






你真的了解TCGA数据么?
引言
癌症基因组图谱(The Cancer Genome Atlas,TCGA)是一个由美国国家癌症研究所(NCI)和美国国立人类基因组研究所(NHGRI)联合发起的大规模癌症基因组学项目。自2006年启动以来,TCGA已成功收集和分析了多个癌症类型的基因组数据,并且为研究癌症的分子机制、诊断标志物的发现以及靶向治疗的开发提供了丰富的数据资源。TCGA的核心数据包括基因表达、DNA甲基化、突变谱、拷贝数变异等多维度数据,这些数据对癌症的研究有着巨大的推动作用。
TCGA命名规范:
TCGA数据库中的样本数据都有严格的命名规范,帮助研究者快速识别和区分不同的样本及其特征。TCGA的命名规则一般由以下部分组成:
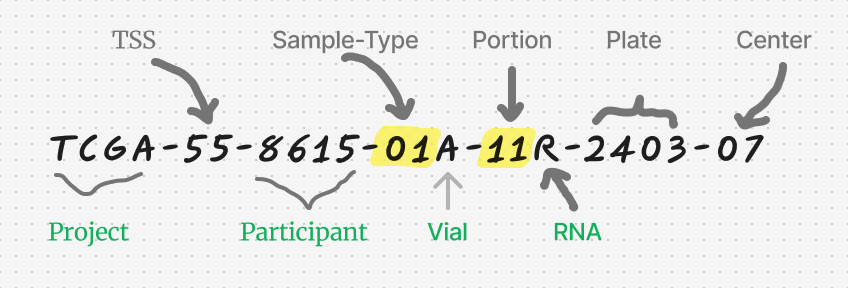
- TCGA(Project): 表明来源为癌症基因组图谱 (Project)。例如,所有TCGA样本名均以"TCGA"开头,标志该样本属于癌症基因组图谱项目。
- 组织来源编码(TSS, Tissue source site): 组织来源编码,表示样本来源的具体机构或医院。例如,A6表示该样本来自Christiana Healthcare中心。
- 患者编号(Participant): 代表具体患者的唯一标识符。例如,8615为该患者的唯一标识符。
- 样本类型(Sample): 样本类型编号,表示样本的类型,01-09表示肿瘤样本,10~19表示正常对照。如上图,01则表示该样本为肿瘤样本
- 样本容器(Vial): 样本容器编号,通常为A,极少数为B。B表示福尔马林固定石蜡包埋组织,效果较差。例如,A表示该样本来自于冰冻组织(Frozen Tissue),B表示样本来自于福尔马林固定石蜡包埋组织(FFPE)。
- 组织部分编号(Portion): 表示同一患者组织的不同部分的顺序编号。例如,11表示该样本来自该患者的第11部分组织。
- 分析分子类型(Analyte): 表示样本所分析的分子类型,例如RNA或DNA等。例如,R表示该样本用于RNA分析。
- 板号(Plate): 表示样本在96孔板中的顺序,值越大表示制板时间越晚。例如,2403表示样本在96孔板中的顺序号。
- 测序中心(Center): 标识样本测序的具体中心。例如,07表示该样本由某个特定的测序中心进行测序。
这种命名方式使得研究人员能够在复杂的多样本、多数据类型中快速准确地识别并管理样本。
数据预处理
在开始TCGA数据的后续分析之前,数据预处理是至关重要的步骤,主要包括以下几个方面:
- 名称转化:TCGA数据中的基因名称可能存在不同格式,比如有时是
ENSG00000000003.15这种转录本ID,或者是基因的符号(如TP53)。因此,首先需要进行名称转化,确保所有的基因名称统一,方便后续的分析。 - 数据清洗与格式化:由于TCGA数据来自不同的样本和不同的机构,因此数据可能存在缺失值、格式不统一等问题。首先需要对数据进行清理,删除无关的变量,填补缺失值,标准化数据格式。
- 数据标准化:不同的测量平台和数据类型之间的量纲可能不同,因此需要对数据进行标准化。例如,基因表达数据通常会进行TPM(Transcripts Per Million)或FPKM(Fragments Per Kilobase Million)标准化,以便不同样本之间的比较。
- 样本拆分:TCGA数据中通常包括肿瘤和正常组织样本。在分析之前,需要根据患者的编号将样本拆分为肿瘤组织和正常组织,确保数据能够正确地进行分组和比较。
完成预处理后,数据便可以用于后续的分析任务,如差异表达分析、预后分析、突变分析等。
数据分析与应用场景
1. 差异分析:选择哪些样本进行对比
差异分析(Differential Expression Analysis)通常用于比较肿瘤样本与正常样本之间的基因表达差异。这时,我们需要选择以下数据:
