







SSD目标检测理论与代码
前言
我是照着bubbling大佬的pytorch-ssd代码走了一遍,因此我会在他的代码的基础上去进行我的各种理解,大家可以去看看他关于SSD的教学博客—>睿智的目标检测23——Pytorch搭建SSD目标检测平台
1. SSD网络架构
1.1 网络结构图
这个还是很好理解的,我就不多描述了。细节可以看我手绘的流程图。
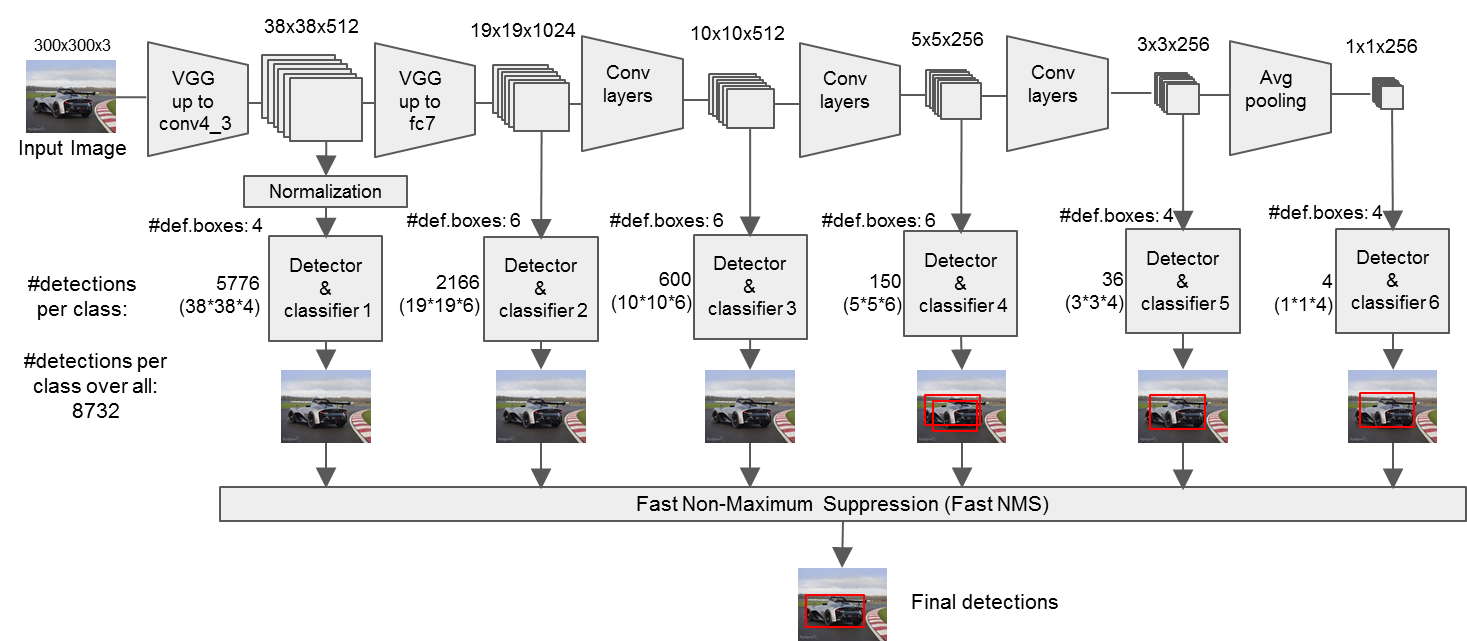
1.2 手绘流程图
SSD-Vgg16部分
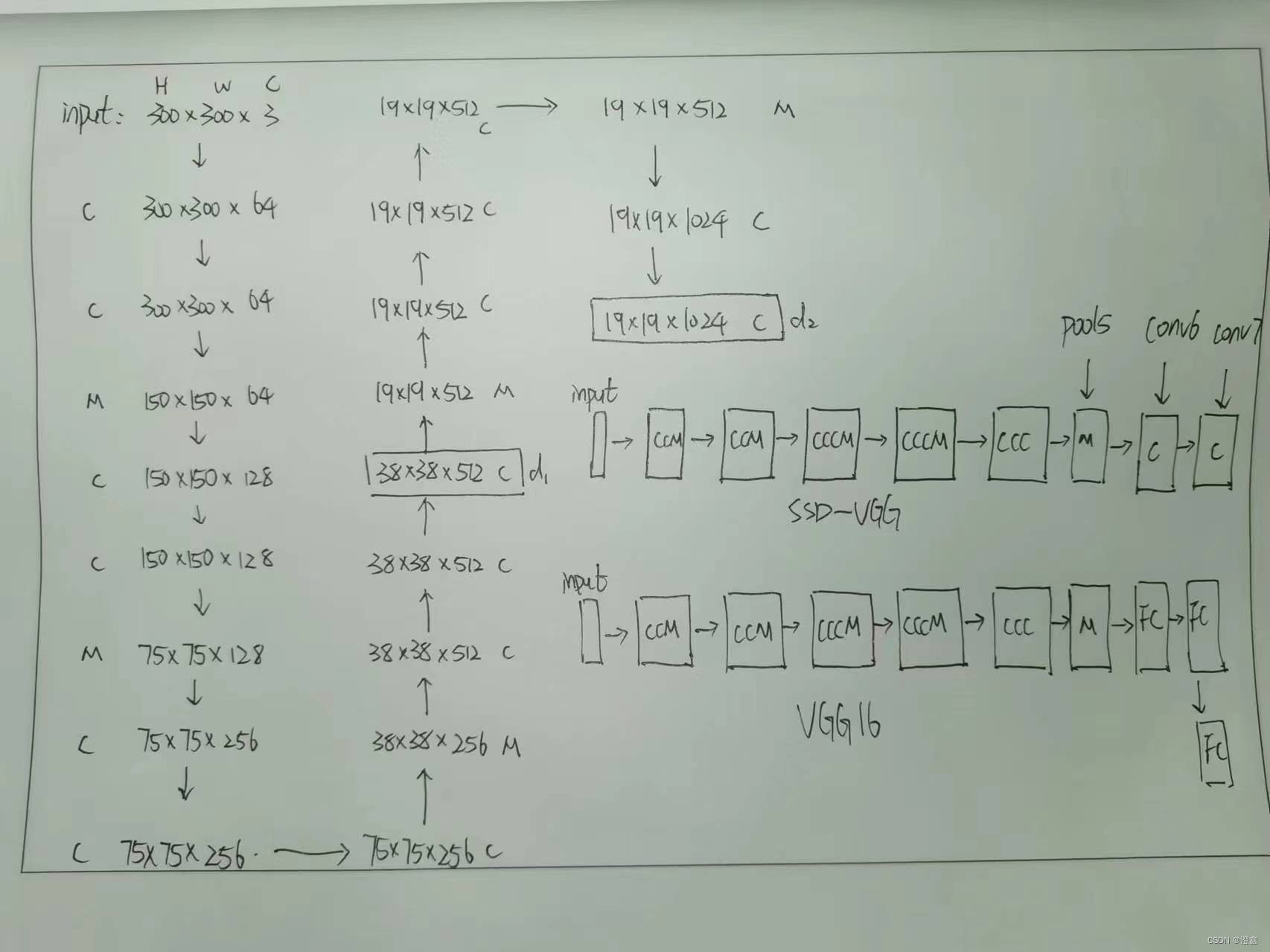
SSD-extra部分

1.3 网络结构代码
SSD_Vgg部分
我们将以VGG-16为例来讲解,mobilenet与resnet类似就不多重复了。这一部分我个人觉得需要注意的部分主要是三个:
- 这里在第三个池化层的部分使用了ceil_mode的池化方式,可以参考这篇博客进行学习—>深度学习笔记
- 和原VGG-16不同的是,这里我们将VGG-16最后的三个全连接层去掉了,取而代之的是两个卷积层。还有在这里的最后一个池化层,也就是下面代码中定义的pool5层是核为3,步长为1,填充为1的最大值池化层,这与原VGG-16不同。
- 还有就是这里的代码中使用的是nn.ModuleList()来组合这些层的,小伙伴们肯定也见过用nn.Sequential()来组合层的。 具体的区别可以参考这篇博客学习—>nn.Sequential与nn.ModuleList
- 最后这里还需要注意的是,我们以一次池化为一个卷积块来划分的前提下,第四个模块的输出就会作为其中一个检测头detection_head1(38 * 38 * 512)(不经过池化层),然后还有一个detection_head2(19 * 19 * 1024)是经过conv7的输出。
弄清楚这三点,剩下的代码也很简单了,可以参考1.1网络结构图部分一层一层的对照,并计算特征层尺度的变化。
import torch.nn as nn
from torch.hub import load_state_dict_from_url
'''
该代码用于获得VGG主干特征提取网络的输出。
输入变量i代表的是输入图片的通道数,通常为3。
300, 300, 3 -> 300, 300, 64 -> 300, 300, 64 -> 150, 150, 64 -> 150, 150, 128 -> 150, 150, 128 -> 75, 75, 128 ->
75, 75, 256 -> 75, 75, 256 -> 75, 75, 256 -> 38, 38, 256 -> 38, 38, 512 -> 38, 38, 512 -> 38, 38, 512 -> 19, 19, 512 ->
19, 19, 512 -> 19, 19, 512 -> 19, 19, 512 -> 19, 19, 512 -> 19, 19, 1024 -> 19, 19, 1024
38, 38, 512的序号是22
19, 19, 1024的序号是34
'''
base = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',
512, 512, 512]
def vgg(pretrained = False):
# 定义一个存放各个卷积层和池化层的空列表layers
# 由于我们输入的都是rgb彩色图像,因此这里的输入channel从3开始
layers = []
in_channels = 3
# 这里的base就是定义在外部的一个全局变量的列表,里面存了一些关键字,包括卷积层的输出channel数,以及'M'表示添加最大值池化层,以及'C'表示添加ceild_mode模式的池化层。
for v in base:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
elif v == 'C':
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
# 19, 19, 512 -> 19, 19, 512
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
# 19, 19, 512 -> 19, 19, 1024
conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6)
# 19, 19, 1024 -> 19, 19, 1024
conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
layers += [pool5, conv6,
nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)]
model = nn.ModuleList(layers)
if pretrained:
state_dict = load_state_dict_from_url("https://download.pytorch.org/models/vgg16-397923af.pth", model_dir="./model_data")
state_dict = {k.replace('features.', '') : v for k, v in state_dict.items()}
model.load_state_dict(state_dict, strict = False)
return model
if __name__ == "__main__":
net = vgg()
for i, layer in enumerate(net):
print(i, layer)
SSD_extra部分
接下去就是添加ssd网络的其他层了,这个方法写在了ssd.py文件中,这一块就简单很多了,顺着VGG-16的conv7层继续往下叠加卷积层即可,每个block包含了两个卷积层,每个block的第一个卷积层只改变通道数,不改变特征层的尺度,而第二个卷积既改变通道数也会改变尺度(缩小原尺度的一半)。
这里需要注意的是:
- 每一个block的第二层的卷积的输出就是我们需要的剩下的检测头,分别代表了detection_head3(block 6), detection_head4(block 7), detection_head5(block 8), detection_head6(block 9)。 这些检测头代表了不同尺度的特征图,大尺度的特征图用来检测小目标(例如38 * 38 和 19 * 19),小尺度的特征图用来检测大目标(例如3 * 3和1 * 1)。
def add_extras(in_channels, backbone_name):
layers = []
if backbone_name == 'mobilenetv2':
layers += [InvertedResidual(in_channels, 512, stride=2, expand_ratio=0.2)]
layers += [InvertedResidual(512, 256, stride=2, expand_ratio=0.25)]
