






目录
一.模型简介
SSD是一种基于深度学习的目标检测算法,由google于2016年提出。它有三个优点:
1. 速度快。它采用单阶段检测,可以直接在一张图像上完成目标检测,所以速度快。
2. 精度高。它采用多尺度特征图进行检测,可以检测不同大小的目标,因此精度比较高。
3. 简单易用。它只需要一张图像和一个预训练模型,就可以进行目标检测,使用起来非常简单。
SSD模型主要由两部分组成:特征提取网络和检测网络。特征提取网络通常采用VGG、ResNet等
经典的卷积神经网络,用于提取图像的特征。检测网络则是在特征提取网络的基础上,通过多个卷积层和全连接层来预测目标的类别和位置。
二. 环境准备
本地已经安装了mindspore、download、pycocotools、opencv-python。
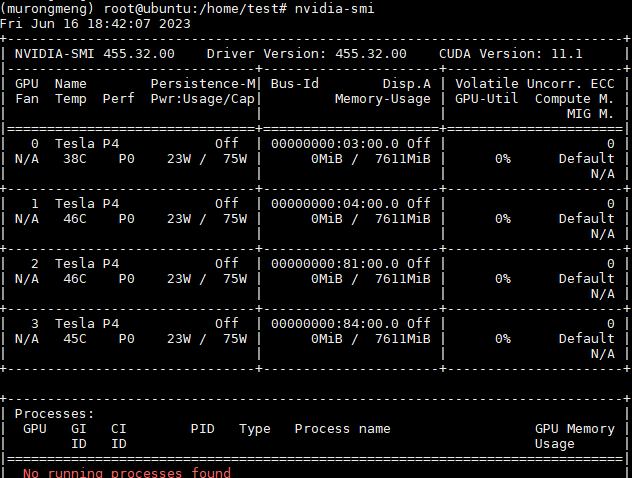
nvidia-smi CUDA Version: 11.1
uname -a

python
mindspore包安装

三. 数据准备
https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/ssd_datasets.zip
上传到linux机器
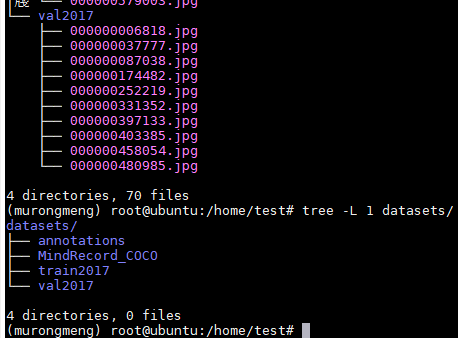
tree -L 1 datasets/
四. 测试脚本准备
五.网络结构
SSD的网络结构主要分为以下几个部分:
-
基础网络
-
特征层
-
检测层
-
全局池化层
-
先验框
六. 模型训练
数据处理,位置是一样的,所以不用改变代码
# 首先我们为数据处理定义一些输入:
# In[3]:
coco_root = "./datasets/"
anno_json = "./datasets/annotations/instances_val2017.json"
train_cls = ['background', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant',
'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog',
'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra',
'giraffe', 'backpack', 'umbrella', 'handbag', 'tie',
'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard',
'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup',
'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed',
'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote',
'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink',
'refrigerator', 'book', 'clock', 'vase', 'scissors',
'teddy bear', 'hair drier', 'toothbrush']
train_cls_dict = {}
for i, cls in enumerate(train_cls):
train_cls_dict[cls] = i
执行脚本

