







目录
“Transformers and Parallel Decoding”
“Object detection set prediction loss”
Abstract
“The main ingredients of the new framework, called DEtection TRansformer or DETR, are a set-based global loss that forces unique predictions via bipartite matching, and a transformer encoder-decoder architecture. Given a fixed small set of learned object queries, DETR reasons about the relations of the objects and the global image context to directly output the final set of predictions in parallel.” [1]
end to end:不用生成anchor,不需要nms非极大抑制来去除多余的预测框的后处理。
主要提出概念:
- 一个基于集合的全局损失函数,通过二分匹配生成独一无二的框
- a transformer encoder-decoder architecture
Introduction
“the conjunction of the bipartite matching loss and transformers with (non-autoregressive) parallel decoding” [2] 二分匹配损耗和变压器与(非自回归)并行解码的结合
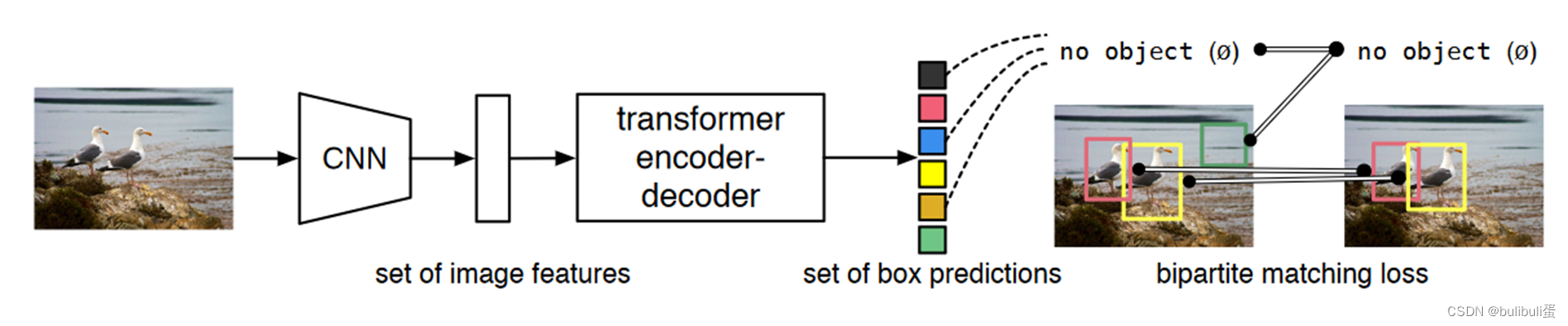 训练步骤:
训练步骤:
- 采用CNN提取特征
- 用 transformer encoder 学习全局特征
- 用 transformer decoder 生成预测框
- 用预测框和 ground truth 做匹配
- 计算loss
推理步骤:
前三点一致,最后设置置信度,保留“自信”的结果。
优点:对大物体检测效果不错
缺点:对小物体检测效果不咋地,训练很慢
Related Work
“Set Prediction” ——序列预测
“The usual solution is to design a loss based on the Hungarian algorithm [20], to find a bipartite matching between ground-truth and prediction. This enforces permutation-invariance, and guarantees that each target element has a unique match.
----
通常的解决方案是设计一个基于匈牙利算法的损失[ 20 ],以找到地面真相和预测之间的二分匹配。这实现了置换不变性,并保证每个目标元素都有唯一的匹配。” [3]
以往:RNN
本文:“use transformers with parallel decoding”
“Transformers and Parallel Decoding”
略
“Object detection”
“Two-stage detectors [37,5] predict boxes w.r.t. proposals, whereas single-stage methods make predictions w.r.t. anchors [23] or a grid of possible object centers [53,46].” [4] 两阶段检测器[ 37、5]预测框w . r . t .提案,而单阶段方法预测w . r . t .锚[ 23 ]或可能的对象中心网格[ 53、46]。
Two-stage:proposals,One-stage:anchors
“streamline the detection process by directly predicting the set of detections with absolute box prediction w.r.t. the input image”
Set-based loss:“Learnable NMS methods and relation networks”
Recurrent detectors:“object detection [43] and instance segmentation” ,but RNNS.
DETR MODEL
“Two ingredients are essential for direct set predictions in detection:
(1) a set prediction loss that forces unique matching between predicted and ground truth boxes;
(2) an architecture that predicts (in a single pass) a set of objects and models their relation.
