






The Future of Video Coding
Paper:https://www.nowpublishers.com/article/OpenAccessDownload/SIP-2021-0044
2022/6/26: 边看边翻译,刚好渡过周末的后半场。没翻译的明天接着来吧,也没多少了。不过下周重点要放在代码上了,周末可是有组会捏。
Abstract
本文总结了关于“视频的未来”的小组讨论由APSIPA美国地方分会于4月24日组织的,2021. 这个小组聚集了世界领先的视频编码专家来讨论和辩论这个热门话题。演讲嘉宾是来自不同视频编码领域的领军人物,包括视频编码标准、视觉质量、深度学习方法、屏幕内容编码、强化学习、速率控制、机器视频编码等等。讨论小组讨论了与视频编码相关的不同未来问题,包括但不限于未来5年的新兴领域、深度基于编码的趋势和作用、视频编码的发展趋势、图像质量评估的影响、学术界的角色,研究生的建议等等。小组成员的观点要点用斜体字突出。
1. Introduction
【Nam】 近年来,视频编码技术和系统的研究和开发取得了重大进展。随着2020年7月最新的通用视频编码(VVC)标准的标准化[8,9],专家们开始思考下一个标准会是什么,它可以在VVC/H.266之外获得类似的编码效率增益。另一方面,深度学习工具近年来受到了广泛的关注,包括将其用于辅助传统的视频编码,并在视频编码中取代传统的混合编码模型[30,31]。然而,这些工具具有非常高的计算复杂性和高功耗,这使得它们目前在许多情况下不切实际。克服这些挑战是一个重要的研究方向。在视觉质量方面,已经有很多人建议开发超越传统计算模型的模型,如峰值信噪比(PSNR),甚至多尺度结构相似性(MS-SSIM)度量。是否存在一种普遍接受的计算、感知或视觉注意模型来描述视觉质量? 最后,有许多来自学术界的参与者,许多人想知道学术界可以发挥什么关键作用,以及我们对有兴趣从事视频编码职业的研究生有什么建议。面对如此多的挑战,视频编码研究的未来仍然是光明的。
2021年4月24日,APSIPA美国当地分会召集了世界顶尖专家,就“视频编码的未来”展开辩论和讨论。专家组成员均为视频编码领域的顶尖专家。鉴于我们的出席人数打破了历史记录,讨论也涉及了很多话题,我们设想会有很多人对这个主题感兴趣,很多人可能没有机会参与,因此我们撰写了这篇总结专家意见的文章,专家小组的成员是本文的作者。我们的小组讨论基于五个问题。(1)您认为未来5年视频编码领域的热门新兴领域会是什么?
(2)深度编码是否会成为视频编码的主要趋势?是的,或没有?为什么?
(3)视觉质量评价是当前学术界的研究热点。已发表多篇论文。这种努力会对视频编码标准化产生真正的影响吗?
(4)在新一代视频编码技术(或标准)的发展中,学术界是否有一席之地?
(5)对于想从事视频编码研究的研究生,您有什么建议?
最后,为观众分配了提问时间,并与小组进行互动。结论部分对主要观点进行了总结。
2. Hot Emerging Video Coding Areas
论坛上的第一个问题是“你认为未来5年视频编码领域的热门新兴领域会是什么?”
2.1 Emerging Technology and Applications
2.1.1 Dual-track Approach
【Gary】 现在我们有一个双轨的方法。除了研究传统方法,专家们还在研究使用神经网络。沉浸式应用也是一个很大的领域,比如六自由度视频(甚至三自由度视频也是一个挑战)。快速流
“贴图”区域取决于一个人在场景中的位置。即使是在所谓的经典风格的普通编码技术,我们仍然在进步。在现在的JVET中,我们已经显示出比2020年7月的VVC版本1标准增加了13-14%。然而,复杂性的增加仍然是一个挑战。应用空间也在增长,从广播到流媒体再到移动,8K视频现在已经在消费级应用中,HDR和高帧率也在应用中。
