






跨域任务(Domain Adaptation)主要研究如何在源域(有标签数据)和目标域(无标签或少量标签数据)分布不同的情况下,提升模型在目标域的泛化能力。由于源域和目标域的数据分布通常存在显著差异,直接应用源域训练的模型到目标域会导致性能大幅下降。这种分布差异,即“域偏移(domain shift)”问题,是跨域任务中的主要挑战。此外,如何在缺乏目标域标签的情况下有效学习、如何保证在源域学习到的知识能够迁移到目标域等,也是跨域任务中的广泛问题。在解决这些问题时,特征对齐是跨域任务中的关键步骤。特征对齐旨在缩小源域和目标域的特征分布差异,以减少域偏移。现有的特征对齐方法包括:基于统计量对齐,如最大均值差异(MMD)和CORAL,通过对齐均值和协方差来缩小分布差异;基于对抗学习的对齐,如DANN,通过对抗性域分类器来迫使源域和目标域的特征不可区分;基于子空间的对齐,如GFK,通过投影到共享子空间减少域间差异。此外,还有自监督学习和图匹配方法,通过无监督任务或图结构来实现对齐。
我们整理了2024年顶级学术会议中的部分最新跨域任务研究论文,这些论文深入探索了特征对齐的创新方法,提出了多种提升跨域任务性能的策略。
论文1