layers += [InvertedResidual(256, 256, stride=2, expand_ratio=0.5)]
layers += [InvertedResidual(256, 64, stride=2, expand_ratio=0.25)]
else:
# Block 6
# 19,19,1024 -> 19,19,256 -> 10,10,512
layers += [nn.Conv2d(in_channels, 256, kernel_size=1, stride=1)]
layers += [nn.Conv2d(256, 512, kernel_size=3, stride=2, padding=1)]
# Block 7
# 10,10,512 -> 10,10,128 -> 5,5,256
layers += [nn.Conv2d(512, 128, kernel_size=1, stride=1)]
layers += [nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1)]
# Block 8
# 5,5,256 -> 5,5,128 -> 3,3,256
layers += [nn.Conv2d(256, 128, kernel_size=1, stride=1)]
layers += [nn.Conv2d(128, 256, kernel_size=3, stride=1)]
# Block 9
# 3,3,256 -> 3,3,128 -> 1,1,256
layers += [nn.Conv2d(256, 128, kernel_size=1, stride=1)]
layers += [nn.Conv2d(128, 256, kernel_size=3, stride=1)]
return nn.ModuleList(layers)
SSD的整体组合
这里的话就是把我们上面定义好的VGG层和extra层的结果进行一个整合,下面来描述一下具体的流程:
-
首先,将定义好的vgg和ssd_extra网络结构传给类内的属性。然后定义L2norm层,这个会在第一个检测头输出的时候用上。
-
然后定义好每个检测头的每个anchors对应的先验框的个数。这里的数据设定其实是一种经验,具体来说没有什么号展开说明的。
-
定义好存放回归特征层和分类特征层的列表。
-
定义一个列表存放VGG层中输出的两个detection_head的索引,这里我们也可以通过输出一下VGG的网络结构来可视化的看一下具体是哪一层对应的多少索引,根据前文描述的,这里的两个检测头的索引分别是21和33,当然这里bubbling用21和-2也是一样的:

-
然后是使用enumerate来循环的遍历这个backbone_source=[21, -2]。可以分别获取到我们在上文中提到的VGG层中的两个detection_heads,分别是[38 * 38 * 512]和[19 * 19 * 1024]的特征图,通过卷积的方式,将这两个特征层分别与回归输出和分类输出所关联,其中回归层的通道数为mbox[k] * 4,这里的4分别代表了预测框左上角的坐标以及宽高,以21层为例子,经过回归的卷积之后得到----->[38 * 38 * 16],经过分类的卷积层之后得到----->[38 * 38 * 8] (假设类别为2)。也就是说一共38 * 38 = 1444个特征点,每个点对应了4个先验框,这四个先验框分别有回归信息长度为4,分类信息长度为2,这么讲的话应该是非常清晰的了。我们可以可视化一下在[38 * 38]这个尺度的随机两个位置的先验框:( 这里再强调一下,这只是我们解码出来的可视化的结果,每个特征点对应的4个先验框的信息以通道的形式进行了堆叠 4 * 4 = 16)

-
然后同样的也是使用enumerate来遍历extra特征网络,这里要注意的是,self.extras[1::2] 的意思是每隔1个层取一次v,然后这里的k的索引应该是从2开始,因为从这开始是第三个detection_head了。
-
然后就是将已经提取出来的回归特征层和分类特征层添加到nn.ModuleList()中
-
定义前向传播的方式,当backbone_name=vgg时,我们的输入首先执行到第22层得到第四个池化层之后经过ReLu()激活函数的输出结果。然后对这个结果进行L2norm标准化,然后添加到source中。后面的detection_head同理。然后就是对这六个detection_head的结果进行维度上的变换—>bchw。
-
最后将loc和conf在第一个维度上进行堆叠,最后再resize到合适的尺寸输出。
class SSD300(nn.Module):
def __init__(self, num_classes, backbone_name, pretrained = False):
super(SSD300, self).__init__()
self.num_classes = num_classes
if backbone_name == "vgg":
self.vgg = add_vgg(pretrained)
self.extras = add_extras(1024, backbone_name)
self.L2Norm = L2Norm(512, 20)
mbox = [4, 6, 6, 6, 4, 4]
loc_layers = []
conf_layers = []
backbone_source = [21, -2]
#---------------------------------------------------#
# 在add_vgg获得的特征层里
# 第21层和-2层可以用来进行回归预测和分类预测。
# 分别是conv4-3(38,38,512)和conv7(19,19,1024)的输出
#---------------------------------------------------#
for k, v in enumerate(backbone_source):
loc_layers += [nn.Conv2d(self.vgg[v].out_channels, mbox[k] * 4, kernel_size = 3, padding = 1)]
conf_layers += [nn.Conv2d(self.vgg[v].out_channels, mbox[k] * num_classes, kernel_size = 3, padding = 1)]
#-------------------------------------------------------------#
# 在add_extras获得的特征层里
# 第1层、第3层、第5层、第7层可以用来进行回归预测和分类预测。
# shape分别为(10,10,512), (5,5,256), (3,3,256), (1,1,256)
#-------------------------------------------------------------#
for k, v in enumerate(self.extras[1::2], 2):
loc_layers += [nn.Conv2d(v.out_channels, mbox[k] * 4, kernel_size = 3, padding = 1)]