2.1.2 Motivation from Emerging Applications
【Shan】 新技术的出现通常是由新兴应用[49]推动的。例如,开发了屏幕内容编码工具[48],并将其用于涉及计算机生成内容的应用程序,如屏幕共享和视频会议,以提高压缩性能和节省带宽。在新冠肺炎疫情期间,视频会议已成为我们日常生活的重要组成部分,帮助许多人远程学习和工作。目前,几乎所有广泛使用的视频通信产品和应用都采用了屏幕内容工具。展望未来,我们预计容量视频、虚拟现实、云游戏和低功耗边缘计算将有很高的需求。最近引起关注的另一个新兴领域是机器视频编码。机器视觉任务,如目标检测、分割和跟踪,已经在智能交通、智慧城市等许多应用中得到了应用。机器消耗的视频量正在迅速增加,因此,为机器和机器视觉任务压缩视频就变得很重要。MPEG于2019年创建了一个名为VCM(机器视频编码)的特设小组,并于2021年1月发布了一份证据呼吁[13]。
2.2 Deep Learning Approaches
【Wen-Hsiao】 目前有三个新兴领域与基于深度的方法有关:(1)深度学习(DL)辅助压缩-在不改变编解码器的情况下增强传统编解码器;(2)基于深度学习的压缩——利用神经网络作为压缩系统的主干;(3)混合系统-通过将基于DL的工具或增强层合并到传统编解码器。
2.2.1 DL-assisted Compression
【Wen-Hsiao】 在dl辅助方法中,可以使用神经网络对输入视频进行预处理,以在不改变编解码器的情况下对传统编解码器进行重新利用。例如,可以对输入视频进行预处理,使压缩后的解码视频在MS-SSIM中显示出比传统的PSNR或MSE更好的结果(见图1a)。同样,可以对其进行预处理,使解码后的视频适合于视觉任务,例如机器[24]的视频编码。另一种方法是在预处理和/或后处理[28]中使用神经网络。在预处理步骤中,神经网络在输入图像中嵌入有用的信息,这些信息可以在后处理步骤中从解码图像中提取出来,以更好地达到提高质量、节省速率或使解码图像/视频适应视觉任务的目的(见图1b)。
我们还可以将强化学习应用于编码器控制任务[10,16,17,42]。一个例子就是码率控制。我们有一个基于神经网络的代理,它与传统的编解码器交互以学习控制它(见图1c)。值得注意的是,[42]的工作为机器提供了一个视频编码的例子,它将相同的思想应用于训练一个代理,为计算机视觉任务优化位分配。另一个领域是将轻量级神经网络应用于快速模式决策等任务[25,34,40,47]。
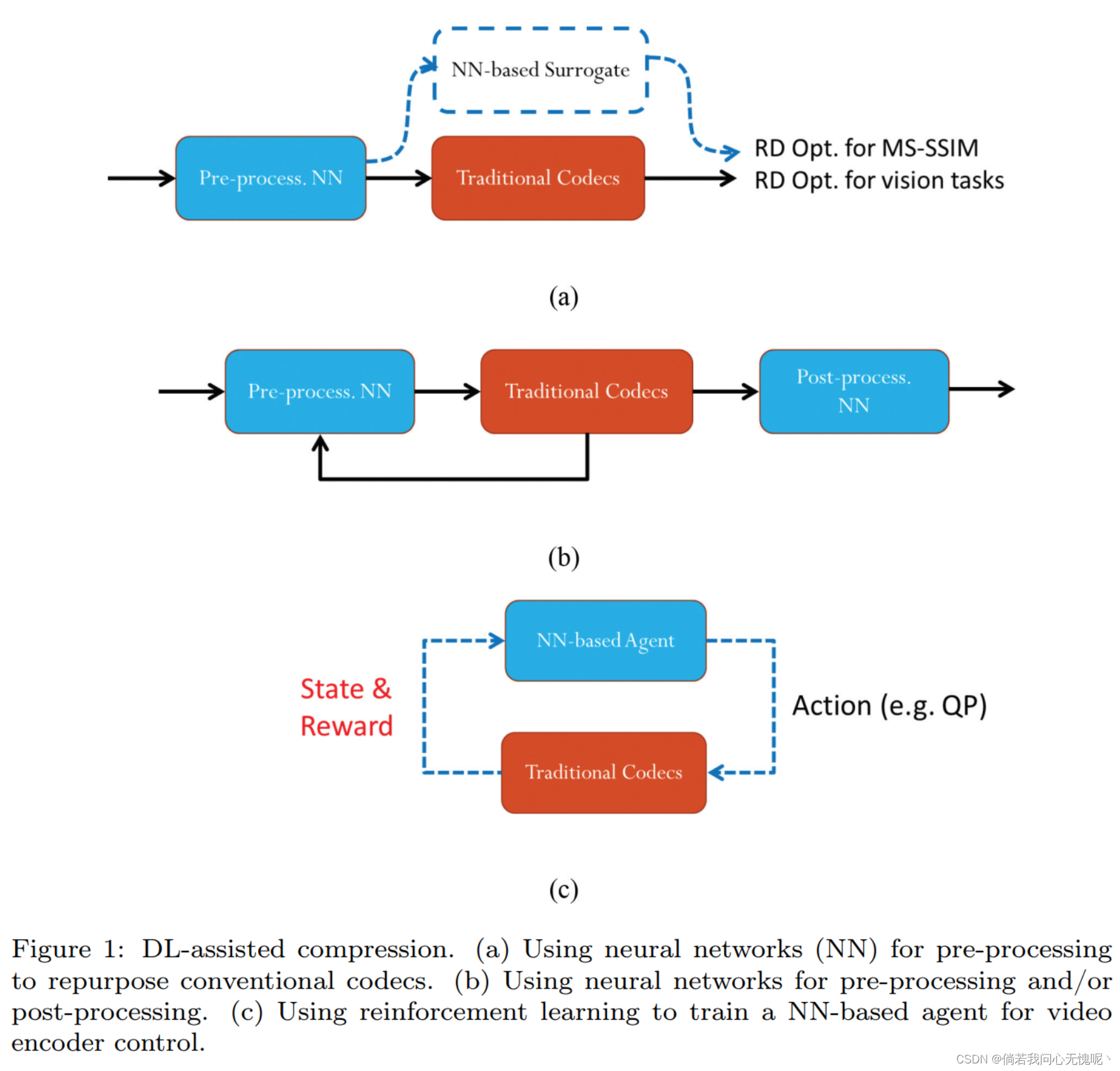
2.2.2 DL-based End-to-end Compression
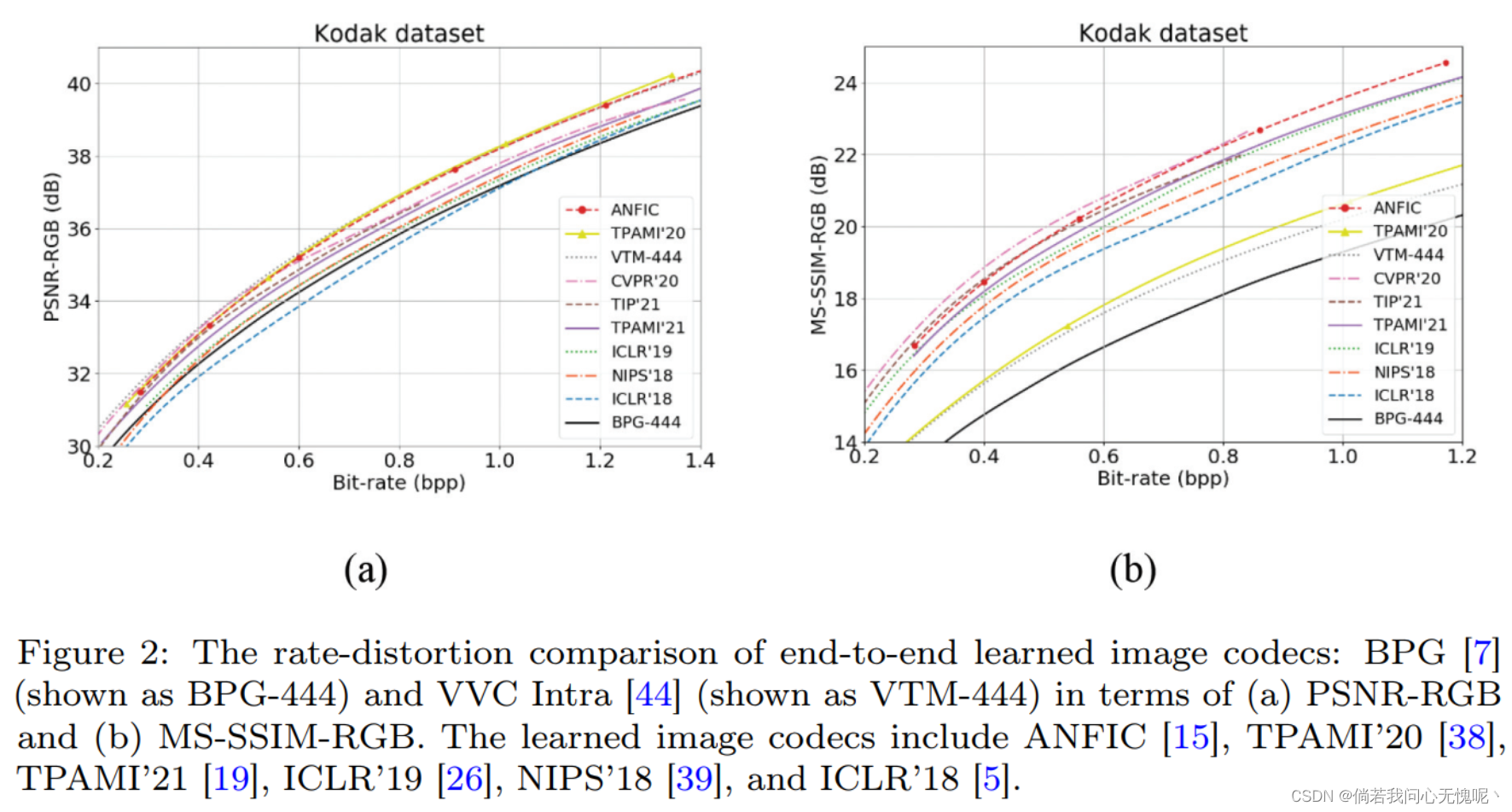
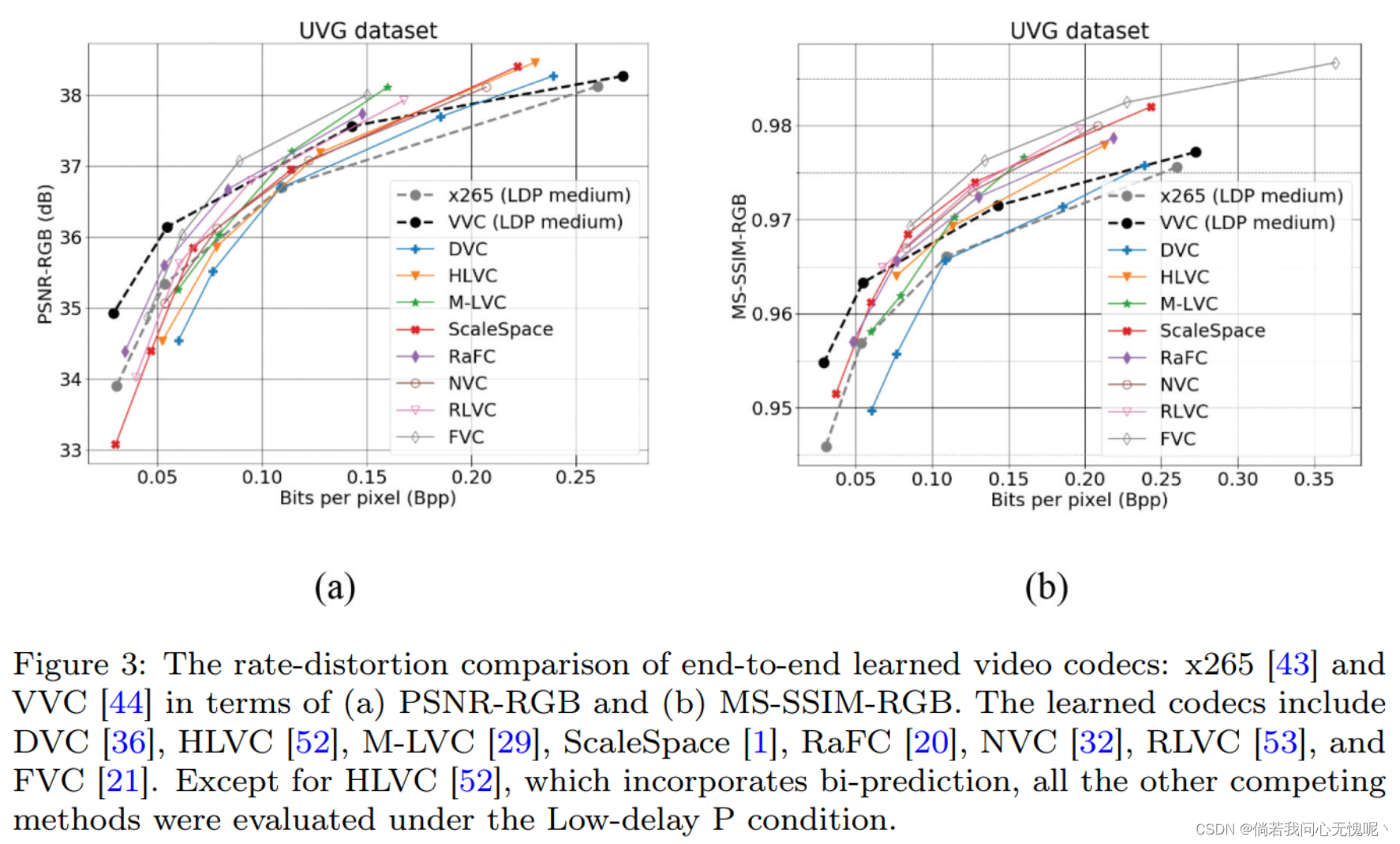
【Wen-Hsiao】 如今,端到端的学习编解码器正在迅速赶上来。在PSNR方面,最先进的学习图像编解码器的性能与VVC Intra相当(见图2a);最好的基于学习视频编解码器打到了由于HEVC的PSNR效果,在GOP为21的低延迟P测试条件下,并且在高码率表现接近VVC(见图三a)。在MS-SSIM方面,学习得到的图像编解码器的MS-SSIM远高于VVC Intra(见图3b);同样,大多数学习视频编解码器在低延迟P条件下(GOP = 12)都比HEVC取得了更好的MS-SSIM,在高码率下也比VVC取得了更好的性能。
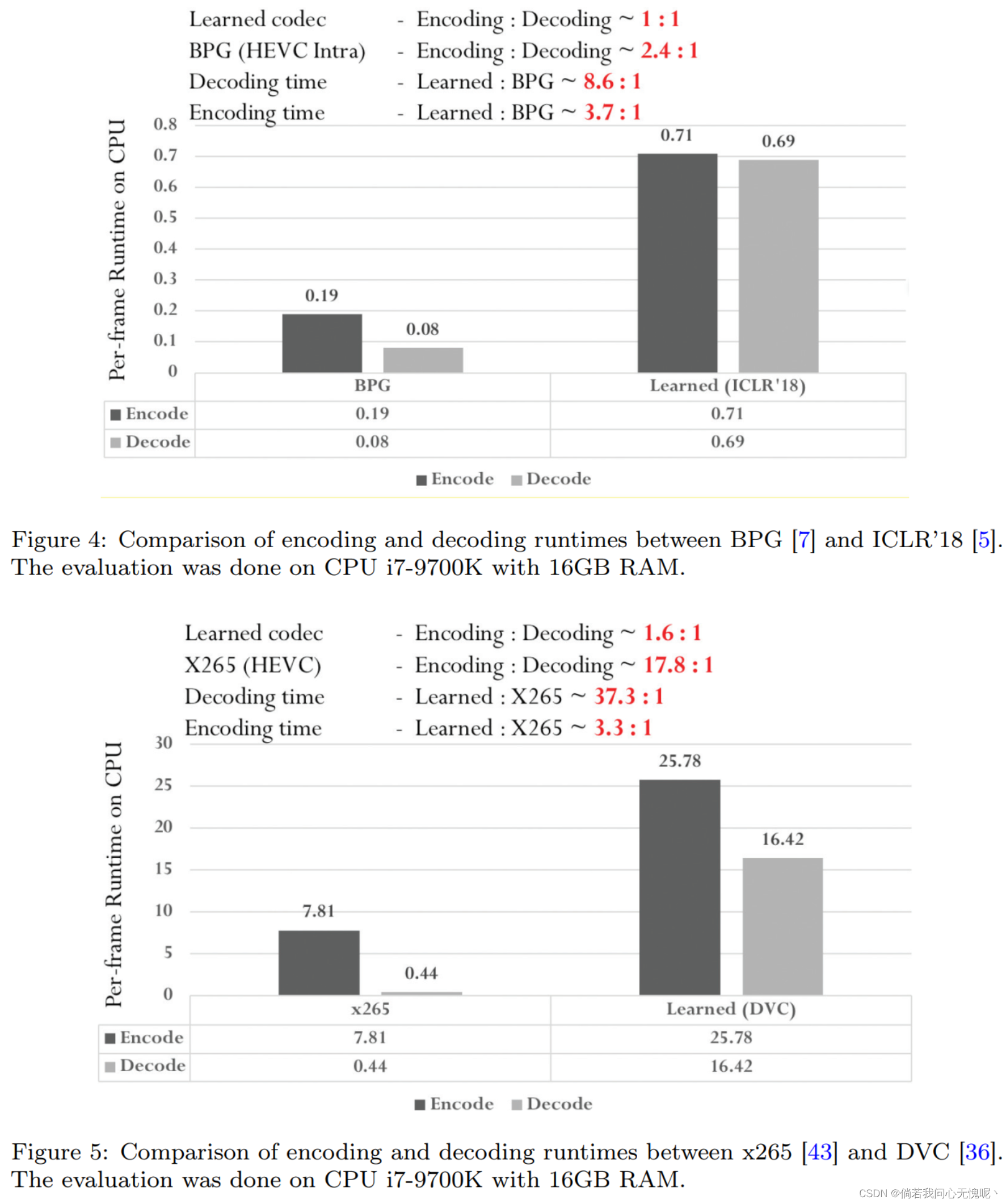
