






 本文介绍了Google的Gemini多模态模型系列,包括其架构、性能优势和预训练方法。特别关注了AlphaCode2的构建,以及如何在直播中从原理到实践讲解Gemini和ChatGPT的实战应用。
本文介绍了Google的Gemini多模态模型系列,包括其架构、性能优势和预训练方法。特别关注了AlphaCode2的构建,以及如何在直播中从原理到实践讲解Gemini和ChatGPT的实战应用。
▼最近直播超级多,预约保你有收获
近期直播:《从原理到实践教你做出一个Gemini/ChatGPT》
—1—
Gemini 技术架构剖析
Google 新的多模态模型家族 Gemini,它在文本、图像、音频、视频等方面具有卓越的能力。Gemini 系列包括 Ultra、Pro 和 Nano 三种尺寸,适用于从复杂的推理任务到设备内存受限的应用场景。
Gemini Ultra 是最强大的模型,可在各种高度复杂的任务(包括推理和多模式任务)中提供最先进的性能。由于 Gemini 架构,它在 TPU 加速器上能够高效地进行规模化服务。
Gemini 模型是基于 Transformer解码器(Decode Only)构建,针对神经网络结构和目标做了优化,从而提升大规模预训练时训练和推理的稳定性,所以Gemini 是类似 GPT 的 Decoder-only 预测 next token prediction的模式。经过训练以支持 32k 的上下文长度,采用高效的注意机制(例如,多查询注意力(Shazeer,2019)),如下图所示:
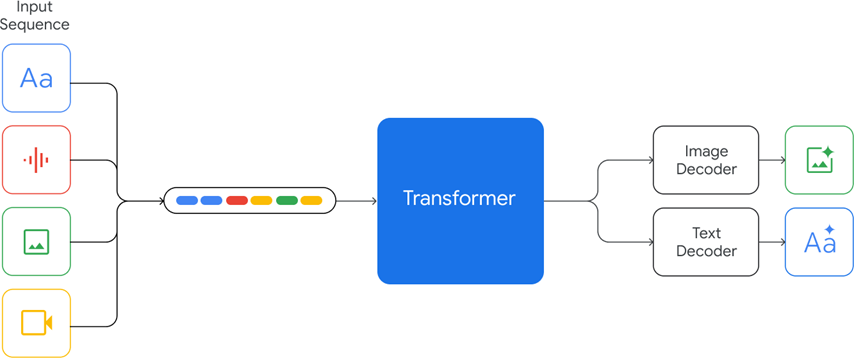
Gemini 支持以文本、图像、音频和视频的交错序列作为输入(在输入序列中用不同颜色的标记表示),它可以输出交错的图像和文本响应。
Gemini 把几种模态数据联合起来从从头训练,包括文本、图片、音频、视频等,遵循 next token prediction 的模式,所有模态的数据先变成 token,然后图片、视频等平面数据转换成 32*32 (举例)tokens,最后变成一维线性输入,让模型预测 next token,这样就把不同模态在预训练阶段统一起来。
Gemini 模型预训练在训练算法、数据集和基础设施方面进行创新。对于 Pro 模型,采用了基础设施和学习算法的固有可扩展性。使得能够在几周内完成预训练,利用了 Ultra 的一小部分资源。Nano 系列模型利用了蒸馏和训练算法的进一步改进,为各种任务(比如:摘要和阅读理解)提供了最佳的小型语言模型。
—2—
Gemini 数据工程剖析