conf_layers += [nn.Conv2d(v.out_channels, mbox[k] * num_classes, kernel_size = 3, padding = 1)]
elif backbone_name == "mobilenetv2":
self.mobilenet = mobilenet_v2(pretrained).features
self.extras = add_extras(1280, backbone_name)
self.L2Norm = L2Norm(96, 20)
mbox = [6, 6, 6, 6, 6, 6]
loc_layers = []
conf_layers = []
backbone_source = [13, -1]
for k, v in enumerate(backbone_source):
loc_layers += [nn.Conv2d(self.mobilenet[v].out_channels, mbox[k] * 4, kernel_size = 3, padding = 1)]
conf_layers += [nn.Conv2d(self.mobilenet[v].out_channels, mbox[k] * num_classes, kernel_size = 3, padding = 1)]
for k, v in enumerate(self.extras, 2):
loc_layers += [nn.Conv2d(v.out_channels, mbox[k] * 4, kernel_size = 3, padding = 1)]
conf_layers += [nn.Conv2d(v.out_channels, mbox[k] * num_classes, kernel_size = 3, padding = 1)]
elif backbone_name == "resnet50":
self.resnet = nn.Sequential(*resnet50(pretrained).features)
self.extras = add_extras(1024, backbone_name)
self.L2Norm = L2Norm(512, 20)
mbox = [4, 6, 6, 6, 4, 4]
loc_layers = []
conf_layers = []
out_channels = [512, 1024]
#---------------------------------------------------#
# 在add_vgg获得的特征层里
# 第layer3层和layer4层可以用来进行回归预测和分类预测。
#---------------------------------------------------#
for k, v in enumerate(out_channels):
loc_layers += [nn.Conv2d(out_channels[k], mbox[k] * 4, kernel_size = 3, padding = 1)]
conf_layers += [nn.Conv2d(out_channels[k], mbox[k] * num_classes, kernel_size = 3, padding = 1)]
#-------------------------------------------------------------#
# 在add_extras获得的特征层里
# 第1层、第3层、第5层、第7层可以用来进行回归预测和分类预测。
# shape分别为(10,10,512), (5,5,256), (3,3,256), (1,1,256)
# for k, v in enrmerate(a, b) 意思是v从a里面枚举,k是索引值,从b开始
#-------------------------------------------------------------#
for k, v in enumerate(self.extras[1::2], 2):
loc_layers += [nn.Conv2d(v.out_channels, mbox[k] * 4, kernel_size = 3, padding = 1)]
conf_layers += [nn.Conv2d(v.out_channels, mbox[k] * num_classes, kernel_size = 3, padding = 1)]
else:
raise ValueError("The backbone_name is not support")
self.loc = nn.ModuleList(loc_layers)
self.conf = nn.ModuleList(conf_layers)
self.backbone_name = backbone_name
def forward(self, x):
#---------------------------#
# x是300,300,3
#---------------------------#
sources = list()
loc = list()
conf = list()
#---------------------------#
# 获得conv4_3的内容
# shape为38,38,512
#---------------------------#
if self.backbone_name == "vgg":
for k in range(23):
x = self.vgg[k](x)
elif self.backbone_name == "mobilenetv2":
for k in range(14):
x = self.mobilenet[k](x)
elif self.backbone_name == "resnet50":
for k in range(6):
x = self.resnet[k](x)
#---------------------------#
# conv4_3的内容
# 需要进行L2标准化
#---------------------------#
s = self.L2Norm(x)
sources.append(s)
#---------------------------#
# 获得conv7的内容
# shape为19,19,1024
#---------------------------#
if self.backbone_name == "vgg":
for k in range(23, len(self.vgg)):
x = self.vgg[k](x)
elif self.backbone_name == "mobilenetv2":
for k in range(14, len(self.mobilenet)):
x = self.mobilenet[k](x)
elif self.backbone_name == "resnet50":
for k in range(6, len(self.resnet)):
x = self.resnet[k](x)