 对于图像编码运行时,图4比较了基于hevc的bgp编码器[7]和基于学习的编解码器[5]之间的编码和解码运行时间。对于学习的编解码器,编码和解码的运行时是相同的,这与所选的自动编码器的对称架构有关。 对于BPG[7],可以看出传统的编解码器编码时间较长,主要是由于编码器采用了率失真优化(RDO)过程。在解码时间上,基于学习的编解码器比传统的bgp高出约8.6倍。对于视频编码,图5比较了X265(用于HEVC的编码器)[43]和基于学习编解码器(DVC)[36]之间的编码和解码运行时间。对于基于学习的视频编码器,由于光流估计网络的问题,其编码时间是解码时间的1.6倍。 相比之下,X265的编码时间明显高于解码时间(18×)。这是由于传统编码器的RDO过程根据每个视频帧的特性对编码方式进行了调整。显然,基于学习的编解码器还没有达到相同的编码优化水平;未来还有进一步改善的空间。在解码方面,基于学习的解码器仍然比传统解码器复杂得多。
对于图像编码运行时,图4比较了基于hevc的bgp编码器[7]和基于学习的编解码器[5]之间的编码和解码运行时间。对于学习的编解码器,编码和解码的运行时是相同的,这与所选的自动编码器的对称架构有关。 对于BPG[7],可以看出传统的编解码器编码时间较长,主要是由于编码器采用了率失真优化(RDO)过程。在解码时间上,基于学习的编解码器比传统的bgp高出约8.6倍。对于视频编码,图5比较了X265(用于HEVC的编码器)[43]和基于学习编解码器(DVC)[36]之间的编码和解码运行时间。对于基于学习的视频编码器,由于光流估计网络的问题,其编码时间是解码时间的1.6倍。 相比之下,X265的编码时间明显高于解码时间(18×)。这是由于传统编码器的RDO过程根据每个视频帧的特性对编码方式进行了调整。显然,基于学习的编解码器还没有达到相同的编码优化水平;未来还有进一步改善的空间。在解码方面,基于学习的解码器仍然比传统解码器复杂得多。
2.2.3 Open Issues
【Wen-Hsiao】 对于已学习的编解码器,仍有几个开放的问题有待解决。(a)复杂性太高,因为使用了大量的网络。(b)多码率编码是另一个问题,目前大多数专家仍然使用单独的模型来实现不同的比特率。©端到端学习编解码器的速率控制是一个探索不足的领域。相关课题的研究还很少。(d)编码器优化当然是个问题; 如何使编码过程适应每一个输入的视频帧或图像,对于已学习的编解码器来说是一个很困难的工作。(e)泛化是另一个问题,特别是如何使学习的编解码器不那么依赖训练数据。(f)无损或近乎无损编码也是一个问题,因为大多数学习过的编解码器无法达到这种性能
2.2.4 Visual Quality for End-to-end Learned Codec
【Hsueh-Ming】 近年来,深度神经网络(DNN)在模式提取、存储和检索方面表现出了出色的性能,特别是在使用合适的训练数据集训练DNN模型时。这样的特性(模式提取和检索)对于成功的端到端学习编解码器压缩和重建图像是很重要的。基于学习的编解码器通常具有良好的主观图像/视频质量。即使在基于dnn的图像编解码器开发的早期阶段,这也是众所周知的。例如,在2018年的一篇论文[2]中,人们可以看到学习编解码器和bgp编解码器之间的比较(H.265单图像压缩)在0.035-0.039 bpp左右的极低比特率下(图6引自[2])。主观上,基于学习的编解码器生成的图像明显具有更好的视觉质量;但是,学习后的编解码器的PSNR值并不高。基于学习的编解码器重新合成图像,产生良好的主观质量,但它可能不是原始图像的忠实再现。
 对于热点研究领域,我的观察如下。(1)在过去的4-5年有很多关于帧内图像编码的出版物。到目前为止,领先的帧内学习编解码器(如2020年的[11]和[27])可以达到比最好的标准编解码器(H.266或VVC)更好的视觉质量(MS-SSIM)具有可近似的PSNR值时。(2)帧间视频编码要复杂得多,因此基于DNN的端到端编解码器大约三年前才开始发展。在帧间编码,特别是视频预测器和插值器方面还有很多工作要做(如提取物体运动的模式)。因此,所学的视频编码系统还有很大的改进空间。(3)由于基于学习的编解码器产生良好的主观图像质量,但均方误差等基于目标的质量较低,因此需要一种广为接受的视觉质量评估方法。
