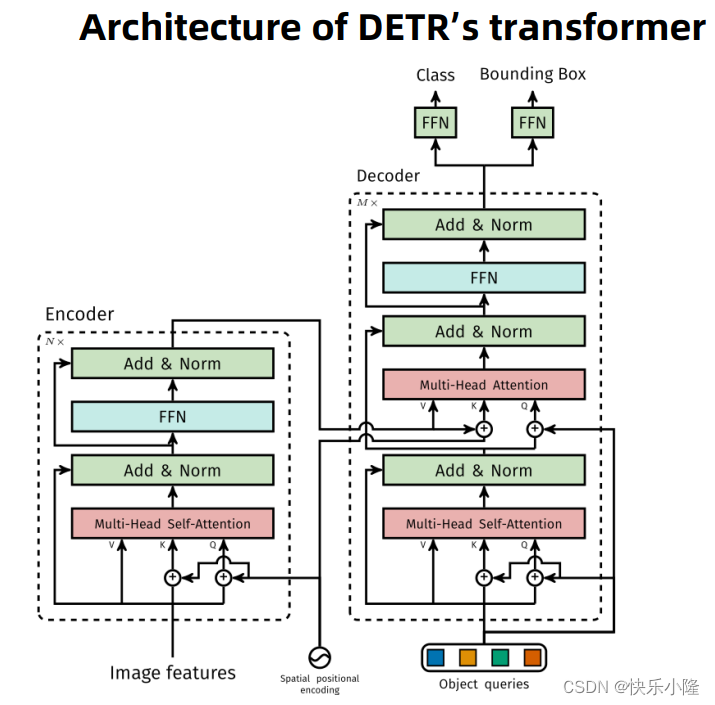
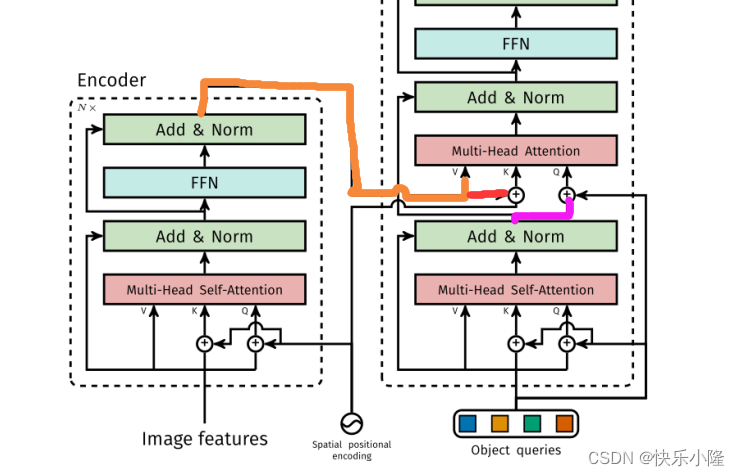
刚才有介绍到,通过骨干网得到图像特征(image features),然后再加上空间位置编码(Spatial positional encoding),只有K和Q是加空间位置编码的,V是不加空间位置编码的。可能作者认为value对于目标检测和位置信息无关。同样的在Decoder也是,只给K和Q加上了空间位置编码
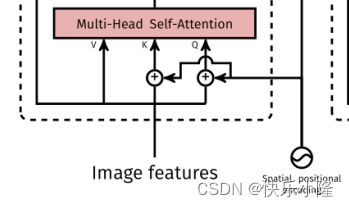
V、K和Q经过多头自注意力(Multi-Head Self-Attention),然后再经过FFN得到Encoder的输出。顺带一提,Multi-Head Self-Attention和FFN这两个子层还可以做Add&Norm残差链接。
像上述所说的结构可以堆叠N次
经过N次Encoder层的处理得到Encoder的输出送入Decoder
在Decoder中有Object queries。
对于Object queries要说明一下,它可以有两种初始化方法:
一种是初始化为全0的向量,然后加上空间位置编码;
另一种是初始化为随机值的向量,然后经过多头自注意力,然后再加上空间位置编码。
这两种初始化的方法在训练过程中Object queries都会进行更新。
经过多头自注意力之后,就来到了Multi-Head Attention,这是一个多头互注意力操作。
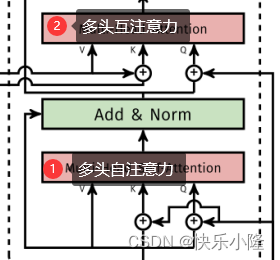
可以看到多头互注意力的V(下图橙色线)和K(下图红色线)来自于Encoder,Q(下图紫色线)来自于Decoder的多头自注意力。
VKQ三者进行完互注意力操作后再送入FFN进行处理。顺带一提,这三个子层都可以做残差链接和layernorm(Add&Norm)。
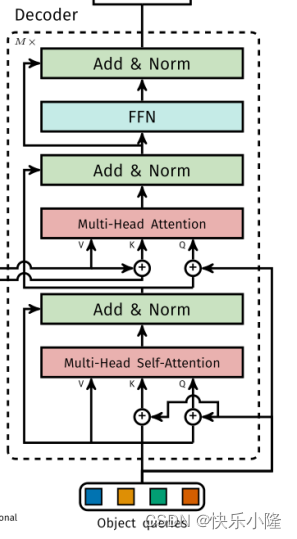
