







由一个题引发的小思考:

用一进程中线程不共享的部分应该是什嘛啊!!!
首先声明一点:
线程堆栈:简称栈 Stack
托管堆: 简称堆 Heap
线程共享的环境包括:进程代码段、进程的公有数据(利用这些共享的数据,线程很容易的实现相互之间的通讯)、进程打开的文件描述符、信号的处理器、进程的当前目录和进程用户ID与进程组ID。
进程拥有这许多共性的同时,还拥有自己的个性。有了这些个性,线程才能实现并发性。这些个性包括:
1,线程ID
每个线程都有自己的线程ID,这个ID在本进程中是唯一的。进程用此来标识线程。
2,寄存器组的值
由于线程间是并发运行的,每个线程有自己不同的运行线索,当从一个线程切换到另一个线程上 时,必须将原有的线程的寄存器集合的状态保存,以便将来该线程在被重新切换到时能得以恢复。
3,线程的堆栈(即就是:栈)
堆栈是保证线程独立运行所必须的。
线程函数可以调用函数,而被调用函数中又是可以层层嵌套的,所以线程必须拥有自己的函数堆栈, 使得函数调用可以正常执行,不受其他线程的影响。
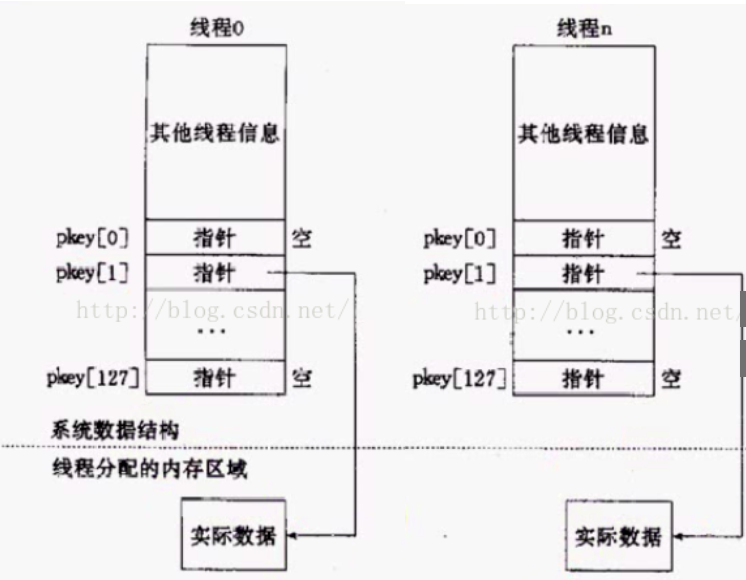
一个线程范围的私有全局变量,即使改变也不会对其它线程产生影响。Pÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