对于热点研究领域,我的观察如下。(1)在过去的4-5年有很多关于帧内图像编码的出版物。到目前为止,领先的帧内学习编解码器(如2020年的[11]和[27])可以达到比最好的标准编解码器(H.266或VVC)更好的视觉质量(MS-SSIM)具有可近似的PSNR值时。(2)帧间视频编码要复杂得多,因此基于DNN的端到端编解码器大约三年前才开始发展。在帧间编码,特别是视频预测器和插值器方面还有很多工作要做(如提取物体运动的模式)。因此,所学的视频编码系统还有很大的改进空间。(3)由于基于学习的编解码器产生良好的主观图像质量,但均方误差等基于目标的质量较低,因此需要一种广为接受的视觉质量评估方法。
3. The Trend of Deep-Based Video Coding
第二个问题是“基于深度的编码会成为视频编码的主要趋势吗?”是或否?为什么?”
3.1 General Trend and Issues on Network Depth
【Dong】 深度学习将在未来的视频编码标准中扮演重要的角色,无论是在dl辅助、基于dl的端到端、混合或其他方式。谷歌和NYU发表了三篇关于基于深度学习的图像压缩的重要著作[4,6,39]。目前基于学习的编解码器在某些情况下已经取得了与VVC/H266[8]相当甚至更好的效果。
【Jiaying】 基于学习的编解码器面临的挑战之一是由于网络的深度造成的复杂性。根据应用程序的不同,我们可能不需要很深的网络。基于我们在深度学习环路滤波器中的观察,我们实现了10%的BD率提高[45]。我们还看到了不那么深入的端到端学习的编解码器,比VVC更快,编码器和解码器可以只用4个卷积层实现,这是轻量级的。我们还见过一种从数据中学习但没有优化器的单层方法。我们还应该考虑复杂性和实用性之间的权衡。
3.2 Counter Viewpoint on Deep-Based Video Coding
【Jay】 我对基于深度的视频编码有不同的看法。目前的视频编码框架已经经过了几十年的微调。现在,人们愿意考虑一种非常不同的方法。如果没有好的替代方案,那么基于深度的编码将会受到关注。但是,如果有另一种选择,事情可能会有所不同。如果我们不理解深度学习为何有效,就很难想出一个有竞争力的替代方案。我们已经尝试开发一种新的视频编码方法,可以捕捉到深度学习的本质,但它不是基于深度的。其中一个重点是绿色视频编码,这意味着低功耗。深度学习显然不是一个绿色解决方案[55]。
新的视频编码标准的目标是将50%的带宽压缩为10倍的复杂度。拥有光纤、5G等宽带基础设施。在适当的地方,降低比特率可能不那么重要。另一方面,随着越来越多的视频物联网设备的部署,对节能的需求越来越大,低功耗的视频编码变得越来越重要。 例如,VVC在优化速率失真权衡方面非常出色。但是,我们可能需要进一步降低它的复杂性,例如,在保持相同的率失真性能水平的同时,降低为今天VVC复杂度的1%。由于基于深度的编码技术偏离了这一绿色原则,所以我对它不太感兴趣。
3.3 Understanding of Why/How Things Work and Visual Quality
【Gary】 理解事情为什么会起作用是很重要的;了解相关理论可以帮助我们超越我们今天所知道的。这是学术界的自然角色。更好地测量视觉质量也将帮助我们进入下一步。我们仍然处于能够衡量质量的初级阶段。PSNR不是重点,但到目前为止,替代方案并没有像我们希望的那样发挥更好的作用。我们需要在优化算法中加入质量控制。质量测量及其优化将是一个重要的趋势。
4. Visual Quality Assessment and Its Impact
第三个问题是“视觉质量评估是学术界的一个热门研究课题。”已发表多篇论文。这项努力会对视频编码标准化产生真正的影响吗?”
