








目录
最近有同学问:“Kimi 为啥这么火?其他大模型似乎没有它那么好用,原因何在?”
答案在于其卓越的长文本处理能力。
01 Kimi的独特之处
Kimi作为自研大模型,在基座模型领域独树一帜。多数厂商遵循OpenAI路径,即增加参数规模与多模态功能。然而,Kimi认识到,当前阶段,模型参数虽大,但真正决定效能的是其处理复杂问题的能力。其核心在于“注意力机制(Transformer)”,它如同鱼的记忆,专注于有限范围的上下文信息。
阅读理解能力的三大支柱:
-
高智商与强推理:模型需具备大规模参数与强大推理能力。
-
丰富的预训练语料:通过高质量数据提升模型对各类问题的熟悉度。
-
长上下文处理能力:这是多数厂商忽视的关键,而Kimi则视为核心。
02 Kimi的解题思路
突破常规,专注长上下文。Kimi不走寻常路,强调实际任务中的上下文需求。它认为,仅依赖高智商和丰富语料不足以应对所有挑战,关键在于提供足够的上下文空间。正如开卷考试,Kimi选择了一张大桌子,将所有材料平铺其上,确保信息全面且易于整合。
其他厂商通过工程手段和外挂方式处理长文本,如同从背包中挑选材料拼凑答案,受限于桌子大小(即上下文长度)。而Kimi则直接提供了更大的“桌面”,让答案更加全面和准确。
03 长上下文的优势
引领长文本处理新纪元。Kimi在长文本处理上已走在世界前列,超越了chatGPT和Claude等竞品。其长上下文能力极大提升了处理复杂文档(如论文、调研报告、技术文档)的效率,减少了遗忘和重复说明的需要,使得许多原本需要人工协助的任务变得自动化。
为何其他厂商不跟进?原因在于成本。长上下文意味着更多的token消耗,从而增加了成本。但Kimi的成功证明,这一投入带来了显著的用户体验和效率提升。
总之,Kimi凭借其独特的长上下文处理能力,赢得了用户的青睐,成为大模型领域的佼佼者。
04 是否只是营销
kimi是真的牛还是只是营销厉害,200万长度无损上下文是真的吗。
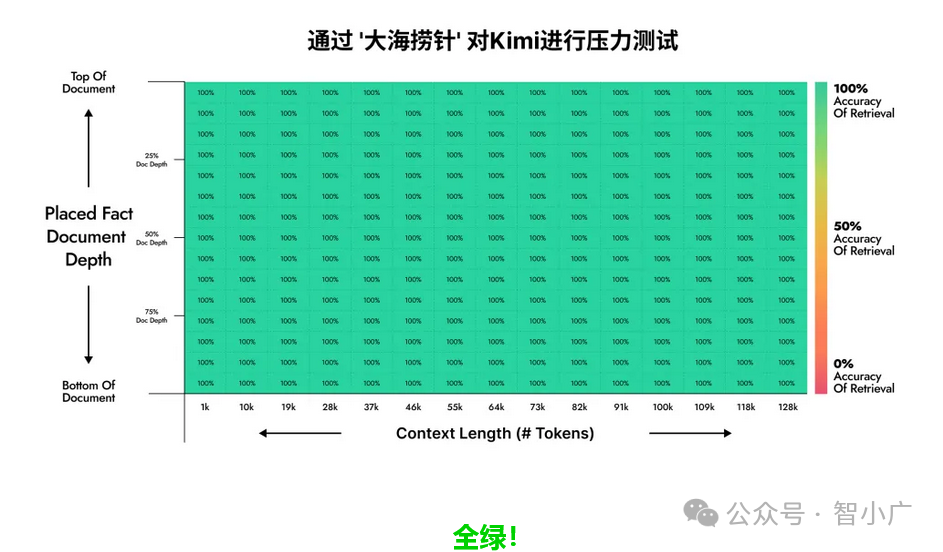
一位AI大模型领域的开发者设计了一个名为“大海捞针”的大模型长文本性能测试方法:
在文本语料中藏入一个不相关的句子(比如整本《西游记》里放入一句鸡你太美),然后看大模型能不能通过自然语言提问的方式(Prompt)把这句话准确地提取出来。
GPT-4 Turbo(128K)在语料长度超过 72K 且句子(“针”)藏在文本头部的时候,准确率不佳。
Claude 2.1似乎在语料长度超过 20K 之后就开始准确率不佳,而且句子(“针”)藏在语料靠前的位置时,准确率尤其差。
而Kimi Chat 在“大海捞针”实验中的测试结果是这样的
05 结语
随着大模型的发展,agent应用以及长上下文解读能力的重要性凸显出来,大模型也从最初的4k-->8k-->32k-->128k-->200k,各家厂商都有自己的一套解决方案,其中kimi的长度比较出众,当然这种闭源大模型我们没办法知道到底用了什么技术,但是开放这么长的上下文给用户免费使用,称一句国货之光不过分了。
更多智讯、智思、智识,点个关注吧!

感谢您的分享,点赞,在看三连,欢迎转发,分享


















 2757
2757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