Domain-Agnostic Mutual Prompting for Unsupervised Domain Adaptation
方法:
传统的无监督领域自适应(UDA)技术致力于缩小不同领域数据分布的差异,却往往忽视了数据内蕴含的丰富语义信息,这在应对复杂的领域转换时构成了挑战。现有方法多侧重于通过文本提示来捕捉源域和目标域的特性,并独立执行分类任务,这限制了知识在不同领域间的流动。同时,仅对语言模型进行提示训练,也未能充分利用视觉和文本两种模态的互补优势。针对这些局限性,DAMP框架被提出,它通过同步优化视觉与文本嵌入,提取出不受领域限制的共有语义特征,从而促进了更深层次的跨领域知识迁移和特征融合。本文介绍的DAMP作为一种创新的UDA框架,依托于大规模预训练的视觉-语言模型,通过同步调整视觉与文本嵌入,学习到普适性的领域不变特征,显著提升了跨领域知识迁移的效能。
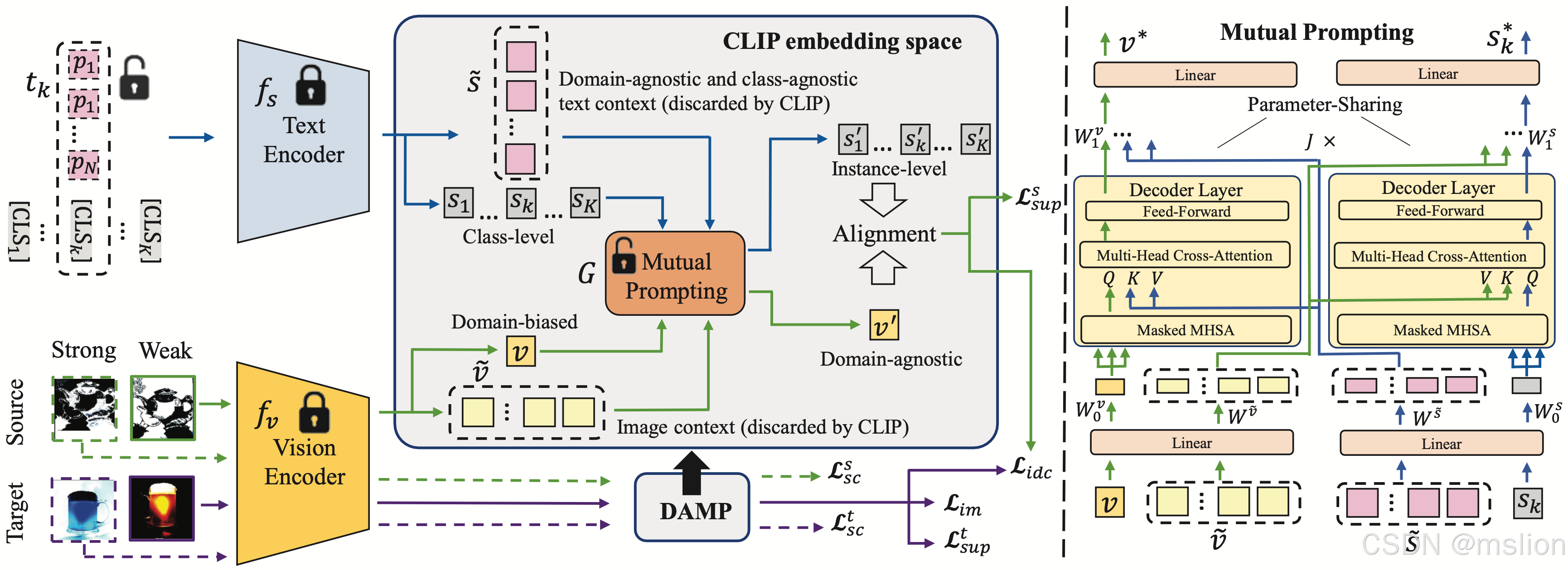
创新点:
(1) DAMP提出了一种新颖的框架,通过学习领域不可知的提示来有效利用预训练知识和源领域知识,以促进目标领域的适应。这种方法不依赖于特定领域的语义提示,而是寻求一种能够跨领域通用的语义表示。
