







Java线程相关的类和接口大多在java.util.concurrent包下面,线程池的创建可以通过Executors定义的一些类方法获取各种线程池实例。
- newSingleThreadExecutor:创建一个单线程执行程序,它可安排在给定延迟后运行命令或者定期地执行
- newScheduledThreadPool:创建一个定长线程池,支持定时及周期性任务执行。
- newSingleThreadScheduledExecutor:根据时间计划延迟创建单个工作线程 ExecutorService(或者周期性的创建)
- newFixedThreadPool :创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
- newCachedThreadPool:创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
- newWorkStealingPool:jdk1.8新增,创建持有足够线程的线程池来支持给定的并行级别,并通过使用多个队列,减少竞争,它需要穿一个并行级别的参数,如果不传,则被设定为默认的CPU数量。
newSingleThreadExecutor
首先,newSingleThreadExecutor有两个 。返回类型为ExecutorService接口,该接口继承自Executor接口,Executor接口提供了一个execute()方法,用于创建线程。ExecutorService接口则提供了一系列方法来管理线程池。

先看一个最简单的实现:
private static void singleThreadExecutor(){
//创建一个单线程的线程池
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
for (int i = 0; i < 10; i++) {
final int index = i;
//执行具体任务
singleThreadExecutor.execute(new Runnable() {
@Override
public void run() {
try {
System.out.println(Thread.currentThread().getName()+"线程执行中....,index:"+index);
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}上面的代码通过Executors.newSingleThreadExecutor()创建了一个线程池。然后通过execute()方法接受一个Runnable的实例(若需要线程可以有返回值,可以使用submit()方法,该方法会返回Future对象,这是ExecutorService接口提供的扩展方法。),创建线程。
执行结果,通过jdk提供的jconsole工具可以查看jvm线程的情况:
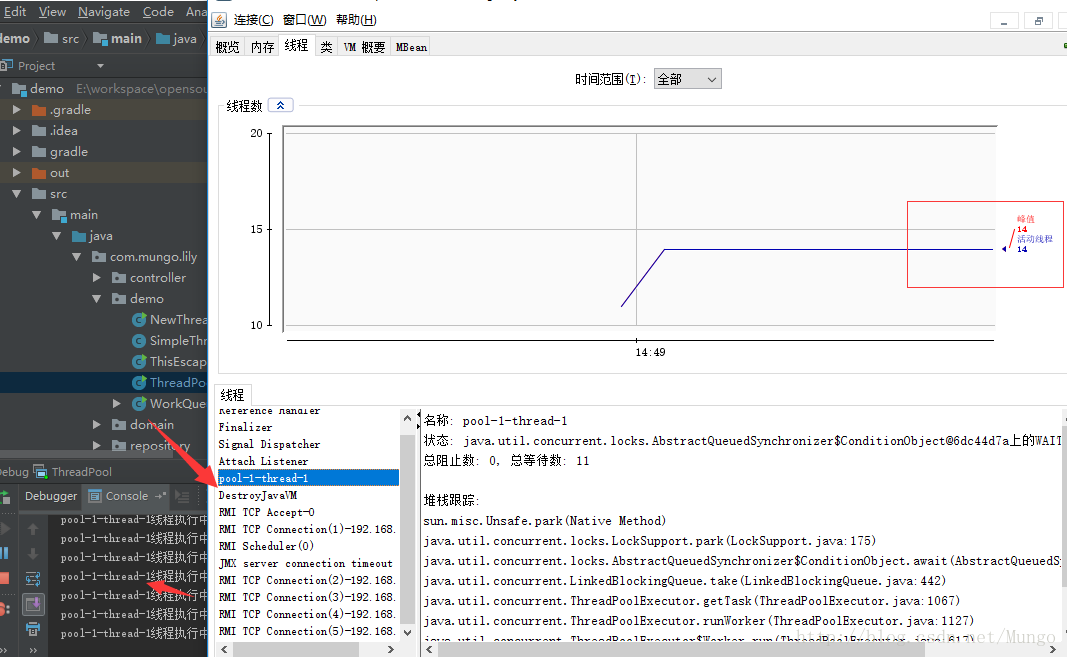
至于线程的名称为什么为“pool-1-thread-1”,可以通过查看源码慢慢找到。
下面,通过源码,了解下线程池的具体实现。
在查看newSingleThreadExecutor的源码实现时,可以了解到,newSingleThreadExecutor是通过实现ThreadPoolExecutor对象创建线程池的。
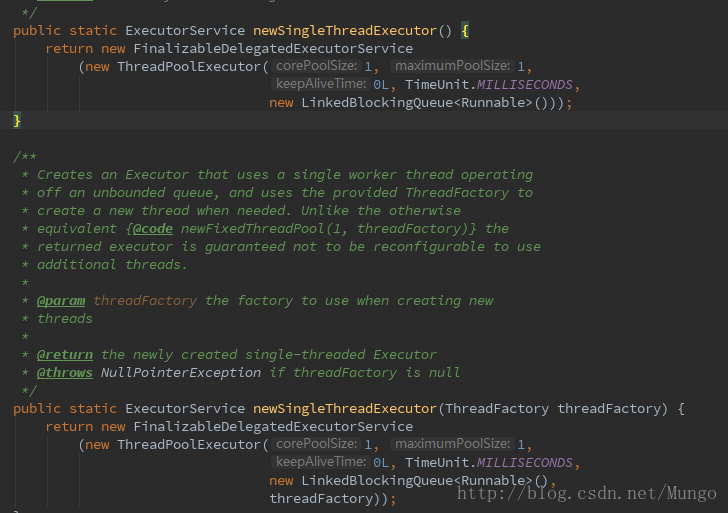
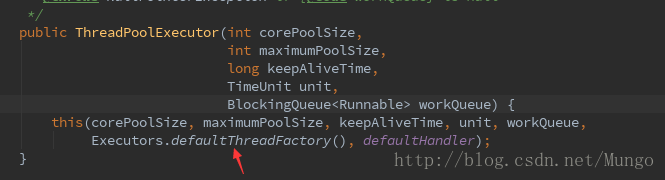
在ThreadPoolExecutor构造方法中,可以通过Executors.defaultThreadFactory()创建一个ThreadFactory接口的对象。
defaultThreadFactory:

DefaultThreadFactory:
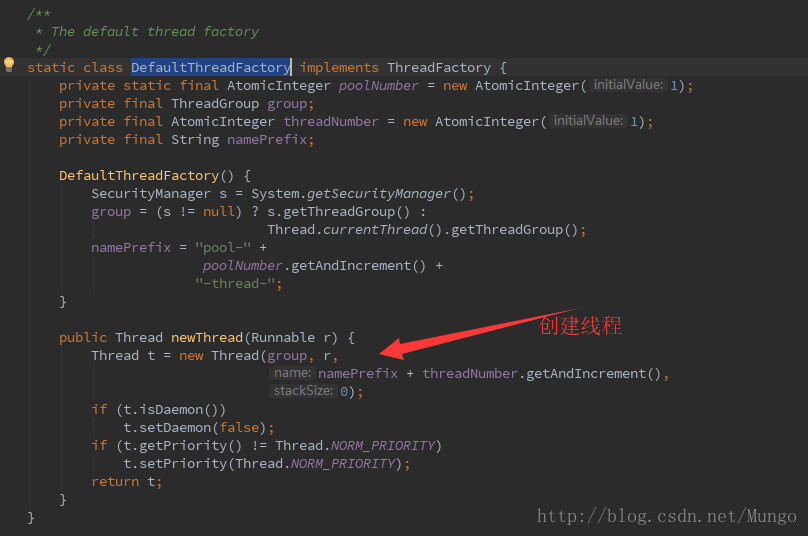
通过这里的实现也可以知道,为什么创建的线程名称为”pool-1-thread-1”了,因为在newThread()方法中,创建线程是设置了线程的name。
这里,再说newSingleThreadExecutor另一种重载方式,就是接收一个ThreadFactory对象。ThreadFactory通过名称就可以知道,是一个线程工厂接口。它的接口定义只有一个方法–创建一个线程:
Thread newThread(Runnable r);ThreadFactory通常用于创建自定义的线程。具体就不在举例,可以参见jdk中的默认实现defaultThreadFactory。
newScheduledThreadPool
根据时间计划,延迟给定时间后创建 ExecutorService(或者周期性地创建 ExecutorService)。
newScheduledThreadPool方法也有两种重载方式,一个是接受一个int参数,用于指定创建线程池中保留线程的数量。另一个是指定线程池保留线程的数量的同时,可以接受一个自定义的ThreadFactory对象。同时,newScheduledThreadPool 返回的是ScheduledExecutorService接口,ScheduledExecutorService接口继承了ExecutorService接口。