上述所说的Decoder整体的操作也可以堆叠多次
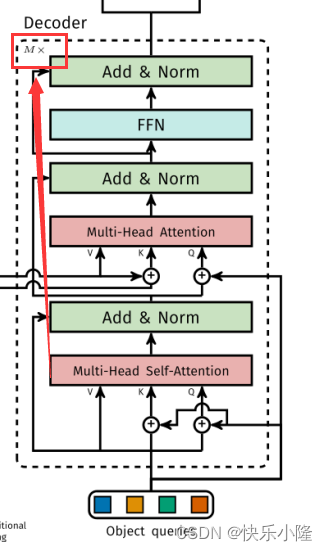
堆叠多次后的输出送入检测头,FFN对其进行分类和边界框的预测
下图也是对于DETR Pipeline的说明
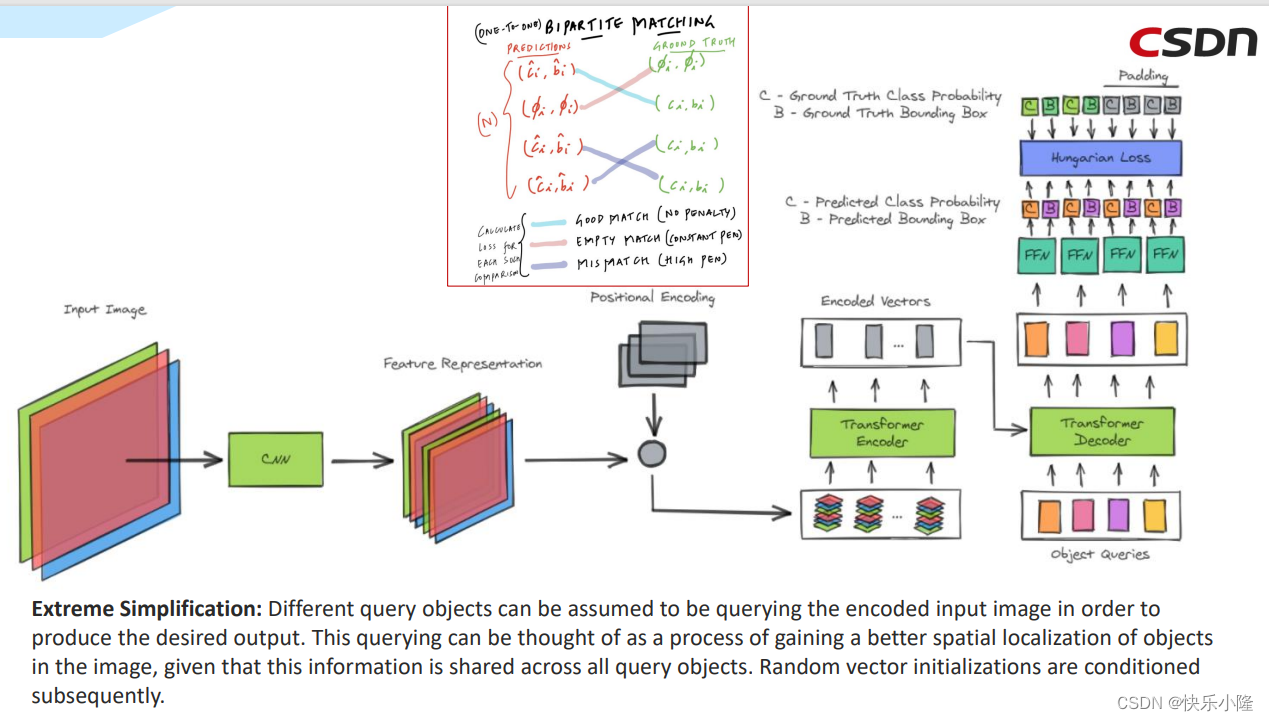
首先输入图片送入CNN骨干网进行图片特征提取。
然后再加上Positional Encoding
然后展平送入transformer encoder
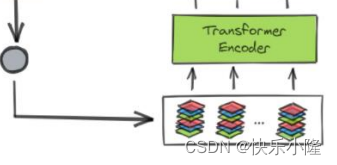
之后transformer encoder的输出送入transformer decoder
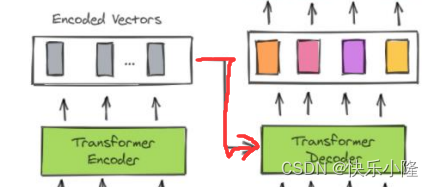
而且transformer decoder还接收object queries作为输入
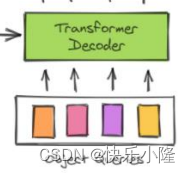
然后得到输出,送入FFN进行预测
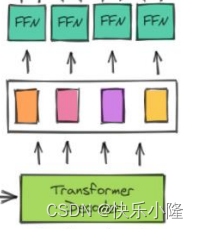
预测的时候要做二分的匹配,就是partite matching。partite matching的操作理解是,要把预测出来的目标和ground truth进行匹配。
匹配的时候有多种选择,比如下图的蓝色线条就是好的匹配(No penalty);红色就是空匹配,也就是No object;以及蓝紫色的匹配错误(mis Patch)。后两者都有比较大的损失惩罚(penalty)。经过训练我们希望predictions和Ground Truth有好的匹配,从而使损失最小
另外再解释一下object Queries的作用,作者提到,object Queries可以用作查询编码后的输入图像,来产生期望的输出。这个查询可以看作在图像上我们要得到更好的物体空间定位。object Queries的可解释性并不是很强,但是可以把它想象为和位置编码是相关联的