sources.append(x)
#-------------------------------------------------------------#
# 在add_extras获得的特征层里
# 第1层、第3层、第5层、第7层可以用来进行回归预测和分类预测。
# shape分别为(10,10,512), (5,5,256), (3,3,256), (1,1,256)
#-------------------------------------------------------------#
for k, v in enumerate(self.extras):
# torch.Functional.relu() 中的inplace=True时,会覆盖原来的输入,False时不会覆盖
x = F.relu(v(x), inplace=True)
if self.backbone_name == "vgg" or self.backbone_name == "resnet50":
if k % 2 == 1:
sources.append(x)
else:
sources.append(x)
#-------------------------------------------------------------#
# 为获得的6个有效特征层添加回归预测和分类预测
# torch.permute()让每个检测头的输出进行维度的交换 bchw->bhwc
# torch.contiguous()是一个用于确保张量连续存储的方法
#-------------------------------------------------------------#
for (x, l, c) in zip(sources, self.loc, self.conf):
loc.append(l(x).permute(0, 2, 3, 1).contiguous())
conf.append(c(x).permute(0, 2, 3, 1).contiguous())
#-------------------------------------------------------------#
# 进行reshape方便堆叠
#-------------------------------------------------------------#
loc = torch.cat([o.view(o.size(0), -1) for o in loc], 1)
conf = torch.cat([o.view(o.size(0), -1) for o in conf], 1)
#-------------------------------------------------------------#
# loc会reshape到batch_size, num_anchors, 4
# conf会reshap到batch_size, num_anchors, self.num_classes
#-------------------------------------------------------------#
output = (
loc.view(loc.size(0), -1, 4),
conf.view(conf.size(0), -1, self.num_classes),
)
return output
2.损失函数
进入ssd_training.py中进行查询
2.1.成员属性
首先来看看损失函数类的初始化部分,我们可以看到成员属性有:
num_classes:分类的类别数;
alpha:loc损失的重要系数,默认为1;
neg_pos_ratio:负样本的重要系数,默认为3;
background_label_id:背景的索引,默认为0;
negative_for_hard:难分类的负样本,默认为100,即100个先验框作为负样本;
class MultiboxLoss(nn.Module):
def __init__(self, num_classes, alpha=1.0, neg_pos_ratio=3.0,
background_label_id=0, negatives_for_hard=100.0):
self.num_classes = num_classes
self.alpha = alpha
self.neg_pos_ratio = neg_pos_ratio
if background_label_id != 0:
raise Exception('Only 0 as background label id is supported')
self.background_label_id = background_label_id
self.negatives_for_hard = torch.FloatTensor([negatives_for_hard])[0]
2.2.回归损失函数
这里定义了一个l1_smooth损失函数作为回归损失函数,l1_smooth损失函数具体的原理可以看这篇博客【Smooth L1 Loss】Smooth L1损失函数理解。
这里有一个可以学习的点是==torch.where()==方法;torch.where方法实现了一个分段函数的功能:
torch.where(condition, x, y):
condition:判断条件
x:若满足条件,则取x中元素
y:若不满足条件,则取y中元素
def _l1_smooth_loss(self, y_true, y_pred):
abs_loss = torch.abs(y_true - y_pred)
sq_loss = 0.5 * (y_true - y_pred)**2
l1_loss = torch.where(abs_loss < 1.0, sq_loss, abs_loss - 0.5)
return torch.sum(l1_loss, -1)
2.3.分类损失函数
这里的分类损失函数用的就是分类任务中常见的一种损失函数softmax:
def _softmax_loss(self, y_true, y_pred):
y_pred = torch.clamp(y_pred, min = 1e-7)
softmax_loss = -torch.sum(y_true * torch.log(y_pred),
axis=-1)
return softmax_loss
2.4.损失的执行函数-正负样本匹配
执行函数 forward() 的输入分别是真实结果与预测结果,真实结果就是读取我们的标注数据,预测结果就是模型前向传播后的输出结果。下面来撸一下整体的损失计算流程,包含了每一行代码的理解!!!
-
根据SSD网络的定义可以知道模型的输出结果的维度构成是这样的:batch_size, 8732, 4 + self.num_classes + 1,其中8732的含义我们回顾一下,这是六个detection_heads的先验框个数之和,以最浅层的detection_head为例,输出的维度是38 * 38 * 512,通道数512我们不管,因为这是特征的表示,我们关注的是尺度38 * 38 ,即拥有38 * 38个锚点,每个锚点上拥有4个先验框,因此第一个detection_head拥有 38 * 38 * 4=5776。以此类推其他五个检测头,然后相加就是所有先验框的个数。