(2) DAMP通过同时对视觉和文本嵌入进行提示,实现了模态间的相互对齐。具体来说,利用图像上下文信息来指导语言分支的提示,同时基于领域不可知的文本提示来引导视觉分支产生领域不变的视觉嵌入。这种双向对齐策略使得两种模态都能学习到领域不变的表示,从而更好地利用源域知识。
(3) 为了确保学习到的提示能够携带纯粹的领域不可知和实例相关的信息,DAMP引入了语义一致性正则化和实例区分对比损失两种辅助正则化。语义一致性正则化用于确保视觉嵌入的领域不变性,而实例区分对比损失则用于防止文本提示学习到视觉上下文中的领域特定线索,从而增强了跨领域迁移的能力。
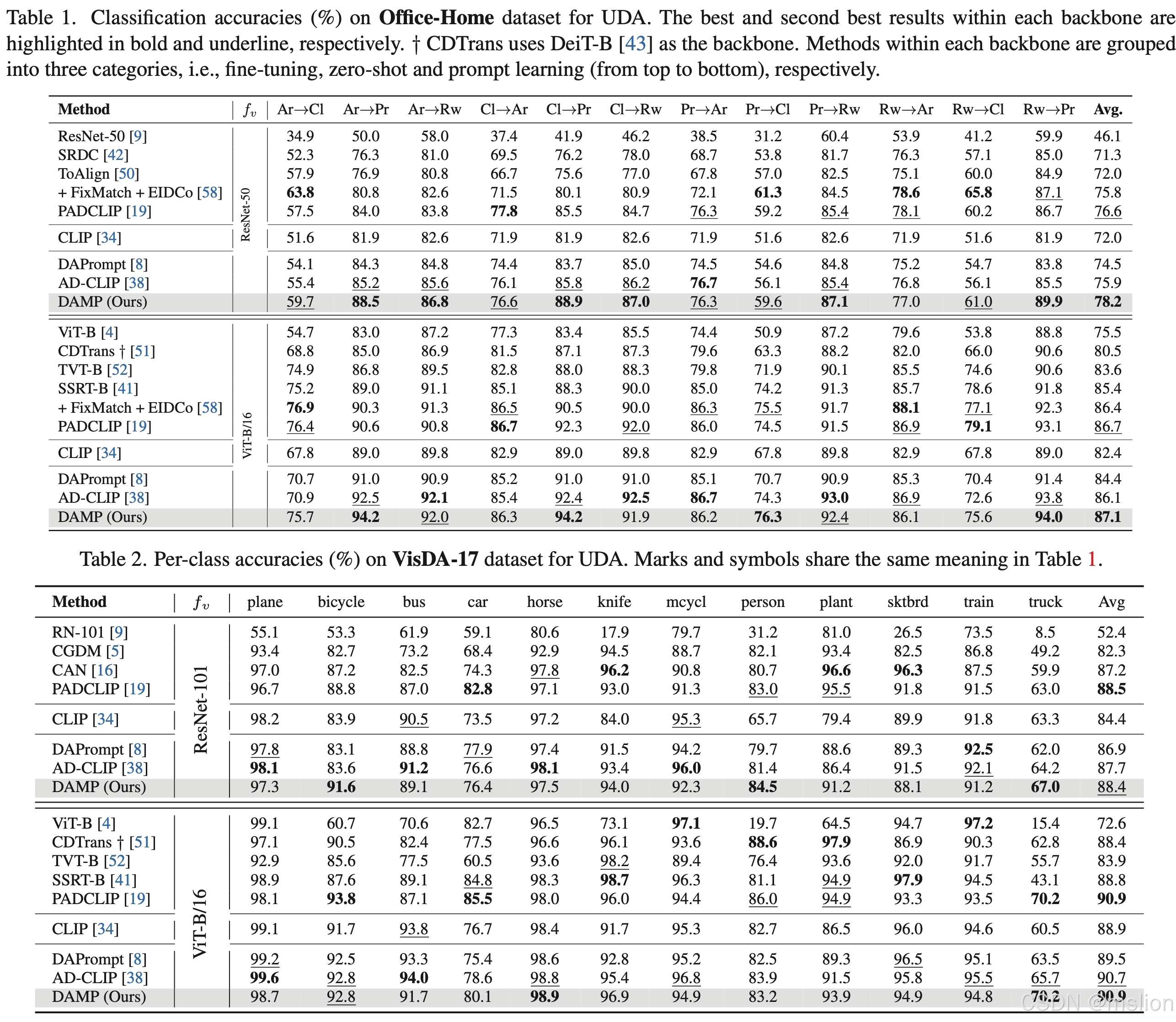
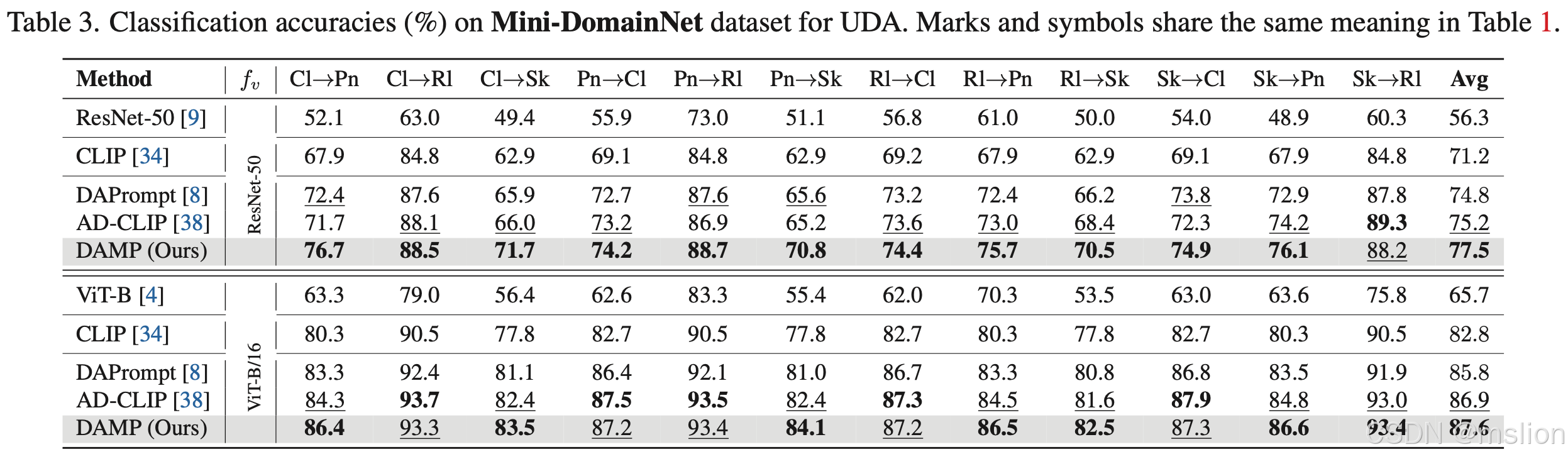
结果:
论文2
DiDA: Disambiguated Domain Alignment for Cross-Domain Retrieval with Partial Labels
方法:
随着生成式人工智能和互联网技术的飞速进步,我们见证了图像多样性和可用性的显著增长,这使得跨域图像检索成为了一项至关重要且广受欢迎的任务。尽管如此,传统图像检索技术在处理不同视觉领域时常常遭遇局限。为了应对这些挑战,跨域图像检索(CIR)领域应运而生,展现出巨大的发展潜力。