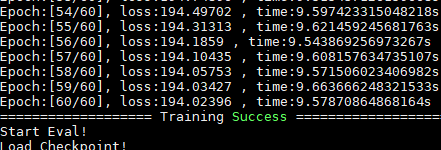
1.log 训练数据
=================== Starting Training =====================
Epoch:[1/60], loss:1083.8347 , time:15.521977424621582s
Epoch:[2/60], loss:1074.3134 , time:9.689213275909424s
Epoch:[3/60], loss:1057.44 , time:9.678734064102173s
Epoch:[4/60], loss:1039.427 , time:9.728736639022827s
Epoch:[5/60], loss:1021.02637 , time:9.801356554031372s
Epoch:[6/60], loss:1002.31433 , time:9.624170303344727s
Epoch:[7/60], loss:983.1155 , time:9.784408807754517s
Epoch:[8/60], loss:963.1195 , time:9.79171371459961s
Epoch:[9/60], loss:941.9223 , time:9.728365182876587s
Epoch:[10/60], loss:919.0378 , time:9.72029733657837s
Epoch:[11/60], loss:893.9181 , time:9.657977819442749s
Epoch:[12/60], loss:865.9906 , time:9.665978908538818s
Epoch:[13/60], loss:834.72266 , time:9.619809865951538s
Epoch:[14/60], loss:799.7191 , time:9.632071018218994s
Epoch:[15/60], loss:760.8431 , time:9.649034261703491s
Epoch:[16/60], loss:718.3388 , time:9.696301221847534s
Epoch:[17/60], loss:672.9095 , time:9.596276760101318s
Epoch:[18/60], loss:625.7059 , time:9.584611654281616s
Epoch:[19/60], loss:578.19836 , time:9.59845781326294s
Epoch:[20/60], loss:531.9502 , time:9.667635202407837s
Epoch:[21/60], loss:488.36118 , time:9.62756872177124s
Epoch:[22/60], loss:448.46704 , time:9.713463068008423s
Epoch:[23/60], loss:412.85098 , time:9.570287942886353s
Epoch:[24/60], loss:381.6697 , time:9.700335502624512s
Epoch:[25/60], loss:354.75372 , time:9.594876527786255s
Epoch:[26/60], loss:331.7303 , time:9.543512105941772s
Epoch:[27/60], loss:312.13287 , time:9.661614179611206s
Epoch:[28/60], loss:295.47852 , time:9.605469226837158s
Epoch:[29/60], loss:281.31424 , time:9.696396112442017s
Epoch:[30/60], loss:269.2391 , time:9.596375226974487s
Epoch:[31/60], loss:258.91083 , time:9.609665632247925s
Epoch:[32/60], loss:250.0431 , time:9.659202337265015s
Epoch:[33/60], loss:242.39995 , time:9.593588590621948s
Epoch:[34/60], loss:235.78778 , time:9.655600786209106s
Epoch:[35/60], loss:230.04816 , time:9.514032363891602s
Epoch:[36/60], loss:225.05148 , time:9.629486322402954s
Epoch:[37/60], loss:220.69133 , time:9.58655834197998s
Epoch:[38/60], loss:216.87991 , time:9.614134073257446s
Epoch:[39/60], loss:213.54451 , time:9.63001537322998s
Epoch:[40/60], loss:210.62444 , time:9.609678506851196s
Epoch:[41/60], loss:208.0689 , time:9.576202630996704s
Epoch:[42/60], loss:205.83487 , time:9.682623147964478s
Epoch:[43/60], loss:203.88579 , time:9.56165599822998s
Epoch:[44/60], loss:202.19019 , time:9.513842344284058s
Epoch:[45/60], loss:200.72116 , time:9.528319120407104s
Epoch:[46/60], loss:199.45474 , time:9.555673599243164s
Epoch:[47/60], loss:198.37012 , time:9.589282035827637s
Epoch:[48/60], loss:197.44879 , time:9.649118661880493s
Epoch:[49/60], loss:196.6738 , time:9.592345476150513s
Epoch:[50/60], loss:196.03006 , time:9.600049018859863s
Epoch:[51/60], loss:195.5033 , time:9.587400674819946s
Epoch:[52/60], loss:195.08035 , time:9.510307312011719s
Epoch:[53/60], loss:194.74896 , time:9.515437126159668s
Epoch:[54/60], loss:194.49702 , time:9.597423315048218s
Epoch:[55/60], loss:194.31313 , time:9.621459245681763s
Epoch:[56/60], loss:194.1859 , time:9.543869256973267s
Epoch:[57/60], loss:194.10435 , time:9.608157634735107s
Epoch:[58/60], loss:194.05753 , time:9.571506023406982s
Epoch:[59/60], loss:194.03427 , time:9.663666248321533s
Epoch:[60/60], loss:194.02396 , time:9.57870864868164s
=================== Training Success =====================
七. 模型评估
SSD用eval_net()对训练好的模型进行评估,输出的指标有三个
1. AP:精确率(Average Precision,AP)
公式是:
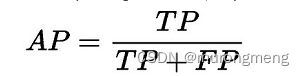
AP: 指在不同的召回率下,模型的平均精度值。通常使用AP50和AP75来评估模型的性能。
2. AR:召回率(Average Recall,AR)
公式:
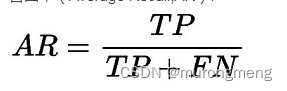
AR:指模型能够正确检测到所有正样本的能力
3. map: (mean Average Precision) 各类别AP的平均值
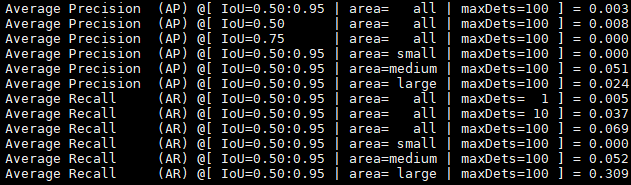

体验结束~















 1054
1054











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