-
y_pred作为模型的预测输出,包含了两个部分,一个是回归输出,一个是分类输出:
y_pred[0] 为回归输出 —> [batch_size, 8732, 4]
y_pred[1] 为分类输出 —> [batch_size, 8732, self.num_classes]
y_true作为真实标签 —> [batch_size, 8732, 4 + 1 + self.num_classes],其中加的1表示的是该类别是背景还是目标(0为背景,1为目标,后面主要用来正负样本匹配环节)。 -
首先通过y_true来获得我们所有的先验框的个数,这个也可以通过y_pred获得,这里没有特别的含义。
-
然后我们将y_pred进行一个堆叠,就是将原来的两部分的输出,堆叠到一个张量上,这里我们用到了
torch.cat()函数来实现这个堆叠,堆叠的对象分别是y_pred]0]和y_pred[1],但是我们需要对y_pred[1]进行一下softmax的处理,让原本较为离散的分类得分更加集中一点,方便我们分类,所以这里用到了nn.Softmax()方法。然后由于我们是在最后一个维度进行拼接,即将[batch_size, 8732, 4]与[batch_size, 8732, self.num_classes] concat 成 [batch_size, 8732, 4 + self.num_classes]。 -
然后使用定义好的==_softmax_loss()==方法来计算y_true和y_pred之间的分类损失,其中y_true需要取到倒数第二个分类置信度停止,因为最后一个分类是背景与目标的分类,不需要参与分类的损失。
-
同样的,使用==_l1_smooth_loss()==方法来计算y_true和y_pred的回归损失。
-
然后是获取所有正标签的loss,由于我们的预测框里肯定包含了很多的框了背景的,我们需要剔除掉这些,因此,我们可以用我们刚才计算的loc_loss以及conf_loss来乘以y_true的第3维度的最后一个分类值,即目标的话就是1,背景的话就是0,乘完之后就可以得到我们的正样本loss。
-
然后我们再将y_true的第三维度的最后一个值相加,就可以得到我们有多少的正样本的框,即8732个先验框中,每个都对应个0,1分类,加完之后,便可知有多少的正样本。
-
然后便是根据正样本的数量来获得负样本的数量。这里用了一个选择最小值,根据前面定义的负样本的比例参数乘以正样本个数,与所有先验框的个数-正样本个数进行对比。
-
然后我们会得到[batch_size, num_neg]的一个数据,我们将其和0对比一下,可以得到一个batch中每个输入样本是否有负样本数和正样本数。得到了一个pos_num_neg_mask。
-
使用==torch.sum()==来将这个张量里的所有ture和false相加,得到一个数,这个数代表的就是我们这个batch里面有正负样本个数的独立个体的数量,比如batch_size=8,我们得到的数是7,就说明只有一个独立个体是没有正负样本的。
-
然后就是写一个判断语句,如果has_min > 0的话,我们就将我们的负样本数量相加得到这个batch里面所有负样本的个数,如果这个batch里一个负样本都没有,我们默认选择一百个负样本来计算负样本损失。
-
然后就是计算出每个预测框的分类的得分的和,即将[batch_size, 8732, self.num_classes] —> [batch_size, self.num_classes]维度:max_confs。
-
然后将刚才计算出来的max_confs乘以每一个(1-y_true[:,:,-1]),即留下负样本的损失,正样本的损失乘完之后就归0了,然后view成一个一维的张量,即[batch_size, 8732] —> [1, batch_size * 8732]。
-
然后我们使用torch.topk()方法,来返回得分排名最靠前的,上面我们计算出来的num_neg_batch个数的负样本的个数的索引,即为最难分类的负样本。
-
然后利用==torch.gather()==方法来获得这些最难分类的负样本的损失。
-
然后最后就是将正样本的分类损失,正样本的回归损失,负样本的分类损失相加,并除以正样本的总数进行归一化。
上代码!!!
class MultiboxLoss(nn.Module):
def __init__(self, num_classes, alpha=1.0, neg_pos_ratio=3.0,
background_label_id=0, negatives_for_hard=100.0):
self.num_classes = num_classes
self.alpha = alpha
self.neg_pos_ratio = neg_pos_ratio
if background_label_id != 0:
raise Exception('Only 0 as background label id is supported')
self.background_label_id = background_label_id
self.negatives_for_hard = torch.FloatTensor([negatives_for_hard])[0]
def _l1_smooth_loss(self, y_true, y_pred):
abs_loss = torch.abs(y_true - y_pred)
sq_loss = 0.5 * (y_true - y_pred)**2
l1_loss = torch.where(abs_loss < 1.0, sq_loss, abs_loss - 0.5)
return torch.sum(l1_loss, -1)
def _softmax_loss(self, y_true, y_pred):
y_pred = torch.clamp(y_pred, min = 1e-7)
softmax_loss = -torch.sum(y_true * torch.log(y_pred),
axis=-1)
return softmax_loss
def forward(self, y_true, y_pred):
# --------------------------------------------- #
# y_true batch_size, 8732, 4 + self.num_classes + 1
# y_pred batch_size, 8732, 4 + self.num_classes
# --------------------------------------------- #
# y_pred 作为预测输出其中包含了两个部分:
# y_pred[0] 为回归的输出 ---> [batch_size, 8732, 4]
# y_pred[1] 为分类的输出 ---> [batch_size, 8732, self.num_classes]
# --------------------------------------------- #
print(y_pred[0].size())