在CIR的现有研究中,虽然依赖精确标注的标签能够带来卓越的性能,但这种标注方式往往成本高昂、耗时,并且需要专业知识。为了降低对精确标注的依赖,研究者们提出了无监督的CIR方法。然而,在缺乏标签或明确对应关系的情况下,这些方法的检索效果并不尽如人意。鉴于此,本研究提出了一种新的范式——部分标签的跨域图像检索(PCIR),旨在在减少标注成本和保持高性能之间找到平衡点。PCIR的核心在于,每个样本仅与一组候选标签相关联,而真实的标签则隐含其中。这种设置反映了现实世界跨域数据标注中普遍存在的标签歧义问题。本文的目标是解决如何在存在标签歧义的情况下,从部分标签中学习到具有区分性的特征表示,并同时克服不同领域间的固有差异。
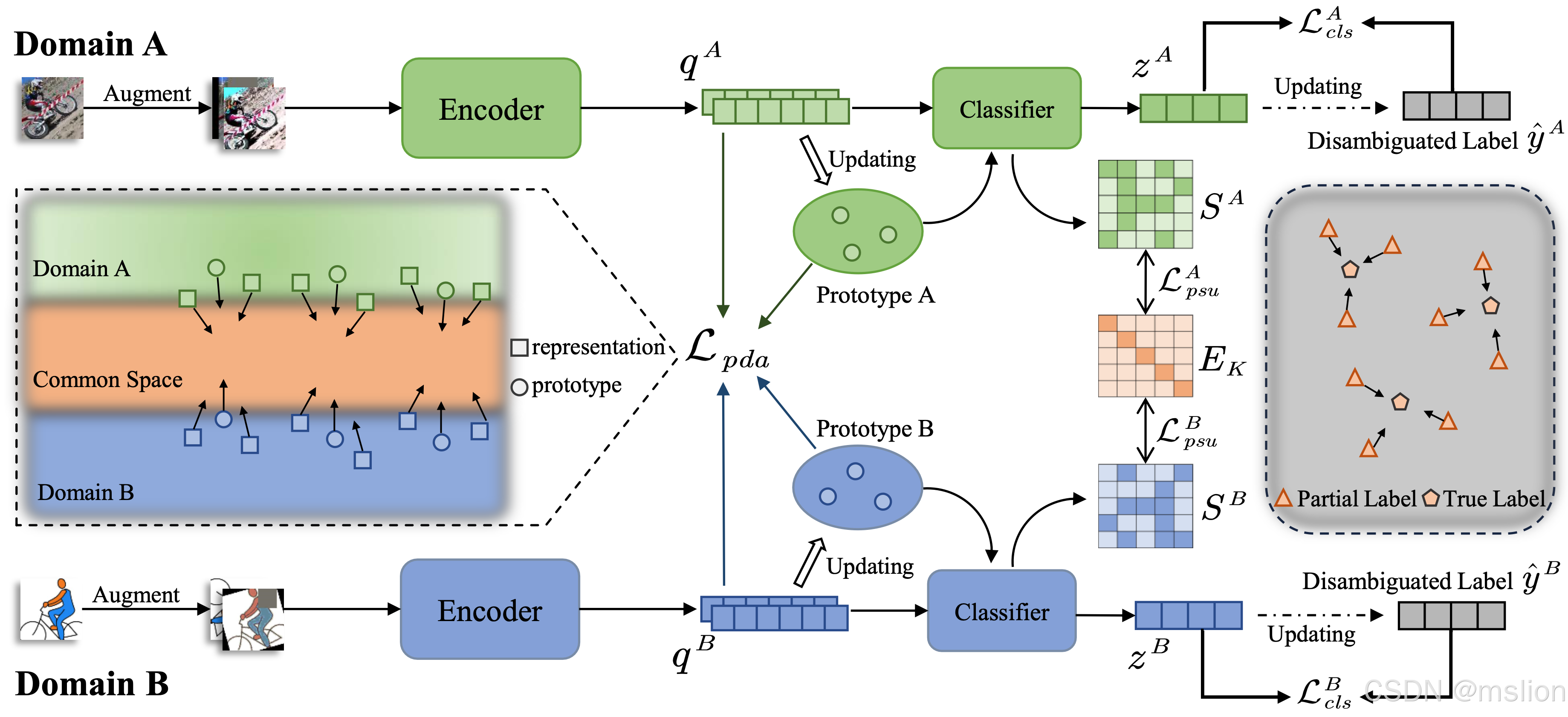
创新点:
(1) 这是首次提出的一种新方法,专门针对部分标签的跨域图像检索(PCIR)问题。DiDA 通过结合两种机制——原型-得分单元化学习(PSUL)和基于原型的域对齐(PBDA),来实现跨域检索任务。这种方法在减少标注成本的同时,提高了检索性能。
(2) PSUL 是一种新颖的学习机制,它通过将不同域的原型转化为原型-得分,并逐步将它们接近目标单位矩阵,从而同时实现标签消歧和缩小域间差距。这一过程不仅有助于桥接不同域的原型,而且促进了网络学习更准确的类别概率,从而推动了标签消歧。
