







https://blog.csdn.net/lipengcn/article/details/85313971
(文本匹配详解,有监督,无监督)
nlp 句子长度差距过大,如何统一长度输入到模型中,
一般结合具体业务, 不同长度可以分为 段文本、 长文本、 段落、 文档等级别, 都有不同的模型。。。
-
最笨 最容易想到, 最差的思路: 将长的截取,短的填充补齐,然后用分类模型,但是会有问题,很可能把最关键的部分截取掉,描述了一大段,很多时候是根据最关键的几个词语判断罪名,比如:造成致死、胁迫、威逼等。如果将长句子截取,很容易把最关键的词截取掉。此方案效果一般并放弃此方案。
-
tfidf选出top-k的词,然后根据这些词作为输入特征,训练分类模型。最关键的词权重往往很低,很容易漏掉,除非用相关法律语料自己重新训练lda或者tfidf,当时没有那么多语料,无法重新训练,
-
采用传统的方法,配置语料模板,类似于做搜索、对话系统faq的qq匹配或qa匹配方法,先召回,可用倒排索引或者向量召回,然后进行文本相似度分数计算,
这个项目采用的是如下公式:
score = w1 * bm25 + w2 * wmd + w3 * 余弦距离 + w4 * 长度惩罚
w1、w2、w3和w4是权重,需要做调参。
要用多个相似度算法加权求和,有基于语义的,有基于关键词的,此种方案短的句子容易匹配,长的句子较难匹配,这样对长句子不公平,要对长度做一定的惩罚,这样综合下来,结果就不会飘了。此方案的效果好坏取决于模板语料的好坏。本项目的第一版采用的就是此方法,效果在85%左右。但是此方案也有一些问题,首先**要对全文进行分词,文本太长速度会很慢,**好在本项目对速度要求不那么高,最后我们采用了一个速度比较快的分词器,可以满足要求。 -
采用bert+textcnn分类,由于bert最大长度是512,超过此长度的需要截取成多段,然后对每段的cls向量做mean-pooling操作,作为输入向量。
https://linux.ctolib.com/TianyuZhuuu-CHIP2018.html
参考的别人总结
7.26 新总结
embedding层:
1)所有字向量和词向量,拼接简单特征,方便增量训练,还有训练学习空间。
2)字向量和词向量都进行增量训练:相当于使用elmo进行微调整。 使用给定的词向量作为ELMO的输入,利用ELMO去更新迭代给定的词向量,保存训练好的词向量作为最终的增量词向量。
(通过elmo,在给定词向量基础上,利用上下文,进一步学习深层次的语义信息,一词多义等)
3)字词融合: word对应的多个char,这多个char字向量输入到BiLSTM?? 如何训练,最后一个时刻的输出作为这些字向量训练的结果,然后拼接到增量训练的词向量后面。
https://blog.csdn.net/guoyuhaoaaa/article/details/78155007 (论文讲解字和词如何融合)
“深度学习中汉语字向量和词向量结合方式探究” 论文
论文里效果最好的是,以字向量为基础,作为匹配模型的输入, 字向量和其所在的词的词向量进行拼接。!!!!!!
字向量取平均,与原词向量进行拼接。
ESIM深入解析:
ESIM(Enhanced LSTM for Natural Language Inference), 专为自然语言推理而生的加强版LSTM。
https://blog.csdn.net/wcy23580/article/details/84988875
https://juejin.im/entry/5bdbe886f265da617830e0c0
https://blog.csdn.net/wcy23580/article/details/84990923
设计的亮点:
(1)序列式的推断结构:
(2)局部推断:(用句子间的注意力机制),进一步实现全局推断。
https://zhuanlan.zhihu.com/p/47580077
整体分为三部分:
(1)input encoding,
ai = bilstm(a, i) , bi = bilstm(b, i)
使用 BiLSTM 可以学习如何表示一句话中的 word 和它上下文的关系,word embedding 之后,在当前的语境下重新编码,得到新的 embeding 向量。
(2) local inference modeling (对齐过程,产生了丰富的交互)
计算相似度, eij = ai*bi
用之前得到的相似度矩阵,结合 a,b 两句话,互相生成彼此相似性加权后的句子。。(乘上相似度的之后的新句子。。)
aii = eij * bj
bii = eij * ai, a b都进行对齐操作。。
推理增强: 对齐后的自己, 差, 点积等操作。。
ma = 【a, aii, a - aii, a * aii]
mb = [b, bii, b - bii, b * bii]
(3) inference composition。全局推理。
ma, mb经过lstm, 各自经过maxpool, avgpool,结构拼接起来作为最终特征。。经过fc。预测。。

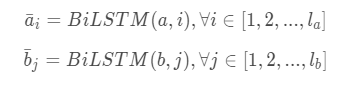
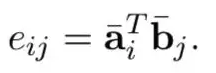


