






这是一篇来自CVPR 2022的文章,相较于传统的基于目标提议的两阶段方法,其将视频场景图重新表述为时间二部图(也称二分图),为视频场景图的生成及推理提供了新的研究思路。接下来对文章的主要内容做简要介绍。
问题原因及分析:
目前的VidSGG(Video Sence Graph Generation)模型都是基于提议的方法,即首先生成大量成对的主客体片段作为提议,然后对每个提议进行谓词分类。普遍的基于提议的框架有三个固有的缺点:
1)提议的谓词标签是部分正确的。在对象检测中,现有的基于提案的模型都遵循基于IoU的策略,基于体积IoU (vIoU)为提案分配谓词标签。这种策略自然会丢弃一些“基本真理”谓词,如果它们的前瞻值小于阈值。如图1(a)所示,在proposala和proposalb内部的多个框架上,两个关系behind和toward同时发生,但是为proposala分配的谓词标签仅为behind(和towards) 2。同时,一旦给提议分配了谓词标签,他们就假定这种关系应该在整个提议中持续存在(即,它发生在提议的所有框架中)。显然,这个问题的一个负面影响是,两个高度重叠的提案(proposala/b)的ground-truth标签可能完全不同,这种不一致会损害模型训练。
2)它们打破了同一主宾对的不同谓词实例之间的高阶关系。由于视频的性质,在同一主客体对之间总是会发生多重关系,这些关系可以作为关键背景(或归纳偏见),从而有利于对其他关系的预测。例如,“behind”、“toward”和“away”总是依次发生在狗和孩子之间。相反,基于提议的方法通过预先切割tracklet显式地打破这些高阶关系,并在每个提议中独立地对谓词进行分类。
3) VidSGG的性能取决于提议的质量(目标检测的限制)。VidSGG的性能对提议生成的启发式规则很敏感(例如,提案的大小或数量)。同时,为了实现更高的召回率,它们总是产生过多的提议,这大大增加了计算复杂度。
总体而言,目标检测很大程度上限制了两阶段方法的发展。

图1所示。(a):基于提案的框架的筹备工作。给定一个视频,它首先生成大量提议(具有不同的时间段),然后对每个提议进行谓词分类。(b):分级后接地框架的管道。首先基于整个轨迹对进行谓词分类,然后基于所有预测的关系实例。
解决方案:
提出一种新的VidSGG框架:Classification-Then-Grounding可以避免上述问题,此框架下,视频场景图重新表述为时间二部图,其中实体和谓词是两种具有时间段的节点,这些节点之间的边表示不同的语义角色。这一提法充分利用了提出的新框架。因此,在此基础上进一步提出了一种新的基于二部图的SGG模型:BIG。它包括分类阶段和接地阶段,分类阶段的目的是对所有节点和边缘的类别进行分类,接地阶段的目的是对每个关系实例的时间位置进行定位。
具体来说,首先基于整个tracklet进行谓词分类,然后对每个预测的谓词实例进行接地(图1(b))。与基于提议的方法相比,将两个tracklet之间发生的所有关系视为基础真值谓词标签(例如,behind, towards, away和in-front-of都是狗和孩子的基础真值谓词)。此框架不仅提供了更准确的真基谓词标签,而且还保留了利用谓词之间高阶关系的能力。此外,它避免了多余的建议和启发式规则。
在此框架下,作者提出将视频场景图重新表述为时间二部图,其中实体和谓词是两种具有时间段的节点,边缘表示这些节点之间不同的语义角色(即主体和客体)(图2)。每个实体节点是一个对象轨迹,其时间段是该轨迹的时间范围。每个谓词节点是具有相同谓词类别的两个实体之间的一组关系实例,其中每个时间段表示每个关系实例的时间范围(例如,图2中的谓词节点towards有两个时间段)。因此,每个实体节点可以与多个谓词节点链接,以表示涉及的多个关系,每个谓词节点最多可以与每个角色的一个实体节点链接。该公式不仅可以很容易地扩展到具有更多语义角色的更一般的关系,而且可以避免穷尽地枚举所有实体对来进行谓词预测。

网络结构

(a)Classifiction Stage
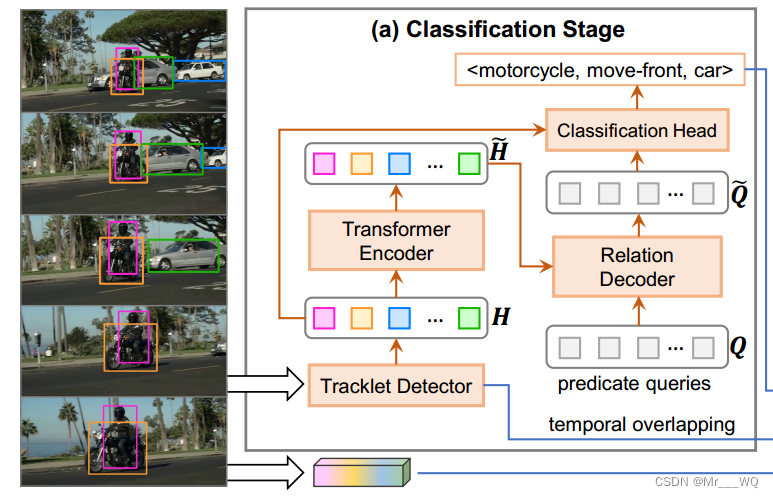
分类阶段的目的是对所有节点(即实体和谓词)的类别以及它们之间的边缘(即语义角色)进行分类。如上图所示,分类级由轨迹检测器、Transformer编码器、关系解码器和分类头四部分组成。
Tracklet检测器
给定一个视频,我们使用预训练的轨迹检测器来检测视频中的所有轨迹(表示为实体集),以及相应的时空位置、类别和特征。具体来说,对于长度为
(帧数)的每个实体
,其特征为边界框坐标
,对象类别
,时间段
,将所有检测结果固定为最终预测。
每个实体 的轨迹特征
是外观特征和空间特征的结合。利用RoIAlign,根据边界框位置在每一帧提取外观特征
,空间特征
是所有框坐标
与偏移量
的拼接,其中
是两个连续帧的框坐标偏移量,即
。
实体 的tracklet的特征
为:
其中,和
是两个课学习的MLP,[ ; ]是连接操作,Conv是一个1D卷积层。
编码器
普通的Transformer的编码器,给定实体特征集合 :