4.1 Focusing on Visual Quality Assessment for New Media
【Jay】 压缩伪影不是一般的伪影。它们是来自图像/视频编码的特殊伪影。在低比特率的视频中,人们对测量伪影没什么兴趣,因为它的质量太差,无法吸引人们。另一方面,当比特率很高时,不同质量指标之间的差异很小。我认为使用PSNR作为一个度量来衡量高比特率图像/视频的质量没有问题;开发新的质量指标的价值值得怀疑。主战场应该在中比特率的图像/视频。
对于监督质量评估,主要的挑战是如何进行监督。进行大规模的人的主观测试是昂贵的。对于完全参考或没有参考的质量度量,通常在编码器有完全参考而在解码器没有参考。由于解码器环境是多种多样的,解码环境的标定比较困难。由于这些差异,有许多研究问题,我们已经看到许多关于视觉质量评估的论文发表。
我与Netflix合作开发了VMAF(视频多重评估融合方法)全参考视频质量指标[46]从2013年到2015年。由于Netflix拥有一个封闭的用户社区,该公司可以在其视频传输系统中采用VMAF,并进一步使其成为一个开源平台。因此,VMAF实际上成为了其他公司使用的视频质量评估标准。然而,这是一种罕见的情况。虽然关于图像/视频质量评估的论文已经发表很多,但很难产生实际的影响。我认为我们应该更加重视立体视频、360度视频、AR/VR等新媒体的质量评估。 显然,PSNR对他们不起作用。迫切需要更好的质量度量标准。这里有更多的研究机会。
【Shan】 除了提供用户视觉体验的客观度量外,视觉度量还用于视频编码,如模式决策过程。PSNR或MSE已经用于t调整视频编码器几十年,并证明是有效的。另一方面,传统的视觉指标如PSNR不适合用于评估一些新兴媒体格式的视觉质量,如点云和光场等。开发这些新指标的需求正在上升。
4.2 Experience from the Standardization Committee
【Gary】 到目前为止,在国际标准化委员会中,我们还没有看到使用PSNR导致我们在视频格式设计中做出错误的决定。当我们尝试使用其他指标时,我们有时会感到困惑,而总体上它们都指向同一个方向。最近,我们看到JPEG-XL针对不同的指标得到了截然不同的结果,而且这种设计还没有得到充分的研究。到目前为止,我们还没有看到改进参数对标准化的巨大影响,但它有巨大的潜力,可能改变整个游戏。
4.3 Subjective Quality with an End-to-end Learning Based Codec
【Hsueh-Ming】 对于娱乐视频来说,目标是主观质量。如[27]所示,就PSNR而言,端到端基于学习的编解码器产生的值与VVC相当。但是就MS-SSIM而言(可能是一种比PSNR更好的主观质量度量),经过优化MS-SSIM训练的端到端学习编解码器的性能优于VVC(图7引自[27])。另一方面,类似于很多其他的DNN-based方案,基于端到端学习的编解码器可能无法产生在特定条件下对原始图像的良好逼近。 因此,这在某些应用(如医学成像)中可能会引起关注。(这一点在医学方面肯定是非常不好的啦,类似于医学图像超分的问题,万一超分出个不存在的东西这不就完蛋了)
5. The Role of Academia
专家组提出的第四个问题是“在开发新一代视频编码技术(或标准)方面,学术界是否有一席之地?”
5.1 Possible Research Areas for the Academia
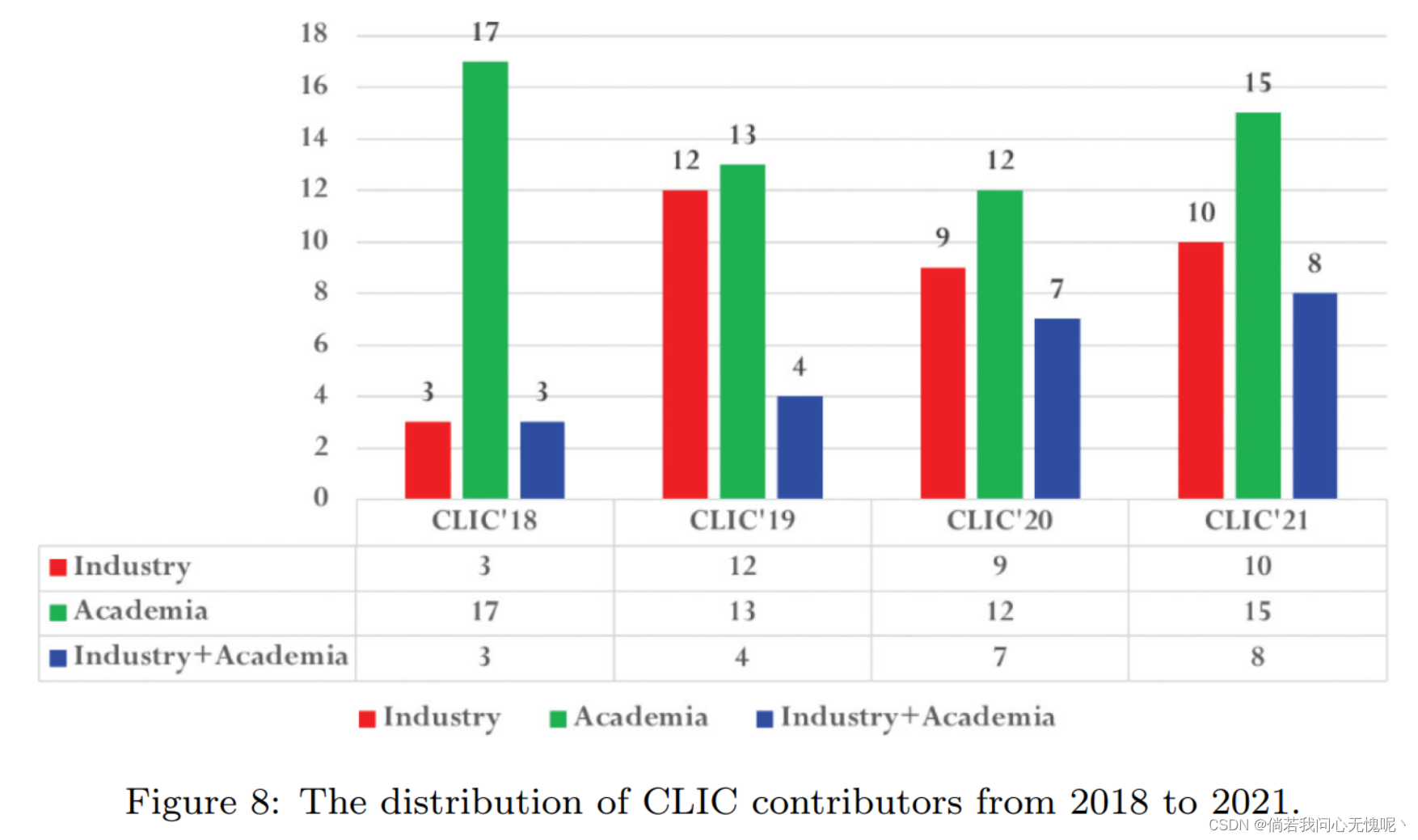
【Wen-Hsiao】学术界在探索新的和创新的想法方面更灵活,从工业界的观点来看,这些想法似乎更漫长,更不成熟。 如果我们看看2018年至2021年CVPR学习图像压缩(CLIC)挑战的贡献者(见图8),大多数贡献者最初都来自学术界。然后,更多的工业贡献者加入进来。最近,我们看到了许多产业界和学术界的联合合作。因此,有足够的空间让学术界与业界合作,为视频编码的未来做出贡献。
【Hsueh-Ming】 JPEG-AI去年发布了一份“呼吁证据”,并在MMSP 2020年会议[22]上报告了结果。对这一证据(挑战)的呼吁只有6个回应。最后,评估是基于人类观察员。之后,JPEG-AI成立了一个专门小组,致力于使用端到端的基于学习的编码方法来标准化它的可能性。它的范围和框架超越了人类可视化,因此它也针对图像处理和计算机视觉任务;也就是说,输出可能会被机器而不是人类消耗。换句话说,压缩后的图像可能会被超分辨或去噪等图像处理任务处理,但它们也可能被用于计算机视觉任务,如分类、目标检测/识别和语义分割。因此,我们的目标不仅是为人类观看者获得良好的主观质量,而且还为图像处理和计算机视觉产生良好的结果。 这项标准活动目前正在进行中。
【Gary】 JPEG-AI也在寻找不仅仅是压缩,而是基于神经网络的编码方法可以做什么,图像可能比视频处理更简单。
5.2 Understanding Why Things Work
【Shan】 深度学习已经证明了它在解决各种计算机视觉和图像处理问题方面的有效性,因此最近人们越来越热衷于将深度学习应用于视频编码。一种观察是,一些人将神经网络作为一个黑匣子,似乎认为通过调整参数可以轻松获得良好的结果。值得提醒的是,任何研究如果要取得成功,都需要深入了解基础知识。技术发展需要健康的生态系统来培育和滋养。学术界和工业界的合作发挥着重要作用。
5.3 Collaboration with Industry
【Jay】 我想强调产业界和学术界合作的重要性。 学术人士只要有了新想法就可以写论文。人们可以低成本的根据不同的想法发表100篇论文,因为它们大多只涉及计算机模拟。如果其中一个最终被工业界采用,那将是一个巨大的成就。(学术人士只要有新想法就可以写论文这一点我真的哈哈哈哈哈哈,一堆的叠卷积层的方法,要么一堆不开源的方法,这谁晓得你真的假的。)
6. Advice for Graduate Students