We describe our architecture in detail in Figure 2”
“Object detection set prediction loss”
匈牙利算法:
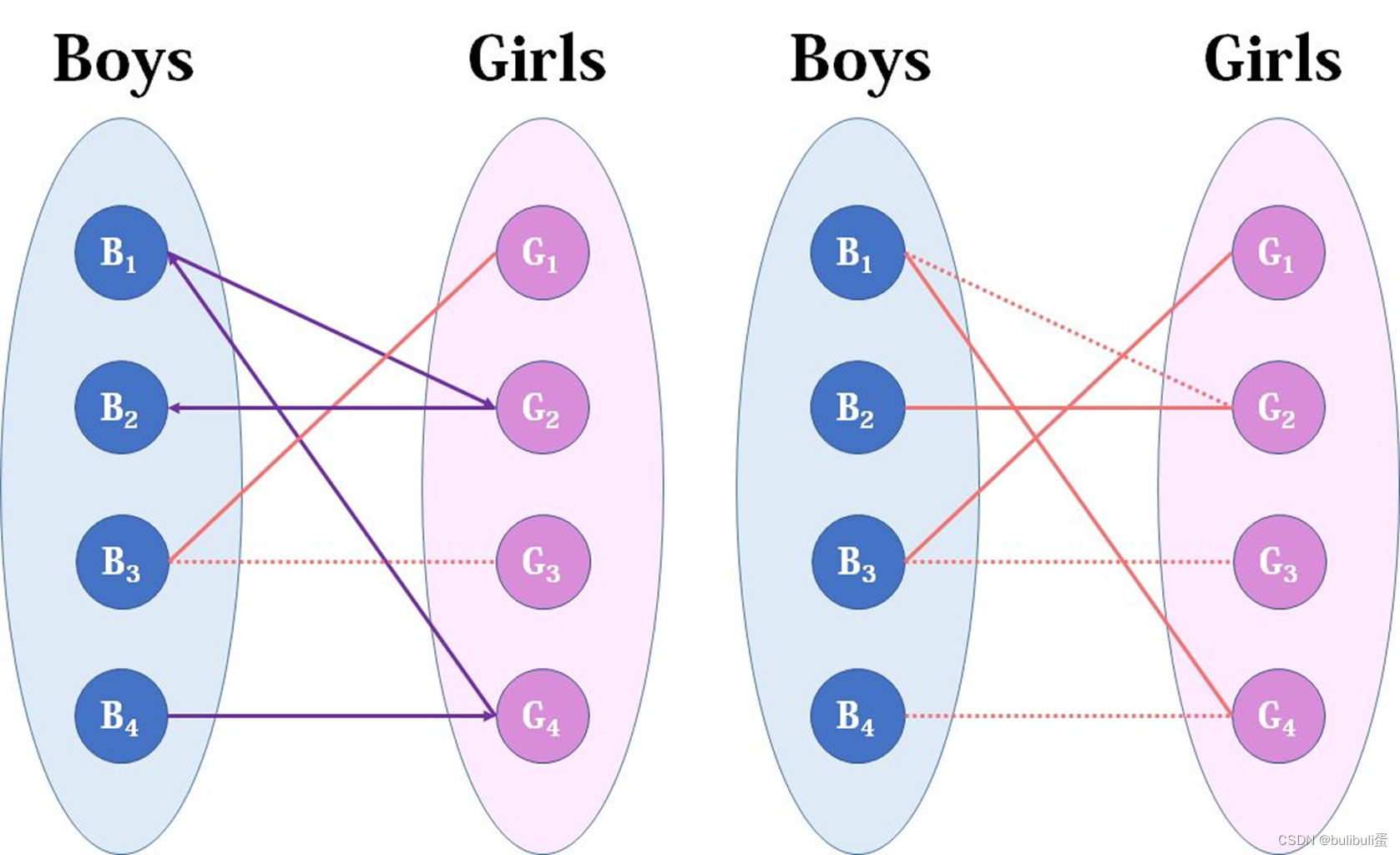
在计算loss的时候有个关键的前置步骤就是将预测结果和GT进行匹配,这里的GT类别是不包括背景的,未被匹配的预测结果就自动被归类为背景。
作者人为构造了一个新的物体类别 ϕ (表示没有物体)并加入image objects中,上面所说到的多出来的 N−m 个prediction embedding就会和 ϕ 类别配对。这样就可以将prediction boxes和image objects的配对看作两个等容量的集合的二分图匹配了。
只要定义好每对prediction box和image object匹配的cost,我们就能用匈牙利算法快速地找到使总cost最小的二分图匹配方案。
留个坑晚上画匈牙利算法

scipy:linear-sum-assignment
1.得到prediction boxes和image objects的最优二分图匹配
匈牙利算法:

cost计算方法:

2.根据最优二分图匹配计算set prediction loss