(3) 为了进一步缩小跨域差距,PBDA 通过计算从不同域学到的表示与原型之间的相似性,并减少这些相似性之间的差异,来进一步缩小跨域差距。这种方法有助于模型更加关注不同域间的共同信息,使得不同域的表示和域特定的原型逐渐汇聚到共同的空间中。
结果:
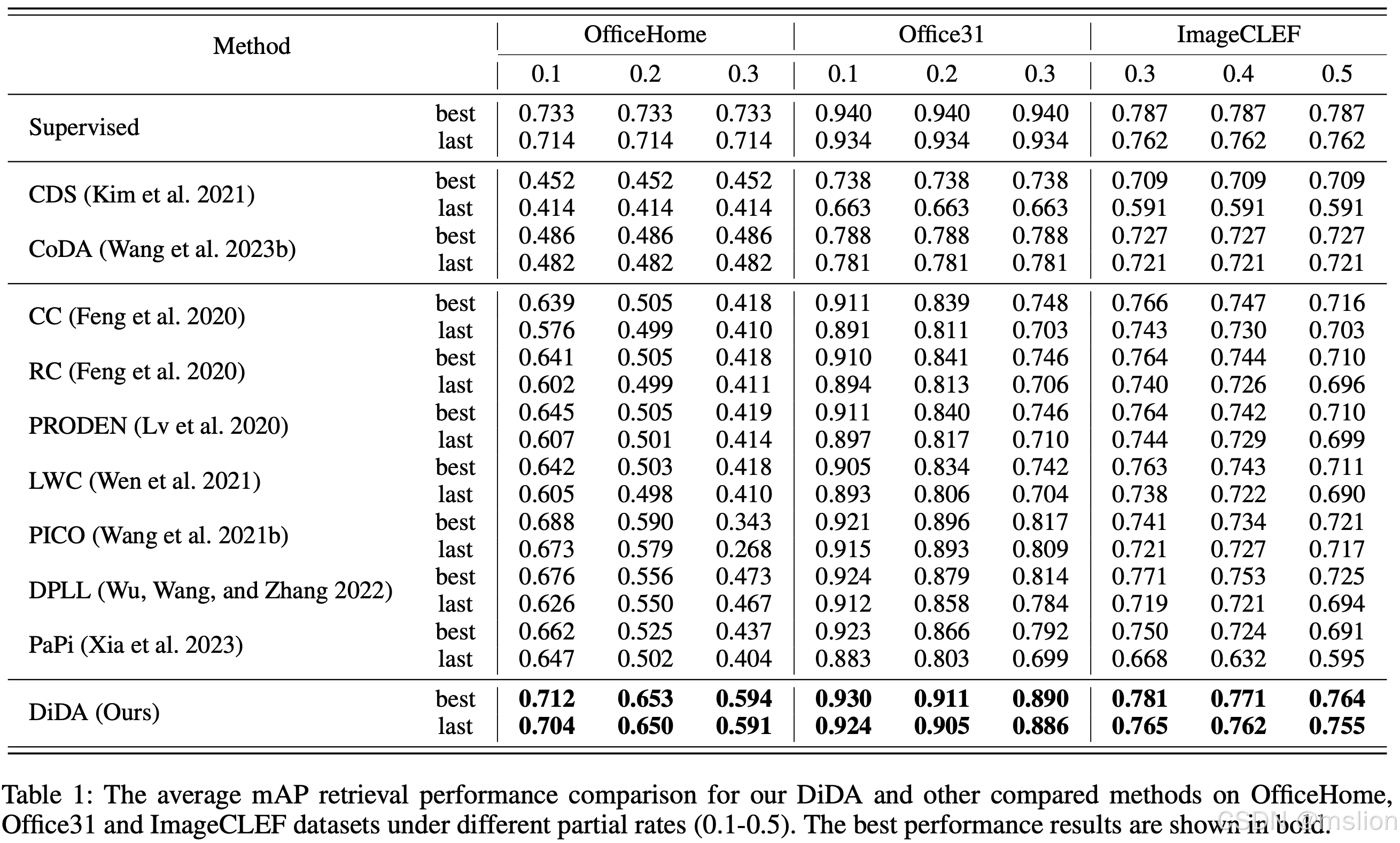
论文3
MmAP : Multi-Modal Alignment Prompt for Cross-Domain Multi-Task Learning
方法:
多任务学习(MTL)通过在单一网络架构下同时训练多个相关任务,旨在提升模型在各个任务上的性能。尽管这种方法在提升性能方面取得了成功,但它也面临着随着任务数量增加而导致解码器复杂性上升的挑战。传统的MTL方法主要关注于构建多任务模型训练框架,这些框架通常包括基于编码器或解码器的策略。这些策略往往需要为每个任务定制特定的解码器,从而导致模型的可训练参数数量随着任务数量的增加而线性增长。现有的参数高效迁移学习(PETL)方法主要针对预训练的视觉或语言模型,但当这些方法被应用于复杂的视觉-语言模型,如CLIP时,其效果并不总是理想。此外,这些PETL方法通常只关注单任务的适应性,而如何在多任务环境中有效应用这些方法仍然是一个未解决的问题。