接下来用公式再描述一下DETR。首先是Backbone。

首先有一个输入的图像ximg,3代表三种颜色通道。
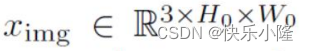
在经过CNN骨干网之后,图像初始的H0和W0的分辨率会降低,得到 lower-resolution activation map f。
作者的C=2048,特征图的高度H和宽度W是对于初始图象进行32倍的下采样。
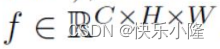
然后是Transformer encoder。

首先,encoder要做一个1×1的卷积来减少通道这一维度,把刚刚的C=2048变成更低的维度d,d可以取为256。这样经过1×1卷积后得到了一个新的特征图z0
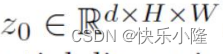
然后把z0展平为1维,变成一个序列输入到Transformer encoder。encoder的层包含了多头自注意力模块和FFN模块。刚刚有提到过,这样的encoder列可以堆叠多个。另外Transformer architecture是置换不变的,也就是说序列位置打乱的话,仍被视作相同序列。对图像而言,特征图的每一块在图像中的位置,对于目标检测来说是相关的,位置会对目标检测有影响,所以要加上位置编码(positional encodings)。加上之后作为每一个注意力层的输入。
接下来讲解Transformer decoder。
Transformer decoder基本上是按照Transformer 标准的框架来处理的。下面着重来讲解对于原框架的区别。
第一个区别是,在每一个decoder层,是对并行的N个目标进行解码,而标志的Transformer 是采用自回归模型(autoregressive model),这种自回归模型一个时间步只能预测序列中的一个元素。
另外,decoder也是置换不变量(permutation-invariant),所以它嵌入的新元素必须和之前的不同才能产生不同的结果,这些输入嵌入(input embeddings)新元素就是之前提到的object queries,object queries可以被理解为可学习的位置编码。
decoder也可以堆叠多次,来得到最终的输出。然后再送入FFN做边界框坐标以及类别标签的预测。另外在Transformer decoder中,它也采用了自注意力以及encoder和decoder之间的互注意力。

另外就是用于预测的FFNs。
下面有提到,它是一个三层的感知机,采用了ReLU激活函数和隐藏维度d。
它会预测归一化的中心坐标,以及边界框的高度和宽度。(这里的归一化是0和1之间,但最终还是要做尺度变换映射到原图的大小)。它还采用softmax函数来预测类别标签。
预测的时候,刚刚提到用于预测的object queries数目N会用到100,这可能比真正的目标数要多得多,而且这也是经常发生的情况,所以在匹配的时候就要有NO Object这样的类别标签,NO Object可以看作是背景这样的类别。



















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