小组讨论的第五个也是最后一个问题是“您对想从事视频编码研究的研究生有什么建议?”
6.1 Areas and New Framework
【Dong】 首先,我们鼓励研究生不仅了解深度学习或压缩,而且需要了解这两个领域,因为许多领域是跨学科的。其次,我们鼓励学生使用新的框架。例如,在我们的DVC论文[36,37]中,最初我们研究像素空间来执行运动估计和提取光流信息,但现在通过使用可变形卷积来研究特征空间。这是CVPR 2021年的工作[21]是一个完全不同的框架,其结果得到了显著的改进。我们还在点云序列[41]上进行了深度压缩,我们也是最早在这个方向上开展工作的团队之一。第三是试图解决黑盒子之外的根本问题。很难解释为什么它适用于图像/视频压缩。我们在这方面没有取得太多进展,但这很重要。 第四,人工智能和深度视频压缩仍然有未来,因为最终我们会有一个人工智能芯片,它可以用于视频压缩、人脸识别和许多其他应用。它不同于以前的小波。我们相信,最终基于深度学习的方法将取代DCT。现有的芯片不支持基于小波的方法,需要设计新的芯片来支持基于小波的方法。然而,目前设计用于人脸/图像识别的芯片可以很容易地用于支持基于深度学习的图像/视频压缩。当性能较好的深度视频压缩(DVC)方法可与基于DCT的标准相媲美,很可能这些DVC技术将很快在现有芯片中得到支持。
6.2 Entry Barrier om Industry - Deep Learning verus Video Coding
【Jay】中国和美国的文化是不同的。在中国,如果有一个教授是编程方面的专家,他/她的学生就会跟随这个方向进行研究。美国是自由市场。如果教授的课题不流行,就很难吸引学生。还有其他原因,比如进入壁垒。机器学习工具如Python和TensorFlow的进入门槛较低。学生们可能会说,通过三个月熟悉这些编码工具,他们已经很好地了解了深度学习。相比之下,压缩具有很高的势垒。一个新人可能需要1到2年的时间来熟悉C代码和编码参考代码。高壁垒是一种保护,因为人们不能在短时间内获得相同的技能,专家难以替代。 深度学习程序员更容易被取代,因为低门槛不仅对他们有好处,而且对其他人也有好处。
许多公司都在寻找从事机器学习的人才,但申请者的数量也很高。虽然视频编码的就业机会较少,但应聘人数较少。从需求端来看,多媒体行业确实需要编码工程师。供应与需求不匹配。许多学生都是职业导向型的。深度学习的供大于求。(Many companies look for people in machine learning, yet the number of applicants is also high. Although there are fewer job opportunities in video coding, the number of applicants is fewer. From the demand side, the multimedia industry does need coding engineers. The supply does not match the demand. Many students are career driven. The supply could be more than the demand in deep learning.) 已经可以感觉到三四年后毕业即失业的事了。
6.3 Knowledge of Signal Processing and Deep Learning
【Shan】传统的或非基于学习的视频编码仍然是当今视频通信的支柱。例如,在实时视频会议中,视频编码提供核心功能,而深度学习可能用于一些附加功能,如虚拟背景和人脸修饰。在过去的3-4年里,我并不缺乏来自深度学习背景的简历或求职者,但具有视频编码专业知识的求职者并不多。 与市场的高需求相比,视频编码工程师的供应似乎非常低。一名优秀的视频编码工程师几乎可以保证有多家一流公司的报价可供选择。 视频编码是建立在信号处理理论基础上的。一个既有扎实的信号处理背景,又有深度学习知识的人显然是非常可取的。对于从事深度学习课题并可能考虑从事行业工作的学生来说,需要提醒的是,我们开发的深度学习算法通常需要在客户端和移动设备上实时运行。这就是Python和其他脚本语言面临挑战的地方,而良好的编程语言(如C/ c++)技能可能会有所帮助。 (这也是一个比较重点的地方,python语法真的太基础并且性能方面太低了,很多做CV和DL的学生现在能写一些Python的代码,但其实要是用别的语言写点东西大家是一点都不晓得。)
6.4 The Importance of Fundamental Knowledge
【Jiaying】郭教授告诉我们,在那段时间里,从事图形工作的人就像站在曼哈顿一样,视频编码的人在东边,而生物信息学的人在西边。它展示了不同研究领域的一些情况。2010年毕业后,我的研究方向从视频压缩转向了低水平的计算机视觉。2018年,我的团队(学生)又回来了,再次致力于视频编码,因为我们发现了计算机视觉的一些关键技术,尤其是在低水平上,可以自然的用在视频压缩策略中。它帮助我们得到准确的预测或适应更复杂的关系。
我们也对机器视频编码(VCM)感到非常兴奋,我们的小组去年发表了几篇论文[12,18]来讨论潜在的范式。这将信号处理和计算机视觉结合在一起,并尝试使用深度神经网络来连接这两个领域。
这些新课题广泛地扩展了视频编码的研究范围。今年,作为CVPR的区域主席,我处理了28篇论文,发现其中三分之二与视频编码相关。我们组有六分之三的学生在这个领域工作。我也同意基础知识是非常重要的,虽然我的学生对调整参数非常熟悉,但我们关于信号处理方法的知识可以给我们很多启发。
7. Questions and Answers
观众的提问和小组成员的回答将在本节中展示。
7.1 Video Coding in Decentralized Computation
第一个问题:在分散计算中,视频编码有未来吗?