为了克服这些限制,本研究提出了一种创新的多模态对齐提示(MmAP)方法。MmAP通过在微调过程中同时对文本和视觉模态进行调整,以保持CLIP模型的模态一致性。此外,本文还开发了一个多任务提示学习框架,专门针对跨领域图像识别任务,旨在通过这种方法在保持参数效率的同时,实现显著的性能提升。
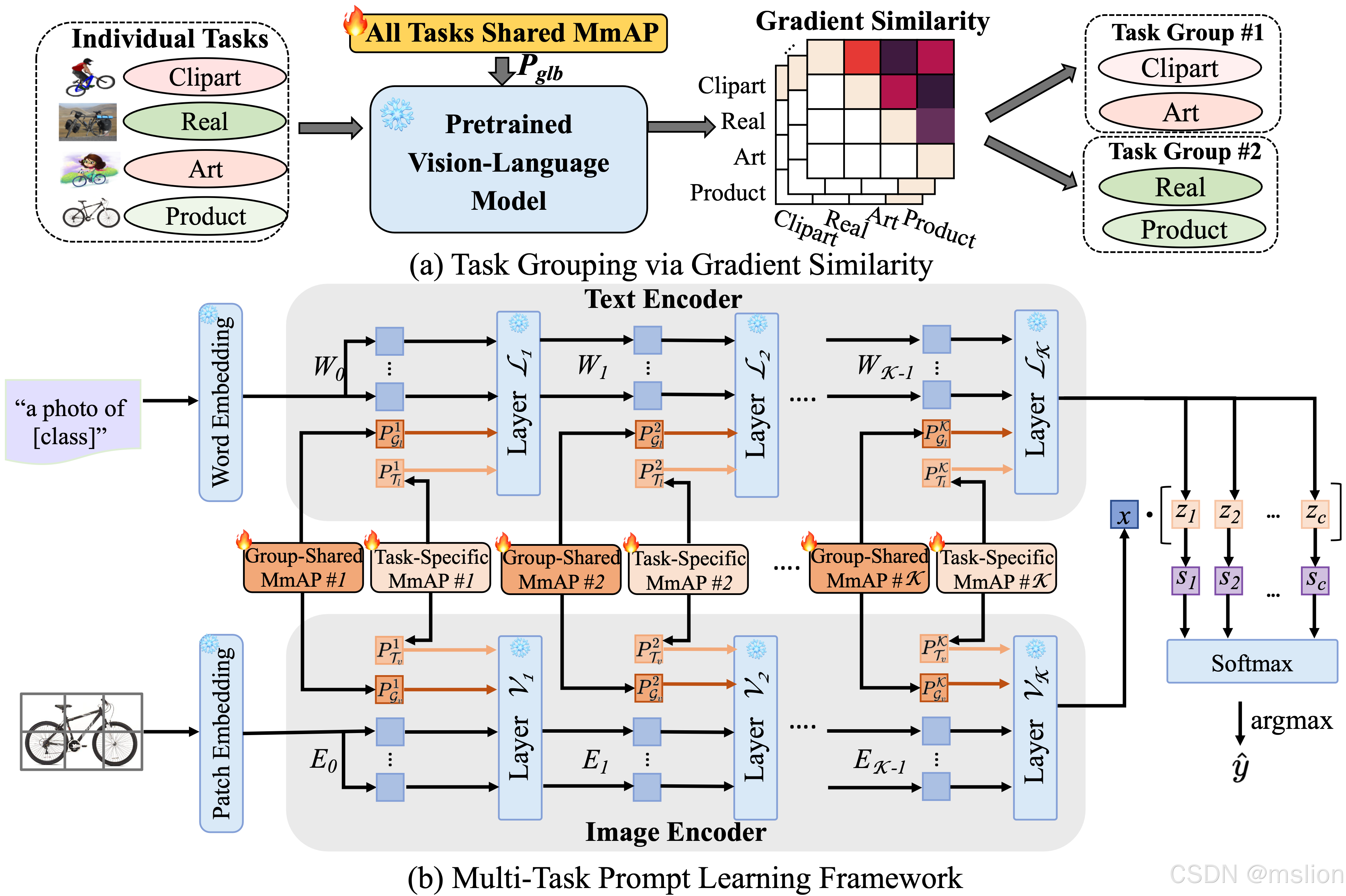
创新点:
(1) 文章首次提出了一种新的多模态对齐提示方法,用于在微调过程中同时调整文本和视觉模态。这种方法通过使用源提示生成文本提示和视觉提示,实现了对两种模态的对齐效果,同时显著减少了可训练参数的数量,提高了模型的效率并降低了过拟合的风险。
(2) 基于MmAP,文章开发了一个创新的多任务提示学习框架,该框架利用梯度相似性对任务进行分组,以最大化相似任务之间的互补性。每个任务组被分配一个共享的MmAP,以促进组内任务的共同学习和提升。同时,为了保持每个任务的独特特性,文章还为每个任务分配了特定的MmAP。
(3) 文章在两个大型跨领域多任务数据集上进行了实验,证明了所提出方法在保持参数效率的同时,相比全参数微调实现了显著的性能提升。这些实验结果展示了该方法在处理跨领域多任务学习问题时的有效性和优越性。