print(y_pred[1].size())
print(y_pred[1])
print(nn.Softmax(-1)(y_pred[1]))
print(y_true.size())
num_boxes = y_true.size()[1]
# --------------------------------------------- #
# 这一步就是把y_pred的两个部分在第3个维度上进行拼
# 拼接成 --->[batch_size, 8732, 4 + self.num_classes]
# 这里需要注意的是,为了更好的实现分类结果,我们使用softmax()函数将其处理一下,然后再拼接上去
# nn.Softmax()的使用方法:
# 首先实例化一个my_softmax = nn.Softmax(dim=)对象,需要输入一个参数来进行初始化构造,即我们对第几个维度的张量进行softmax
# 然后这么调用:output = my_softmax(y_pred[1])
# 当然也可以像bubbling一样的调用方式,直接这么写 output = nn.Softmax(dim=-1)(y_pred[0])
y_pred = torch.cat([y_pred[0], nn.Softmax(-1)(y_pred[1])], dim = -1)
print(y_pred.size())
print(y_pred[:,:,4:])
# --------------------------------------------- #
# 分类的loss
# batch_size,8732,21 -> batch_size,8732
# --------------------------------------------- #
y_1 = y_true[:,:,4:-1]
y_2 = y_true[:,:,4:]
print(y_1.size())
print(y_2.size())
conf_loss = self._softmax_loss(y_true[:, :, 4:-1], y_pred[:, :, 4:])
print(conf_loss.size())
# --------------------------------------------- #
# 框的位置的loss
# batch_size,8732,4 -> batch_size,8732
# --------------------------------------------- #
loc_loss = self._l1_smooth_loss(y_true[:, :, :4],
y_pred[:, :, :4])
# --------------------------------------------- #
# 获取所有的正标签的loss
# --------------------------------------------- #
pos_loc_loss = torch.sum(loc_loss * y_true[:, :, -1],
axis=1)
pos_conf_loss = torch.sum(conf_loss * y_true[:, :, -1],
axis=1)
# --------------------------------------------- #
# 每一张图的正样本的个数
# num_pos [batch_size,]
# --------------------------------------------- #
print(y_true[:,:,-1])
print(y_true.size())
# --------------------------------------------- #
# 每一个batch中 8375行的最后一个,即是背景还是目标的值相加(0:背景,1:目标)
# --------------------------------------------- #
num_pos = torch.sum(y_true[:, :, -1], axis=-1)
# --------------------------------------------- #
# 每一张图的负样本的个数
# num_neg [batch_size,]
# --------------------------------------------- #
num_neg = torch.min(self.neg_pos_ratio * num_pos, num_boxes - num_pos)
# 找到了哪些值是大于0的
pos_num_neg_mask = num_neg > 0
# --------------------------------------------- #
# 如果所有的图,正样本的数量均为0
# 那么则默认选取100个先验框作为负样本
# --------------------------------------------- #
has_min = torch.sum(pos_num_neg_mask)
# --------------------------------------------- #
# 从这里往后,与视频中看到的代码有些许不同。
# 由于以前的负样本选取方式存在一些问题,
# 我对该部分代码进行重构。
# 求整个batch应该的负样本数量总和
# --------------------------------------------- #
num_neg_batch = torch.sum(num_neg) if has_min > 0 else self.negatives_for_hard
# --------------------------------------------- #
# 对预测结果进行判断,如果该先验框没有包含物体
# 那么它的不属于背景的预测概率过大的话
# 就是难分类样本
# --------------------------------------------- #
confs_start = 4 + self.background_label_id + 1
confs_end = confs_start + self.num_classes - 1
# --------------------------------------------- #
# batch_size,8732
# 把不是背景的概率求和,求和后的概率越大
# 代表越难分类。
# --------------------------------------------- #
print(y_pred.size())
max_confs = torch.sum(y_pred[:, :, confs_start:confs_end], dim=2)
print(max_confs.size())
# --------------------------------------------------- #
# 只有没有包含物体的先验框才得到保留
# 我们在整个batch里面选取最难分类的num_neg_batch个
# 先验框作为负样本。
# --------------------------------------------------- #
max_confs = (max_confs * (1 - y_true[:, :, -1])).view([-1])