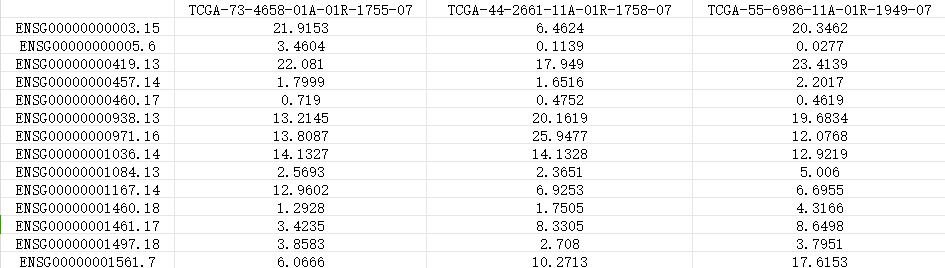
- 肿瘤样本:例如上图所示, TCGA-73-4658-01A-01R-1755-07,TCGA-44-2661-11A-01R-1758-07 。
- 正常样本:例如,TCGA-55-6986-11A-01R-1949-07(肺腺癌患者的正常对照样本)。
在肺腺癌的差异表达分析中,我们将比较这些原发肿瘤样本与正常组织样本的基因表达数据,识别出可能的癌症相关基因。
2. 预后分析:选择哪些样本进行研究
预后分析(Survival Analysis)通常用于评估不同临床特征对患者生存期的影响。TCGA数据库中每个样本都包含生存数据(例如,总生存期、无病生存期等)。因此,在进行预后分析时,您通常会选择以下数据:
- 癌症样本:这一步仅选癌症样本。例如,TCGA-73-4658-01A-01R-1755-07(肺腺癌原发肿瘤样本)。
- 临床数据:这些数据包含了患者的生存期、分期、治疗信息等。
通过将不同分期的肺腺癌患者数据(如I期、II期、III期、IV期)与生存期进行关联分析,可以识别影响患者预后的关键基因和通路。
3. 例子:肺腺癌(LUAD)差异分析与预后分析
-
差异表达分析:
- 数据:选择TCGA中肺腺癌患者的原发肿瘤样本(如 TCGA-LUAD-01)与相应的正常样本(如 TCGA-LUAD-11)。
- 分析:使用R语言中的
DESeq2包或edgeR包进行差异表达分析,识别肿瘤与正常样本之间基因表达的显著差异。 - 示例代码:
library(DESeq2)
dds <- DESeqDataSetFromMatrix(countData = countData, colData = colData, design = ~ condition)
dds <- DESeq(dds)
res <- results(dds)
summary(res)
-
预后分析:
- 数据:选择肺腺癌样本(如 TCGA-LUAD-01),结合临床数据进行预后分析。
- 分析:使用生存分析(如Cox回归分析),将基因表达数据与患者的生存期进行关联。
- 示例代码:
library(survival)
lung_data <- read.csv("LUAD_clinical_data.csv")
lung_data$Surv_time <- as.numeric(lung_data$Surv_time)
lung_data$event <- as.factor(lung_data$event)
cox_model <- coxph(Surv(Surv_time, event) ~ gene_expression_data, data = lung_data)
summary(cox_model)
总结
TCGA数据库作为癌症研究的核心数据来源,提供了大量的多维度癌症数据,支持从基因组学、转录组学到临床数据的全面分析。通过TCGA数据库,研究人员能够有效地进行差异表达分析、预后分析以及其他癌症相关的生物学研究。
平台介绍
- 致力于现学现用,打破无效的R数据分析学习模式:通过实践导向的教学方法,帮助学员迅速掌握R语言在生物信息学中的应用。
- 致力于掌握学习方法,在实战中进行演练,提升思维逻辑和解决实际分析问题的能力:通过真实案例的分析,培养学员的独立思考和问题解决能力。
- 价格实惠,内容到位:提供高性价比的课程,确保学员以合理的投入获得全面、深入的知识和技能。
联系方式
好啦,今日分享毕!更多科研干货、绘图技能关注 N今天C了么 不迷路!



















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