我们得到了prediction boxes和image objects之间的最优匹配。这里我们基于这个最优匹配,来计算set prediction loss,即评价Transformer生成这些prediction boxes的效果好坏。
和匈牙利算法几乎一致 。分类loss+出框loss
。分类loss+出框loss
“DETR architecture”
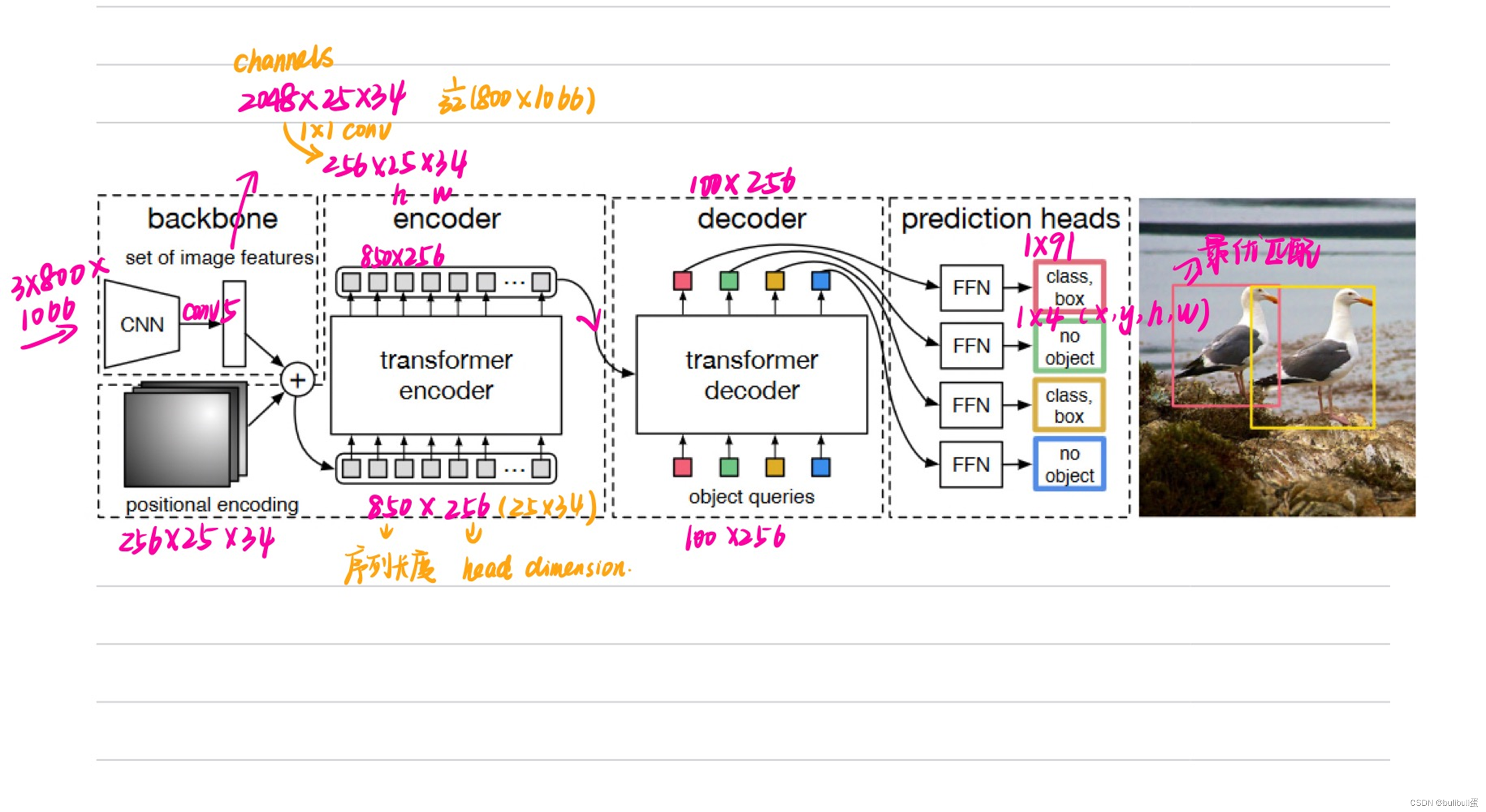
“a CNN backbone to extract a compact feature representation, an encoder-decoder transformer, and a simple feed forward network (FFN) that makes the final detection prediction.” [5] 一个CNN主干来提取紧凑的特征表示,一个编码器-解码器转换器,以及一个简单的前馈网络( FFN )来进行最终的检测预测。
1x1卷积:升降维

位置编码
“spatial positional encodings and output positional encodings (object queries)”
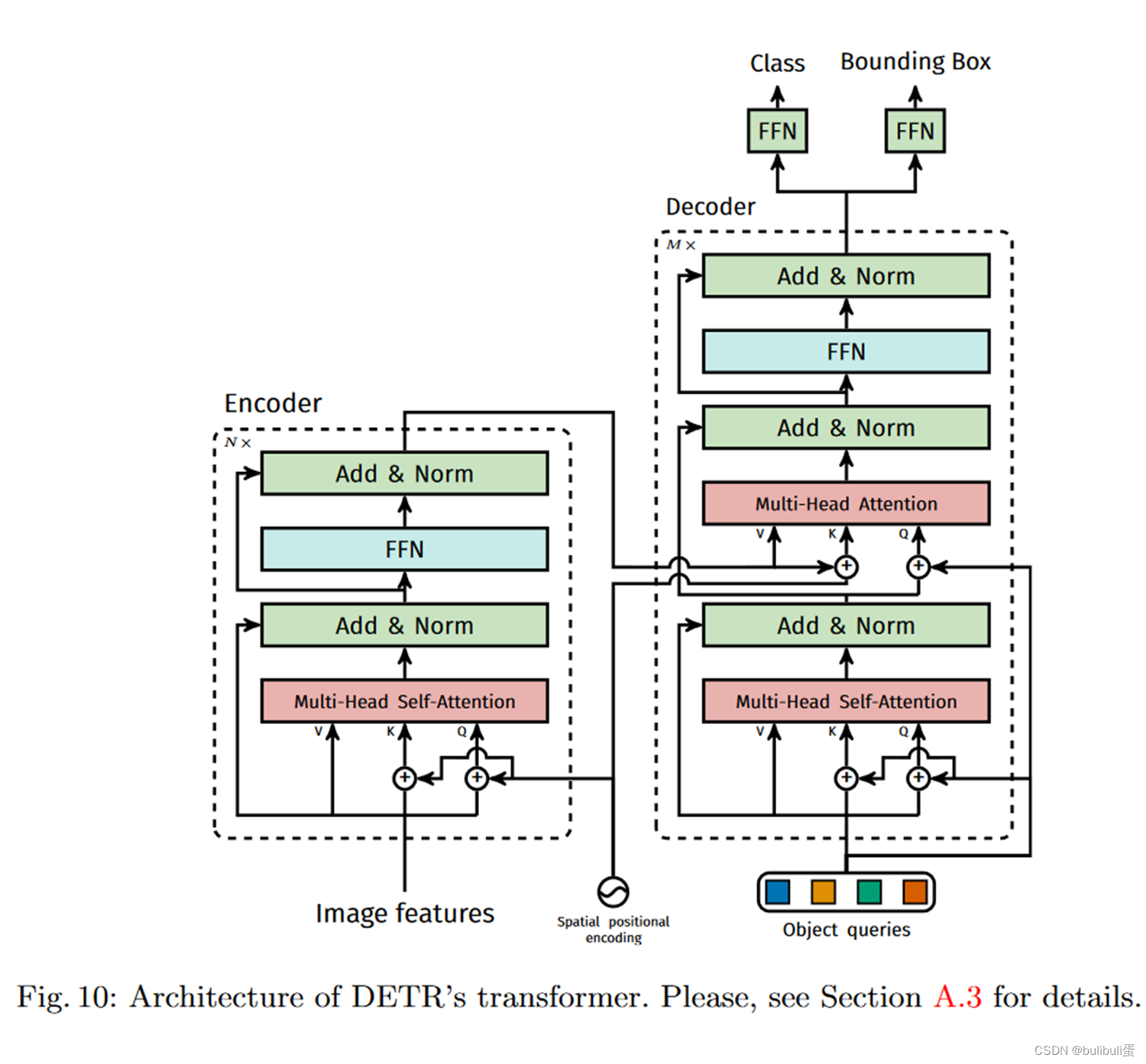
位置编码是被每一个 Multi-Head Self-Attention 前都加入了的,为了体现图像在 x 和 y 维度上的信息,作者的代码里分别计算了两个维度的 Positional Encoding,然后 Cat 到一起。
DETR 的 Decoder 也加了 Positional Encoding。这个思想其实也很自然。当作图像分类是,其实 class token 就一个,对应整个图片,那么自然无需 positional encoding,自己把整个图都占全了。但是在做目标检测时,可能会希望不同的 Object Query 是不是对应图像中不同的位置会好一些。那么按照这个思想,Object Query 自然就是 positional encodings,也就是我就是要查询这里的物体,你预测出来的就是对应的如果有物体的话就是它的类别和位置。
怎么加,在哪里加 positional encodings? Transformer Decoder 做得比 Encoder 还要狠,不仅 encoder 用的那个 position encodings,也要给每层的 key 加上;Decoder 每一层的 query 还是加了 positional encodings (Object Query) 的















 2443
2443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