print(max_confs.size())
# --------------------------------------------------- #
# torch.topk()的功能是:第一个输入为张量,通常是某一维张量,第二个输入是我们想要提取的个数
# 实现的功能是,帮助我们从这一段一维张量中提取出这么多个数的最大值出来并返回索引(即最难分类的框的索引)
# --------------------------------------------------- #
_, indices = torch.topk(max_confs, k = int(num_neg_batch.cpu().numpy().tolist()))
# --------------------------------------------------- #
# 上面我们已经获得了最难分类的负样本的置信度索引
# 下面我们将利用这个索引在conf_loss里面去寻找出对应的分类损失
# torch.gather()函数能帮助我们实现这个功能,torch.gather(tensor,dim,index)
# 这里我们先将conf_loss拉伸到一维向量,然后dim自然就是0,indices已经由上面的topk得到
# 这样torch.gather()可以返回一个tensor,这个tensor里面的元素就是最难分类的负样本的分类损失。
# --------------------------------------------------- #
neg_conf_loss = torch.gather(conf_loss.view([-1]), 0, indices)
# 进行归一化
num_pos = torch.where(num_pos != 0, num_pos, torch.ones_like(num_pos))
total_loss = torch.sum(pos_conf_loss) + torch.sum(neg_conf_loss) + torch.sum(self.alpha * pos_loc_loss)
total_loss = total_loss / torch.sum(num_pos)
return total_loss
3.训练部分
3.1 固定随机数种子
固定随机数种子的作用主要有3个:
- 方便对比不同的算法和模型,算是深度学习中控制变量的一个环节,否则深度学习的训练过程会出现太多的随机性。
- 方便我们调试和排查问题,因为如果我们不固定随机数种子,每次训练的损失,精度都不同的话,我们很难发现我们炼丹的效果,因为时好时不好的,不好下定论。而且当训练中出现异常时,固定的随机数种子能方便我们快速定位问题。
- 方便分享代码到其他平台上,方便他人复现验证我们的算法。
- torch.backends.cudnn.benchmark 当设置为True时,torch在训练的初期会自动的选择最适合该网络的卷积算法,即在训练初期的搜索阶段会有较慢的训练速度,但是后期速度会加快,但是会导致训练时的不确定性因素,因此如果想要复现的话,建议设置为false。
- torch.backends.cudnn.deterministic 设置为True时,会固定cuda的随机数种子,每次返回的卷积算法将是固定的。
def seed_everything(seed=11):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
3.2 分布式训练(DDP)
- torch.cuda.device_count()会返回训练主机的显卡个数
- dist.init_process_group()的参数是对分布式后端进行一个选择,一般都是选择backend=“nccl”,其他的分布式后端还有“gloo”,“mpi”。
- 分布式训练的过程中,我们需要知道当前进程的rank与local_rank。其中rank的意思即当前进程在所有进程中的排序,local_rank的意思即当前进程在当前卡上的进程的排序。也就是说,当我们是单机多卡的时候rank和local_rank应该是一致的,当采用多机多卡时,local_rank和rank是不一样的。
- dist.barrier()方法的作用是让其他的训练子进程来缓存主进程的数据。通常在处理数据时时是以一个主进程进行处理,然后缓存,由于其他的子进程也在同步执行,因此容易导致主进程还没缓存好数据,子进程就要读取缓存,这里需要给子进程设置一个阻塞,即等待主进程处理完毕,所有子进程开始加载。然后在同一起跑线上继续。
- 多卡同步batchnorm:
model_train = model.train()
model_train = torch.nn.SyncBatchNorm.convert_sync_batchnorm()
- 多卡并行运行:
model_train = model_train.cuda(local_rank)
model_train = torch.nn.parallel.DistributedDataParallel(model_train, device_ids=[local_rank], find_unused_parameters=True)
3.3 加载预训练权重再训练
获取模型的字典,以及预训练权重的字典,根据key与key的对应,来加载value。
我们常用的简单的方式是直接:
import torch
model.load_state_dict(torch.load(pretrained_pth, map_location=device))
这里bubbling佬使用的就是一一比对的方式来加载预训练权重:
model_dict = model.state_dict()
pretrained_dict = torch.load(model_path, map_location = device)
load_key, no_load_key, temp_dict = [], [], {}
for k, v in pretrained_dict.items():
if k in model_dict.keys() and np.shape(model_dict[k]) == np.shape(v):
temp_dict[k] = v
load_key.append(k)
else:
no_load_key.append(k)
model_dict.update(temp_dict)
model.load_state_dict(model_dict)
3.4 混合精度训练
混合精度训练,即会自动的调整训练时张量的数据类型,混合着使用fp16和fp32来进行训练。混合精度训练的好处有:节省显卡资源(对于硬件不足的情况下友好);训练速度加快;
使用方式如下:先用torch.cuda.amp.GradScaler来实例化一个scaler对象,然后在前向传播结束后,计算完损失反向传播时,使用scaler来反向传播,并更新权重参数:
from torch.cuda.amp import GradScaler
scaler = GradScaler()
...