ScheduledExecutorService接口额外提供了一下方法:

通过这些方法,可以实现线程池里线程的延迟启动,周期执行等。
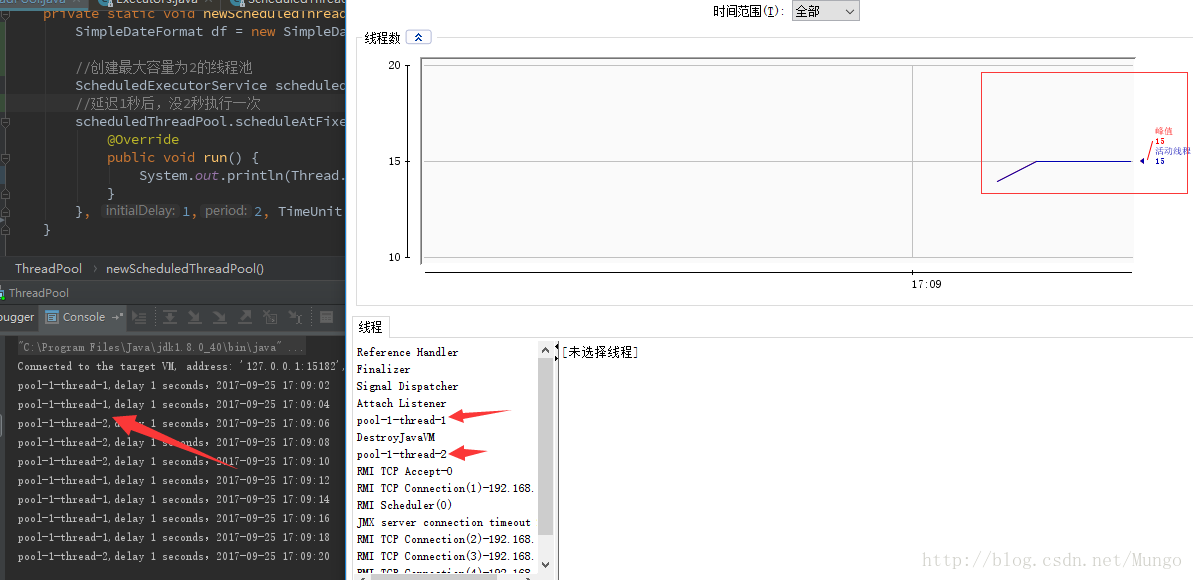
private static void newScheduledThreadPool(){
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
//创建最大容量为2的线程池
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(2);
//延迟1秒后,每2秒执行一次
scheduledThreadPool.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+",delay 1 seconds,"+df.format(System.currentTimeMillis()));
}
}, 1,2, TimeUnit.SECONDS);
}
newScheduledThreadPool的这个特性,使得他可以替代java的定时器Timer实现定时任务。
newSingleThreadScheduledExecutor
通过它的定义可知,newSingleThreadScheduledExecutor返回一个ScheduledExecutorService 对象,并且默认实现了最大容量为1的ScheduledThreadPoolExecutor对象。
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}因此它和Executors.newScheduledThreadPool(1)是等价的。
newFixedThreadPool
创建一个可重复使用的、固定线程数量的 ExecutorService。
newFixedThreadPool 方法也有两种重载方式,一个是接受一个int参数,用于指定创建线程池的大小。另一个是指定线程池大小的同时,可以接受一个自定义的ThreadFactory对象。