【Gary】视频编码去中心化意味着大量的交互优化。分散事物并使它们并行最终会导致无法有效优化像视频编码器这样的复杂系统。我们可以并行处理不同的图片,但在经典的设计中,并行处理的程度是有限的。
7.2 Application/Market-Driven versus Technology-Driven
第二个问题:早期的视频编码标准主要是由应用驱动的,具有大众市场。随应用程序而来的特性可以用来优化事物。后来,标准更多地由技术驱动。像H.264和H.265这样的标准是成功的,并产生了影响,因为它们能够实现50%或更多的改进。在应用方面,人们提到了机器的高分辨率和压缩,但这些新应用中的新特征是什么,可以用于进一步的技术改进? 此外,是否存在能让很多人感兴趣并参与其中的大众市场应用?在技术方面,使用基于深度学习的方法可以实现30%、40%或更多的改进吗? 有了这种水平的改进,我们就有了影响力,就会成功,人们就会愿意投资; 对于学术界来说,只有高度改进空间,才值得博士工作。
【Gary】关于市场和需求问题,对于我们正在做的一些有趣的事情,我们真的不知道市场有多大。这也使需求分析变得复杂。不知道市场有多大,就很难看到满足市场需求的要求是什么。在增益方面,3%在现在的视频编码中已经是很大的数字了,并且可以发布。我们进入VVC的方式主要是获得1%或3%的收益,并最终转化为50%的收益。
【Shan】市场对视频编码的需求从未消退。在疫情期间,全世界的工作、学习和一切都依赖于视频通信。全球网络的带宽压力过去是(现在仍然是),在高峰月份,区域性中断时有发生。此外,新兴应用如云游戏、VR、免费观看和沉浸式视频需要比传统视频应用更高的比特率。因此,对视频压缩的需求一直存在。
【Wen-Hsiao】关于应用程序和费率节省,我们需要考虑视觉质量指标。例如,如果我们使用MS-SSIM,基于学习的视频压缩已经比传统的压缩方法获得了显著的增益。我认为基于学习的视频压缩开辟了新的应用,因为目标函数如果可微,可以针对不同的目的进行优化,这是传统编解码器无法轻易实现的。值得注意的是,JPEG AI[23]正在寻找专门用于人类感知和计算机视觉任务的基于学习的图像压缩技术。
7.3 Training Data -Crucial for Learned Based Codec
【Wen-Hsiao】另一方面,使用基于学习的压缩也有危险。我们需要对训练数据非常小心。训练数据对其编码性能有着至关重要的影响。例如,我们通常不使用白噪声作为训练数据。从图9可以看出,在编码白噪声时,端到端的学习编解码器的率失真曲线实际上在经过一定的比特率后趋于平稳,比传统的编解码器如bgp[7]差很多。这是因为自动编码器实现了非线性转换;当训练数据不能很好地表示时,编解码器学习的是不完整的基础,因此不能表示任何类型的信号。另一方面,传统编解码器常用的离散余弦变换(DCT)实现了一个完整的基,当给定足够的位时,可以表示任何类型的信号。
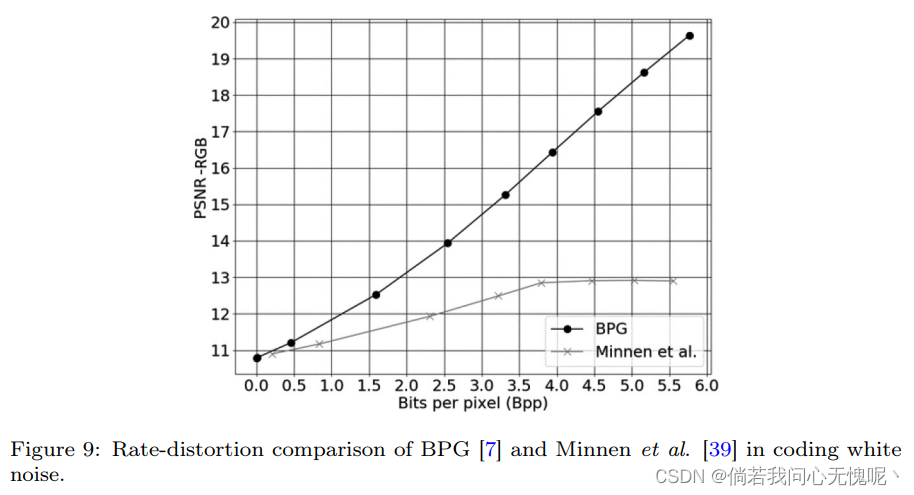
第三个问题:关于基于学习的模型的泛化能力,如果测试序列完全从训练数据中看不到,那么视觉质量是相当差的。你有类似的经验吗?
【Wen-Hsiao】 是的,训练数据真的很重要。有一些新的类型的自动编码器;例如,一些早期的尝试[14,15,38]使用可逆或可逆的神经网络,这实际上可以表示任何类型的信号,并使学习的编解码器对训练数据不敏感。我们已经做了一些研究[15],发现这类网络有潜力用于压缩,但仍有很多工作要做。
【Dong】 如果我们有良好的训练数据,我们可以实现比最先进的基于学习的编解码器的显著改进,并可能超过最好的传统编解码器。在早期阶段,我们使用数据集Vimeo-90k[51]用于底层计算机视觉任务,这些任务不是针对视频压缩,但对于工业和学术界来说,收集大规模数据集来训练视频压缩模型是很重要的。我们还研究了如何减少训练和测试数据之间的数据分布不匹配(参见我们的ECCV 2020工作[35])。针对不同的视频,我们可以对模型参数进行微调,同时修复解码器。多年来,我们一直致力于视觉领域的适应(查看我们的调查工作[54],了解该领域的最新进展);当训练数据和测试数据来自不同的领域时,模型不能很好地在测试数据上泛化。也许在视频压缩中更难解决这个问题;也许我们需要收集更多的数据来尽可能多地表示不同的分布,以部分地解决这个问题。
【Shan】 认识到视频训练数据对基于学习的视频编码技术研究的重要性,Tencent构建了一个视频数据集TVD,其免费用于科研和标准化使用。该视频数据集已经为JVET在基于神经网络的视频编码(NNVC)方面的探索活动做出了贡献[3,33]。
7.4 Image Coding Job Market
第四个问题:使用深度学习技术的图像编码人员在就业市场上受欢迎吗?
【Gary】学生应该具备完整的传输视频编码技术知识背景,并了解事物的工作原理。
【Shan】行业欢迎对图像编码和深度学习有深入知识和理解的学生。精通至少一种编程语言(除了脚本)将会是一个很大的优势。(除了python,还得学一门C++或者Go会比较好一点,尤其是在Video Coding方面)
7.5 Reducing the Complexity and Different Codec Framework
第五个问题:视频压缩的极限是什么?我们还要走多少路?或者是时候让我们专注于降低编解码器的复杂性了?
【Jay】 近年来,基于深度的图像/视频编码引起了人们的极大兴趣。然而,我们需要理解深度学习背后的原理,并做一些透明和可解释的事情。我不太关心编码效率,而是关心编码复杂度。 我希望我们能减少VVC复杂性,在保持其编码效率的同时,采用了一种新颖的框架。
第六个问题:从H.261到H.266(大约30年),我们一直遵循相同的混合型基于块的编解码器框架(变换、量化、运动补偿等)。标准化委员会是否有一个计划来研究一个完全不同的框架,不是以进一步降低压缩比为目标,而是可能将复杂性降低至少50%?