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
以上这种用法仅支持torch版本在1.7以上的版本。
3.5 冻结训练
通过一个for循环来遍历我们用torch库定义好的model:
for param in model[:].parameters():
param.requires_grad = False
我们也可以指定到第几层进行冻结,比如指定从第5层到第27层的参数进行冻结:
for param in model[5:28].parameters():
param.requires_grad = False
3.6 学习率衰减
模型在训练的过程中,全过程确定一个不变的学习率是不合理的,因为在训练的初期,由于参数的随机性,较大的学习率会导致模型参数的收敛容易有较大的振荡,甚至沿着错误的方向发散,导致无法收敛。因此在训练初期,需要设置较小的学习率,然后逐渐增大学习率。直到得到最大学习率的这个过程,我们称之为warm up过程。然而一直使用最大的学习率也会使参数最终难以收敛到最优值,此时我们需要降低学习率来帮助其收敛。(具体的可以参考这篇博客:余弦退火)
我们需要指定一下初识学习率,最小学习率和最大学习率,然后分别在不同的阶段(根据warm_up_epoch)自适应的调整学习率。
partial()函数功能,把一个函数的某些参数给固定住,返回一个新的函数。具体的可以参考这篇博客:partial函数功能
- train.py
#-------------------------------------------------------------------#
# 判断当前batch_size,自适应调整学习率
#-------------------------------------------------------------------#
nbs = 64
lr_limit_max = 1e-3 if optimizer_type == 'adam' else 5e-2
lr_limit_min = 3e-4 if optimizer_type == 'adam' else 5e-5
Init_lr_fit = min(max(batch_size / nbs * Init_lr, lr_limit_min), lr_limit_max)
Min_lr_fit = min(max(batch_size / nbs * Min_lr, lr_limit_min * 1e-2), lr_limit_max * 1e-2)
#---------------------------------------#
# 获得学习率下降的公式
#---------------------------------------#
lr_scheduler_func = get_lr_scheduler(lr_decay_type, Init_lr_fit, Min_lr_fit, UnFreeze_Epoch)
- ssd_training.py
def get_lr_scheduler(lr_decay_type, lr, min_lr, total_iters, warmup_iters_ratio = 0.05, warmup_lr_ratio = 0.1, no_aug_iter_ratio = 0.05, step_num = 10):
def yolox_warm_cos_lr(lr, min_lr, total_iters, warmup_total_iters, warmup_lr_start, no_aug_iter, iters):
if iters <= warmup_total_iters:
# lr = (lr - warmup_lr_start) * iters / float(warmup_total_iters) + warmup_lr_start
lr = (lr - warmup_lr_start) * pow(iters / float(warmup_total_iters), 2) + warmup_lr_start
elif iters >= total_iters - no_aug_iter:
lr = min_lr
else:
lr = min_lr + 0.5 * (lr - min_lr) * (
1.0 + math.cos(math.pi* (iters - warmup_total_iters) / (total_iters - warmup_total_iters - no_aug_iter))
)
return lr
def step_lr(lr, decay_rate, step_size, iters):
if step_size < 1:
raise ValueError("step_size must above 1.")
n = iters // step_size
out_lr = lr * decay_rate ** n
return out_lr
if lr_decay_type == "cos":
warmup_total_iters = min(max(warmup_iters_ratio * total_iters, 1), 3)
warmup_lr_start = max(warmup_lr_ratio * lr, 1e-6)
no_aug_iter = min(max(no_aug_iter_ratio * total_iters, 1), 15)
func = partial(yolox_warm_cos_lr ,lr, min_lr, total_iters, warmup_total_iters, warmup_lr_start, no_aug_iter)
else:
decay_rate = (min_lr / lr) ** (1 / (step_num - 1))
step_size = total_iters / step_num
func = partial(step_lr, lr, decay_rate, step_size)
return func
















 5713
5713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