private static void fixedThreadPool(int size){
//创建一个大小为size的线程的线程池
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(size);
for (int i = 0; i < 10; i++) {
final int index = i;
//创建线程,执行具体任务
fixedThreadPool.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+",正在执行....,index:"+index);
}
});
}
}上面的代码在执行时创建了大小为6的固定线程池。
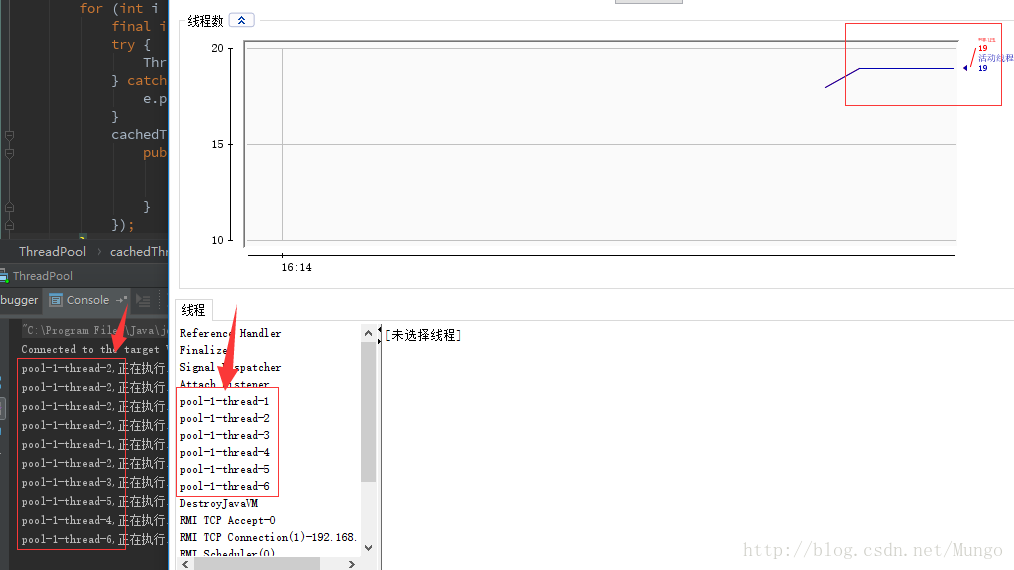
通过对执行结果的监控发现,线程峰值总数为19,上面在使用newSingleThreadExecutor创建单线程池时进程数峰值为14,正好相差5个。
对于执行的线程任务,同样是执行10次,通过执行的结果可以发现有些线程被重复使用了。
newCachedThreadPool
通过名称就可以知道,这是创建一个可缓存的线程池。即可以重复利用已存在的线程来执行任务。返回的也是一个ExecutorService对象。所以,这种方式创建的线程池会先查看池中有没有以前建立的线程,如果有,就 重用。如果没有,就建一个新的线程加入池中。

private static void cachedThreadPool(){
//线程池创建
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
final int index = i;
//线程调用
cachedThreadPool.execute(new Runnable() {
public void run() {
try {
Thread.sleep( index*1000);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+",index:"+index);
}
});
try {
Thread.sleep( 2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}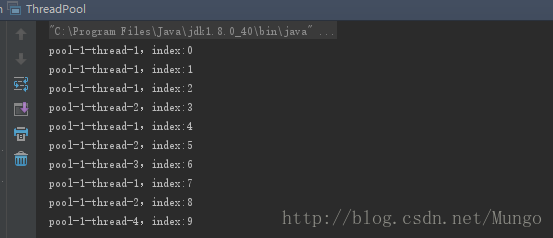
可以看出,有些线程像pool-1-thread-1和pool-1-thread-2被调用了多次,execute会在执行时首先在线程池中随机选择一个已有空闲线程来执行任务,如果线程池中没有空闲线程,便会创建一个新的线程来执行任务。
newWorkStealingPool
newWorkStealingPool是JDK1.8后新增的方法,可以创建一个带并行级别的线程池,并行级别决定了同一时刻最多有多少个线程在执行,所以它的两种重载模式中参数int就是并行级别。不传的话将默认为当前系统的CPU个数。