结果:
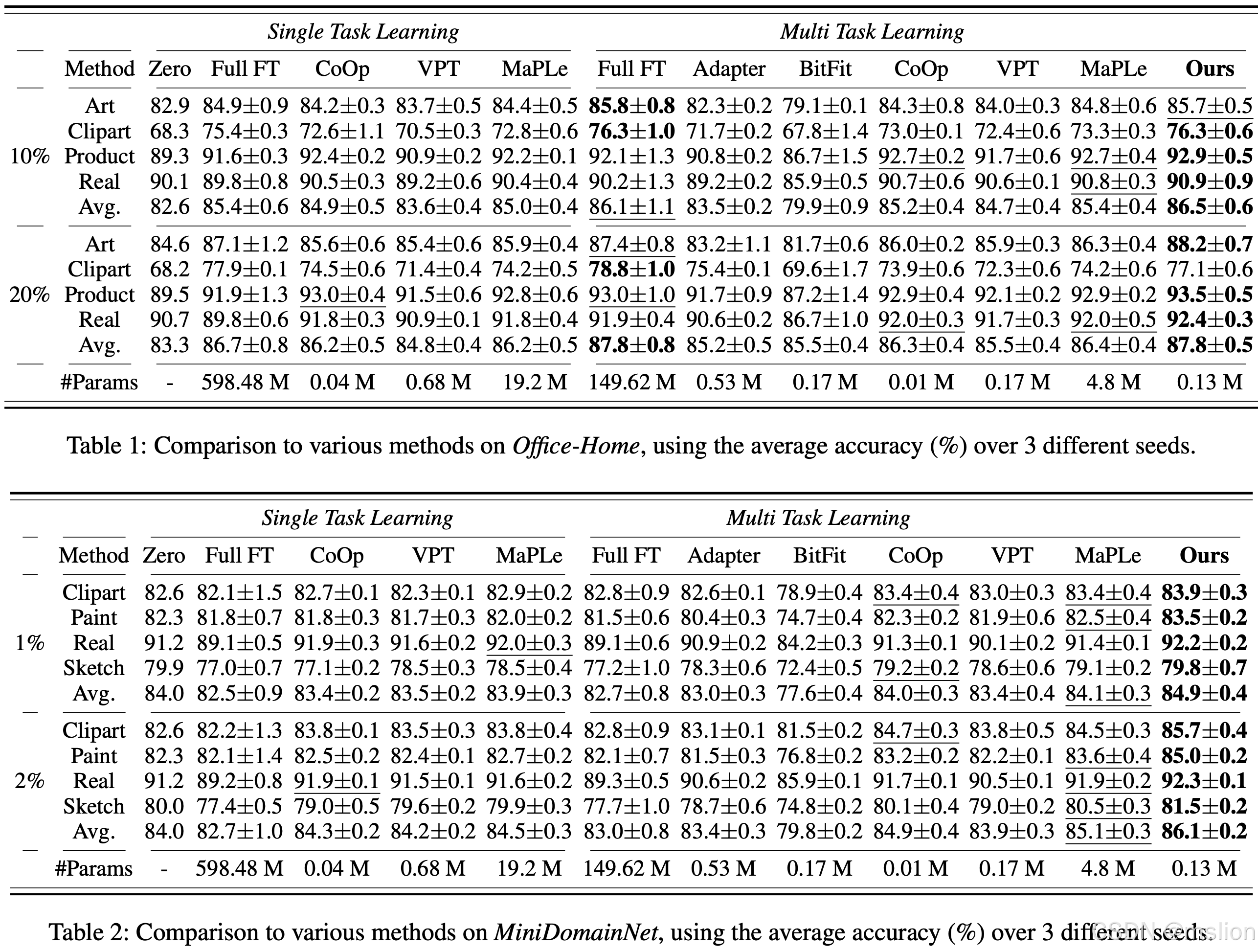
论文4
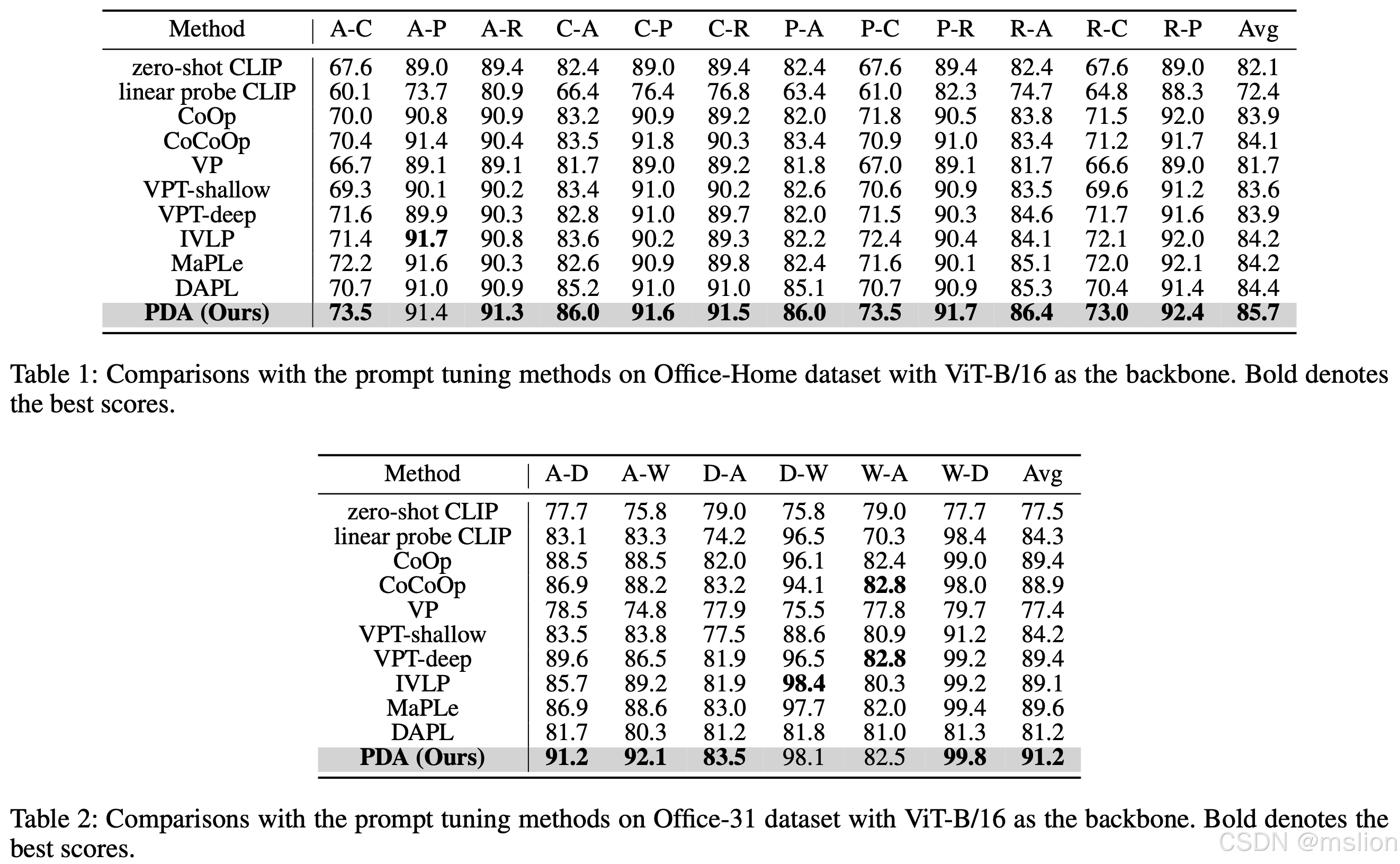
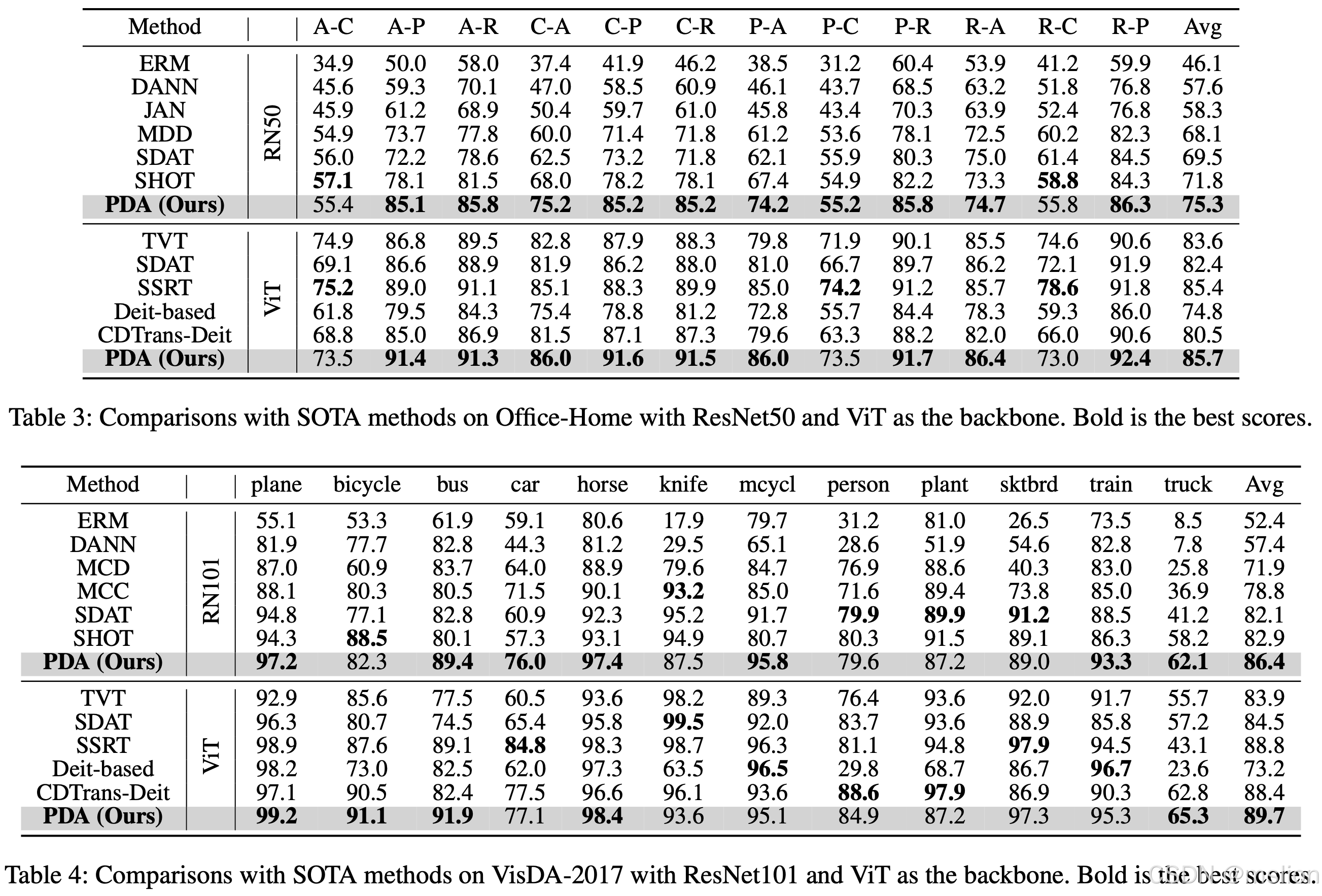
Prompt-Based Distribution Alignment for Unsupervised Domain Adaptation
方法:
尽管在多种下游任务中,大型预训练视觉-语言模型(VLMs)已经取得了显著的成功,但它们在现实世界中的无监督领域自适应(UDA)应用尚未被充分研究。在UDA领域,传统方法如对抗训练和度量学习虽然旨在减少源域与目标域之间的分布差异,但这些方法可能会在对齐过程中牺牲重要的语义信息。此外,尽管现有的提示调整技术,例如CoOp和MaPLe,在一些特定任务上取得了良好效果,但它们主要集中于优化提示的设置,并没有直接针对领域偏移的核心问题,因此可能无法完全克服这一挑战。鉴于此,本研究的动机是利用大型视觉语言模型,特别是CLIP模型,在下游任务中表现出的卓越泛化能力和其视觉与语义信息解耦的特性,来探索它们在UDA问题上的潜力。为了提高这些模型在UDA任务中的适应性和性能,作者提出了一种创新的提示调整方法——基于提示的分布对齐(PDA)。