具体维度的变换参看原文。
解码器(Relation Decoder)
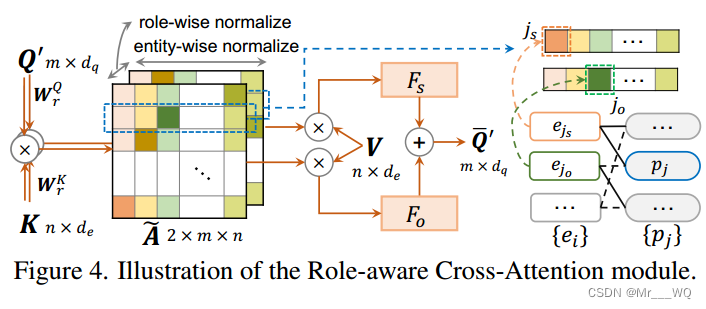
解码器设计用于预测图的边缘,并为以下谓词分类派生增强的谓词表示。解码器的输入是一个固定大小的m个谓词查询集合,具有相应的可学习嵌入向量Q。每个查询负责二部图中的一个谓词节点。在Transformer解码器的基础上进行构建,并用角色感知交叉注意(RaCA)取代原来的交叉注意。因此,各解码器层总结为:

其中LNorm为层归一化,Q(i)为第i解码器层的输入查询嵌入。最后一层解码器的输出记为,即增强的查询嵌入。同时,最后一层解码器的交叉注意矩阵(在RaCA模块内)记为Ae,可视为二部图的软边联动。关于RaCA模块的更多细节和讨论(相对于最初的交叉关注)见原文,此处不详细介绍。
分类头
给定查询嵌入和交叉关注矩阵
,分类头的目的是对每个查询的类别(即谓词节点)进行分类。如图4所示,
有两个通道,对应于二部图中两个不同的语义角色。基于
,我们首先通过在每个通道中选择关注得分最高的实体,得出每个谓词节点
的预测主体和预测对象,其指标分别记为
和
。那么,谓词
的分类特征
是三种特征的串联:查询嵌入
、主客体实体特征
和
,即
,其中
是对向类别
的GloVe嵌入,最后谓词分类的结果表示为:

是来自训练集的关系三元组类别的统计先验。
(b)Grounding Stage
接地阶段的目的是定位每个预测谓词节点的时间位置。到目前为止,对于每个谓词节点,分类阶段已经预测了它的类别
和两个链接的实体轨迹:主体
和客体
。在这一阶段,作者将谓词定位视为视频接地问题。具体来说,将三组类别序列
(例如,图3(a)中的<person,ride,motorcycle>)作为语言查询,并扩展现有的视频基础模型DEBUG,用于多实例谓词定位。如图3(b)所示,该阶段由三部分组成:特征提取器、特征编码器和多实例接地头。
特征提取(Feature Extractor)
对于给定的视频,作者使用预训练的I3D网络提取帧级视觉特征,其中T为整个视频帧数。对于query
(参考谓词节点
),作者初始化查询特征
,即三元组类别的GloVe嵌入。同时,由于每个谓词只发生在其主客体的重叠时间内,因此将该重叠时间的时间边界作为增强
的先验特征,即:
其中 是连接到谓词节点
的主客体的重叠边界。注意,在接地阶段只使用那些重叠tracklet的谓词节点。所有特征
的query共享视觉特征
。
特征编码器(Feature Encoder)
这个编码器的目的是模拟视频特征和所有查询特征
之间的交互。具体来说,作者使用与DEBUG[详见其参考文献26]相同的特征编码器,它包含两个并行嵌入编码器和一个多模态注意层。特征编码器的输出是一个融合的多模态特征
。具体参阅DEBUG[26]论文了解更多细节。
多实例接地头(Multi-instance Grounding Head)
与现有的视频基础任务中每个查询只引用一个片段不同,在VidSGG中,一个谓词类别可以在同一主客体对之间多次发生,即每个语言查询可以引用多个片段(参见图2)。由于不同谓词节点的时间段数量差异很大,因此很难直接预测每个查询的可变时间段数量。相反,作者为每个语言查询设置K个段。如图5(a)所示,在训练阶段,作者将整个归一化视频长度均匀地分成K个区间,即K个bin。然后,为每个bin分配以其间隔为中心的目标时间段。在测试阶段,所有时间段预测都由NMS处理,以减少误报。最后,NMS操作产生个时间段用于三元组查询
,记为
。

在DEBUG之后,作者设计了三个分支网络用于接地:分类子网、边界回归子网和置信子网(参见图5(b))。特别是,我们将最后一个卷积的输出通道扩展到K作为分类和置信分支,2K作为回归分支(对应K个bin)。
实验设置及相关细节参见原文。














 2220
2220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