为了体现这种特性,这里使用带返回值得线程模拟。返回的结果为线程名称和执行时间。
关于线程的创建可以参见:多线程/并发笔记:线程创建的三种方式
private static void workStealingPool() throws InterruptedException {
ExecutorService workStealingPool = Executors.newWorkStealingPool();
List<Callable<String>> callables = new ArrayList<>();
for (int i = 1; i <= 10; i++) {
final int count = i;
Callable call = new Callable() {
@Override
public Object call() throws Exception {
Date now = new Date();
Thread.sleep(1000);//此任务耗时1s
return "线程" + Thread.currentThread().getName() + "完成任务:"
+ count + " 时间为:" + now.toLocaleString();
}
};
callables.add(call);
}
//JDK1.8写法,打印执行结果
//invokeAll可以批量提交一组线程
workStealingPool.invokeAll(callables)
.stream()
.map(future -> {
try {
return future.get();
}
catch (Exception e) {
throw new IllegalStateException(e);
}
})
.forEach(System.out::println);
}执行结果:
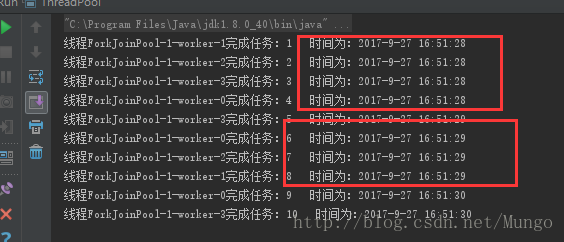
可以看到,对于批量提交的10个任务,同一时间执行有四个执行。这是因为我的CPU是4核的。
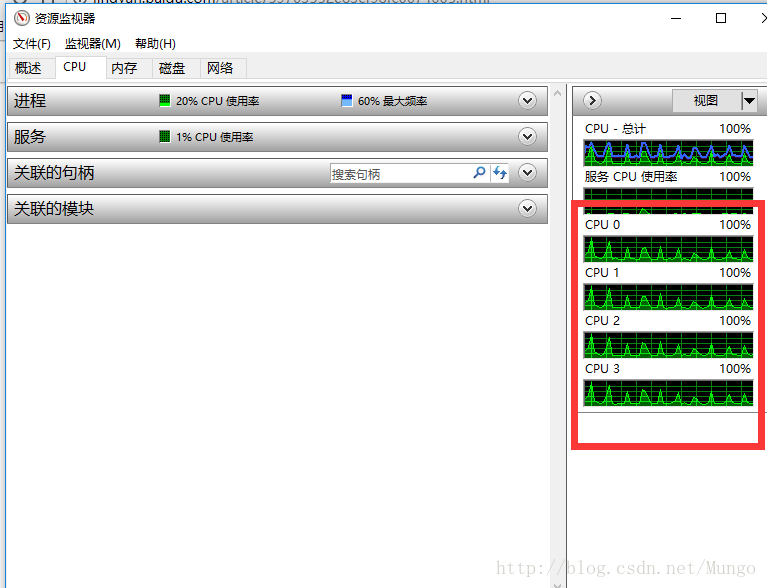
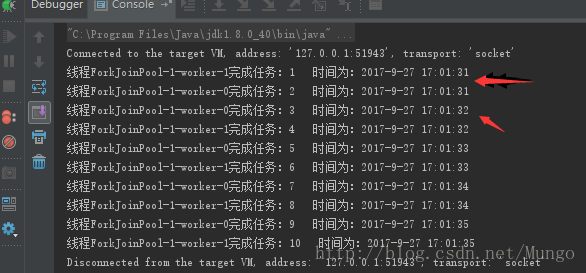
将上面的代码改为:
ExecutorService workStealingPool = Executors.newWorkStealingPool(2);执行结果就是:
对于newWorkStealingPool的实现,其实已经不载是Executor框架下的了,查看它的实现方式就会发现:
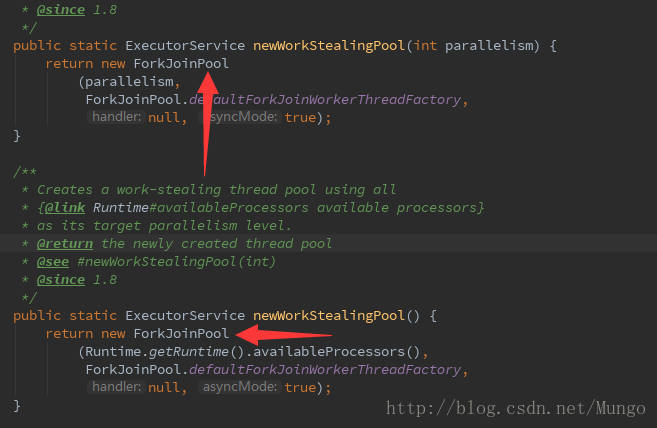
使用的ForkJoinPool的方式创建线程池,这是java多线程的另一个模型了Fork/Join模型。简而言之,就是将任务分成小任务执行,最终整合每个子任务的结果。限于篇幅,下回分解。















 2193
2193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