最后,前面都相当于提特征,然后加全连接层 + softmax激活
- 匹配模型相关
意图: intention
语义: semantic
Semantic textual similarity 语义文本相似度
Reformulation: 问题重述,换个表达方法。
分词: Chinese Word Segmentation(WS)
词性标注: part of speech(POS)
命名实体识别: NER
FAQ set: 问答语料库 -> 建立索引。(留着后面使用)
多样化口语表达归一化,提取核心语义。
LCQMC。实验室自己公开的数据集(问句匹配)
传统:tfidf,这种,提特征表示文本,利用向量计算相似度。
语义很难表示出来,手工特征复杂。速度快,可靠。
深度模型:
基于文本表示:DSSM。。。。Siamese CNN, ARC-I
(将文本序列转换为向量,来表示句子的核心语义,适合对文本建模表示,用于索引。。 没有句子交互过程,没有考虑到文本中各词的重要程度和句子结构,造成语义偏移)
基于文本交互:ESIM, DiSAN, 。。。。ARC-II(基于卷积), ABCNN, BIMPM, DRCN, (大部分好用的都是文本交互型的)
(文本序列转换为表示,之后,向量交互矩阵,表示句子之间的语义,对交互矩阵进行操作,从而语义之间的相对重要性就可以合理建模。)这种模型,适合大多数文本匹配的任务。
bimpm: 参数量大,所有句子间的交互作用都考虑到了。
ESIM: 输入的embedding, 局部推理建模,推理组合(链式处理)
BiLSTM对输入两个句子编码,attention计算两个句子向量间权重,类attention,计算交互信息,乘以attention值。a, b
元组局部信息:前面结果进行 差,乘积,ma, mb
推理组成:将前面得到的结果,最大池化,平均池化,结果再构成向量,去分类。
DiSAN:Directional Self-Attention Network for RNN/CNN-free Language Understanding, 输入序列每个元素之间注意力是定向的,多维的。
https://blog.csdn.net/weixin_34174422/article/details/88126823(disan)
Bpool(BiLSTM with mean/max pooling)
**ABCNN (attention-based convolution neural networks),**Attention应用到CNN中,在原有单词级的抽象中,增加一个短语级的抽象(高级别的),短语级表示:attention matrix*各自词向量, attention matrix由两个句子一起生成。
组内工作: GSD
关于评测:
问句匹配:判断两个问句之间的语义是否等价,核心是意图匹配。接近智能医疗助手等自然语言处理任务的实际需求,来源真实语料数据,并经过筛选和人工的意图匹配标注。
https://blog.csdn.net/cuihuijun1hao/article/details/84554012(第九名)
https://ruby.ctolib.com/article/wiki/102718(第六名)
数据情况:脱敏,字向量(C******), 词向量(W******), 句子(S******)
S******, S******, 0/1 (一条数据示例)
词和多个字对应(如何对应?)
35268个句子。提供的数据集:2w个训练集(句子对),正负例都均衡。测试集1w个(没有label)
word:9653个。 char:2308。
word embedding: 9647, char embedding: 2307
有些词没有embedding: UNK充当。
统计句子的长度,一个句子平均都是13个字左右,7个词左右,句子不长,数据条数很少。
模型太复杂,容易过拟合。用简单点的模型。
针对以上问题, 构造新数据,
1. 构造新数据进行扩充:
利用规则去增加数据:
图特征: 本质也是用传递性。正例图(里面互为正例构成的图,有连接的算一个图里面),每个图里面的样本之间互为正例(可以把没连起来的边,连起来算新正例),有一个负例两个句子,出现在两个图,这两个图之间两两为负例。
正例:传递性(可以生成正例,负例); 句子本身作为相似问法,生成正例。(图特征???图里,距离太远的2个句子,设置阈值 应该为4,就不要构成正例了。)
负例:
含有UNK:把样本数据随机替换不存在于训练集的字符,构造一倍数据量,增强鲁棒性。
(问题: 最后构造了多少数据???? 正例,负例各8000, 训练集全部修改一个词,含UNK的2w个,共5w 6k数据)
2. embedding优化(优化完再输入模型)
3. char level embedding 比word好很多,中文很多新名词(word level)分词很不合理,
word embedding融入到char里面。让模型自己去学习怎么利用word级别的特征。可以很有用。
预训练 fine-tuning:
使用bert 微调词向量。。。
**1)Elmo:**再训练很有用,
词向量:在大型语料库预训练(学习一些常用的通用的词句表示),再对接特定任务数据集,再次训练,提升任务上的性能。
词向量: word2vec:静态词向量。
word2vec: 跳字模型(skip-gram, 类似于n-gram)和连续词袋模型(continuous bag of words,简称CBOW),以及两种近似训练法:负采样(negative sampling)和层序softmax(hierarchical softmax)。值得一提的是,word2vec的词向量可以较好地表达不同词之间的相似和类比关系。
elmo:动态词向量。
为时下最好的通用词和句子嵌入方法,来自于语言模型的词向量表示,也是利用了深度上下文单词表征,该模型的优势:
(1)能够处理单词用法中的复杂特性(比如句法和语义)
(2)这些用法在不同的语言上下文中如何变化(比如为词的多义性建模)
词向量不是一成不变的,而是根据上下文而随时变化, elmo的优势。
双向语言模型biLM的多层表示的组合,基于大量文本,ELMo模型是从深层的双向语言模型(deep bidirectional language model)中的**内部状态(internal state)**学习而来的,
传统词向量技术:(1)基于统计的方法,one-hot,tf/idf,n-gram
输入模型之前,直接拼接。
char- word如何结合?? 具体细节??简单的拼接??哪里拼接???(ok)
**交叉验证??? 四个模型投票,四个不太合适???**不止4个,最后得出的概率值,取加权平均,得出最终类别。
字词结合,4个模型中三个都有提升,四个模型进行融合投票得出最终结果,0.88














 2044
2044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