Gemini 模型是在一个既包含多模态又包含多语言的数据集上进行训练的。预训练数据集使用来自网络文档、书籍和代码的数据,并包括图像、音频和视频数据。
使用 SentencePiece 分词器(Kudo和Richardson,2018),发现在整个训练语料库的大样本上训练分词器可以改善推断的词汇,并进而提高模型性能。例如,Gemini 模型可以高效地标记非拉丁脚本,这反过来可以提高模型质量以及训练和推理速度。
对所有数据集应用质量过滤器,使用启发式规则和基于模型的分类器。还进行安全过滤以删除有害内容。从训练语料库中筛选出评估集。通过对较小的模型进行消融实验,确定了最终的数据混合和权重。在训练过程中进行分阶段训练,通过增加领域相关数据的权重来改变混合组合,直到训练结束。数据质量对于一个高性能的模型至关重要,并且相信在寻找预训练的最佳数据集分布方面还存在许多有趣的问题。
—3—
AlphaCode 2 技术架构剖析
AlphaCode 团队构建了AlphaCode 2,这是一个新的基于 Gemini 的代理程序,它将 Gemini 的推理能力与搜索和工具使用相结合,以在解决竞争性编程问题方面表现出色。AlphaCode 2 在 Codeforces 竞技编程平台上排名前15% 的参赛者中,相比于排名前50%的最新技术前身有了很大的改进,架构设计如下:
多个策略模型,用于为每个问题生成各自的代码样本;
采样机制,能够生成多样化的代码样本,以在可能的程序解决方案中进行搜索;
过滤机制,移除那些不符合问题描述的代码样本;
聚类算法,将语义上相似的代码样本进行分组,以减少重复;
评分模型,用于从10个代码样本集群中筛选出最优解。
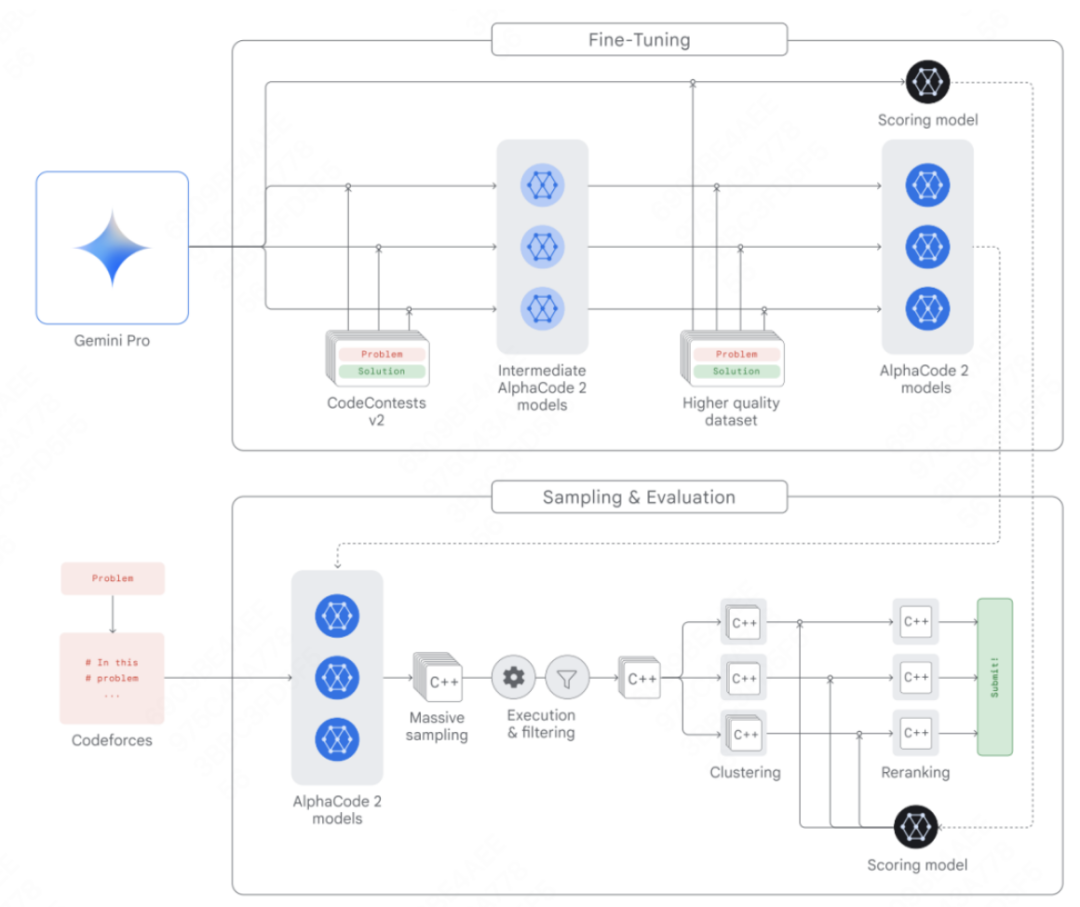
更多落地实现细节,周日晚20点的直播中详细剖析,请同学们点击免费预约。
—3—
干货+抽奖 Gemini/ChatGPT 案例实战直播
为了帮助同学们掌握好 LLM 大模型技术架构和企业级案例实战,周日晚20点,我会开一场直播和同学们深度聊聊:
第一、Gemini/ChatGPT 总体架构设计剖析
第二、动手打造一个 Gemini/ChatGPT 大模型
第三、Gemini/ChatGPT 在线推理工程架构设计落地
请同学点击下方按钮预约直播,咱们周日晚20点直播不见不散!
今晚直播:《从原理到实践教你做出一个Gemini/ChatGPT》
END

















 597
597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