该方法通过将领域知识整合到提示学习过程中,旨在更有效地减少源域和目标域之间的分布差异,从而提升模型在UDA任务中的整体性能。
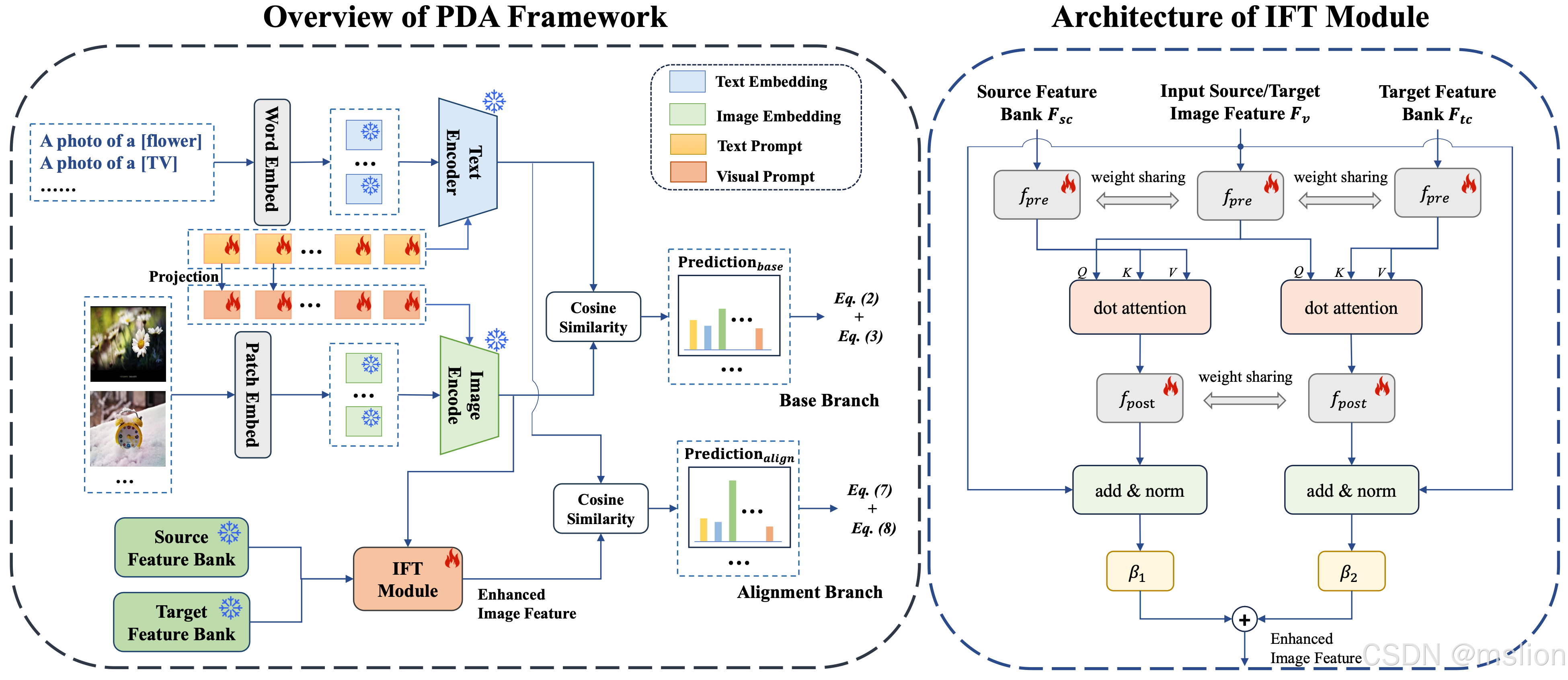
创新点:
(1) 文章提出了一种新颖的PDA方法,用于无监督领域自适应(UDA)。这种方法通过整合领域知识到提示学习中,不仅关注于提示的设计,还通过领域知识的融合来适应不同领域的特点,从而减少源域和目标域之间的分布差异。
(2) 不同类别之间的可区分性。对齐分支则利用图像表示来引入领域知识,通过构建源域和目标域的特征库,并提出图像引导的特征调整(IFT)策略,有效地整合了自增强和跨域特征,以实现领域对齐。
(3) 为了进一步减少领域差异,文章提出了IFT策略。该策略通过构建源域和目标域的特征库,并使输入图像的特征向这些特征库学习,从而有效地整合了自增强和跨域特征。这种方法不仅提高了图像和文本表示的区分度,而且有效地降低了领域差异,增强了模型对目标域的适应性。
结果:

















 1537
1537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