【Gary】 如果我们在混合的基于块的框架中有不执行增量任务的方法,我们会很欢迎。我们一直使用这种基于块的模型的原因是它看起来工作得非常好。我们试图研究其他方法,但这是我们最终得到的结果。如果我们看不到一条通往不同方向的明确道路,我们不希望放弃已经摆在桌面上的事情。至于还有多少收益,我想没有人知道。我们将继续努力,直到我们没有办法做得更好,或者想出一个理论来表明我们不能做得更好。这是有潜力的;其中一部分是使用替代的质量度量,或者替代的架构。即使使用经典的信号处理方法,我们似乎也能挤出更多的增益;在VVC之后不到一年的时间里,我们已经知道如何用常规方法,以及一些复杂的问题,来做14%的改进。(The reason that we have used this block-based model till today is because it seemed to work very well. We have tried to investigate other approaches but this was what we ended up with. We do not want to abandon things on the table if we do not see a clear path in a different direction.)
7.6 More on the Problems of Data-Driven Approach
第七个问题:既然训练数据的性质对结果有很大的不同,而且很难适合每一种情况,机器学习方法难道不应该更特殊的目的或应用依赖,而不是试图让训练数据适合一般的每一种情况吗?
【Jay】基于深度的图像/视频编码背后有两个强大的思想。大多数视频编解码器基本上是单尺度方法,尽管有大小可变的块。如果我们能很好地利用分层表示,将会有很大的收获。另一种是数据驱动的表示。一个著名的例子是矢量量化(VQ)。我们可以学习图像样本的分布。如果训练图像和测试图像相关联,深度学习可以获得较好的编码增益。同样,学习到的VQ码本也依赖于训练图像集。
我的实验室正在研究绿色编码,以与现在的深度学习编码竞争。这些都是需要考虑的工具。我花了6-7年的时间来理解深度学习,现在我们已经准备好迎接一个新的范式。在我看来,黑箱方法不会持续太久,我们不能在黑箱上建立知识。我们需要事情变得更加透明和模块化。线性代数、概率、统计、优化和信息论等数学工具应该成为未来图像/视频编码技术的基础。
【Gary】神经网络训练数据的过拟合问题并不是一个新问题。我们曾经研究VQ,但如果我们没有一个健壮的训练数据集或通用能力,同样的过拟合问题会发生在那里。因此,我们需要一种通用的方法。
【Shan】将深度学习应用于视频编码,我们还处于探索阶段。虽然已经取得了令人印象深刻的研究进展,但在将其用于实际产品之前,还需要解决许多实际挑战。
7.7 Graph Signal Processing
第8个问题:对于新媒体来说,如何表现数据是核心问题。图信号处理与神经网络相结合处理编码任务是否可行?
【Jiaying】图信号处理非常热门,但它依赖于数据,对于特定的应用程序,如点云和其他应用程序,它可能非常有用。但我们不确定它是否适用于一般情况下的视频编码。在一些具有非常稀疏特征表示的计算机视觉任务中,我们采用了机器视频编码(VCM)。点和边或其他特征图对于图像是好的。在关键帧中添加更多的信息,比如残差,可以用来重建像素级的视频信息。图信号处理在一些新的领域如VCM中可能是有用的。
7.8 Generative Models
第九个问题:像生成对抗网络(GAN)这样的生成模型如何在视频编码中发挥作用?
【Dong】基于gan的方法在低比特率下可以很好地工作,但在高比特率下可能就不那么好了。对于图像压缩,来自谷歌组[4,6,39]的管道获得了很好的结果,通常优于基于gan的方法。对于视频压缩,也许我们应该采用混合压缩方法,包括残差压缩和运动压缩[36,37]。如果你有较低的比特率,也许基于gan的方法在某种程度上可以工作。
【Hsueh-Ming】两三年前,有一些关于基于gan的图像压缩方法的论文,例如[2]。最近,自动编码器方法似乎更受欢迎。可以观察到,自动编码器或基于CNN的编解码器可以在较低的比特率下更好地处理大多数图片。
8. Conclusion
【Nam】综上所述,从面板来看,视频编码的未来似乎是非常光明的。未来还有更多的挑战需要研究人员去应对和解决。重点在此总结。
- 新兴领域: 标准化委员会正在考虑一种双轨方法,传统的混合区块型轨道(一直做得很好)和一种使用神经网络的轨道。新技术的出现往往是由新兴应用(如沉浸式应用)推动的;因此,我们预计容3D视频、虚拟现实、云游戏和低功耗边缘计算将有很高的需求。另一个新兴领域是机器视频编码(VCM)。大多数专家承认深度学习在未来视频编码中的作用,其主要挑战是其高度复杂性和需要一种被广泛接受的视觉质量评估方法。
- 深度学习视频编码的趋势: 在这个问题上,大多数专家认为,无论是在dl辅助、基于dl的端到端、混合还是其他方式,深度学习都将在未来的视频编码标准中扮演重要的角色。对于某些应用程序,我们可能不需要非常深入的网络,以降低复杂性。还有一种相反的观点指出,黑箱方法不会发展得太远,应该有一种替代方法,特别是需要专注于降低复杂性和功耗,而不是提高编码效率(即绿色视频编码)。
- 视觉质量评估: 从标准化委员会对传统方法的观点来看,PSNR似乎工作得很好。端到端学习编解码器在MS-SSIM和主观的指标上显示出更好的结果,尽管在PSNR上没有那么高;有许多工作致力于开发其他指标。对于基于学习的方法,需要一种广为接受的视觉质量评估方法,而主战场可能在中比特率范围内。 专家小组还认为,为新媒体开发正确的指标很重要,如点云、360度视频、立体视频、AR/VR等。此外,目标不仅限于为人类观众实现良好的主观质量,而且还为机器使用产生良好的结果,如在许多计算机视觉和图像处理任务。
- 学术界的角色: 学术界在探索新的和创新的想法方面更灵活,从行业的观点来看,这些想法似乎更长期,更不成熟。在未来的视频编码领域,学术界与业界有很大的合作空间,这种合作发挥着重要的作用。该小组同意,理解事物为什么工作是重要的,而不是仅仅通过调整参数来获得好的结果,特别是在讨论学术界的作用时。
- 给研究生的建议: 小组认为,学生不应该只知道深度学习或使用信号处理的压缩,而是需要知道这两个领域,小组还鼓励学生在新的框架上工作。深度学习的门槛较低,可以在短时间内轻松掌握,而视频编码的门槛较高,需要更长的时间来掌握,因此工作保障更好。工程师在深度学习中掌握了Python和TensorFlow比视频编码中使用C或c++更容易被替换。
(别瞎几把搞深度学习啦,到时毕业工作就没啦) - 问答的其他要点: 在问答过程中还提出了其他一些新的关键问题:(A)去中心化和使编码过程并行化最终无法有效地优化像视频编码器这样的复杂系统。(二)市场对视频编码的需求从未消退,并将继续发光发热。关于增益,3%在现在的视频编码中已经是很大的数字了,而我们实现VVC的方法主要是通过许多1%或3%的增益,最终转化为50%的增益。基于学习的视频压缩开启了新的应用,因为目标函数,如果可微,可以用于不同的目标的优化。©提出的另一个主要问题是拥有正确的训练数据集的重要性,因为这对编码性能至关重要。泛化是另一个问题,特别是如何使学习到的编解码器独立于训练数据,减少训练和测试之间的数据不匹配是很重要的。(d)在图形信号处理方面,在一些新的领域如VCM上尝试它可能是有用的。(e)基于GAN的方法,专家认为它对低比特率可以工作得相当好,但对高比特率就不是这样了。自动编码器或基于cnn的编解码器可能更好。

















 1506
1506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









