







前言
本文分享学习 huggingface Tokenizers 库记录。我分成了五大主题:
- 从头快速训练一个 tokenzier
- 如何使用预训练好的 tokenzier
- Tokenization 四大过程详解
- BERT tokenizer 训练保存编解码全流程
- 语料库分批加载与处理
从头快速训练一个 tokenzier
准备数据
数据用wikitext-103 (516M of text) ,每行一条文本。下载并解压到本地
wget https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-103-raw-v1.zip
unzip wikitext-103-raw-v1.zip
开始训练
以BPE tokenizer为例,主要步骤是:实例化 BPE tokenizer、BpeTrainer,调用 tokenizer.train 训练,调用 tokenizer.save 保存成json文件。
from tokenizers import Tokenizer
from tokenizers.models import BPE
from tokenizers.trainers import BpeTrainer
from tokenizers.pre_tokenizers import Whitespace
# Step 1:实例化一个空白的BPE tokenizer
tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
# Step 2:实例化一个BPE tokenizer 的训练器 trainer 这里 special_tokens 的顺序决定了其id排序
trainer = BpeTrainer(
special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"],
min_frequency=1,
show_progress=True,
vocab_size=40000
)
# Step 3:定义预分词规则(比如以空格预切分)
tokenizer.pre_tokenizer = Whitespace()
# Step 4:加载数据集 训练tokenizer
files = [f"./wikitext-103-raw/wiki.test.raw"]
tokenizer.train(files, trainer)
# Step 5:保存 tokenizer
tokenizer.save("./tokenizer-wiki.json")
训练完后得到一个json文件,里面长这样:
加载并使用训练好的tokenizer
# 加载 tokenzier
tokenizer = Tokenizer.from_file("./tokenizer-wiki.json")
# 使用 tokenizer
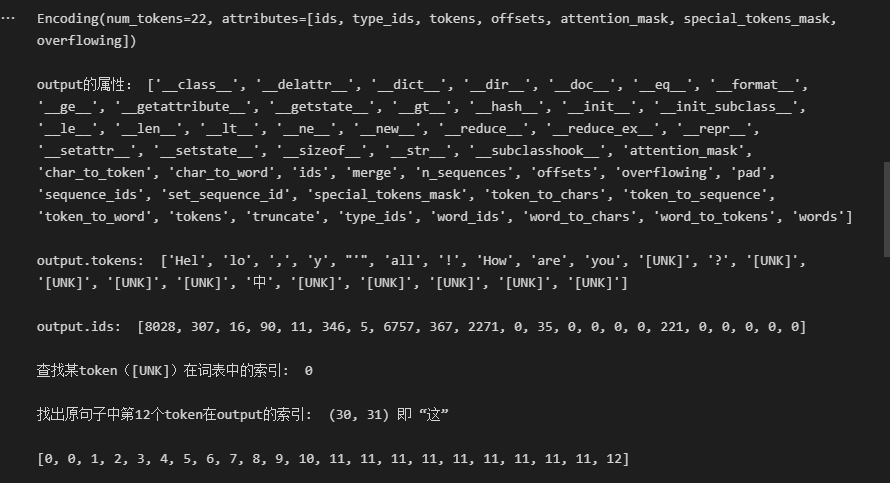
sentence = "Hello, y'all! How are you 😁 ? 这句话的中文是什么?"
output = tokenizer.encode(sentence)
print(output, "\n")
print("output的属性:", dir(output), "\n")
print("output.tokens: ", output.tokens, "\n")
print("output.ids: ", output.ids, "\n")
print("查找某token([UNK])在词表中的索引: ", tokenizer.token_to_id("[UNK]"), "\n")
i = 12
print(f"找出原句子中第{i}个token在output的索引: ", output.offsets[i], f"即 “{sentence[output.offsets[i][0]:output.offsets[i][1]]}”", "\n")
自定义后处理模版
自定义后处理模版(比如给句子前后自动加[CLS]和[SEP]),并重新存一份包含后处理功能的 tokenizer。
# $A 指第一个句子,$A:0 表示第一个句子中token的type_ids全是0,默认是0故省略([SEP]:0同理)
# $B 指第一个句子,$B:1 表示第一个句子中token的type_ids全是1([SEP]:1 同理)
from tokenizers.processors import TemplateProcessing
tokenizer.post_processor = TemplateProcessing(
single="[CLS] $A [SEP]",
pair="[CLS] $A [SEP] $B:1 [SEP]:1",
special_tokens=[
("[CLS]", tokenizer.token_to_id("[CLS]")),
("[SEP]", tokenizer.token_to_id("[SEP]")),
],
)
tokenizer.save("./tokenizer-wiki-with-template.json")
output = tokenizer.encode("Hello, y'all!", "How are you 😁 ?")
print(output, "\n")
print(output.type_ids, "\n")
print(output.tokens, "\n")

批量处理与PAD补全
传入list中的可以是str类型的单句,也可以是list类型的句子对儿。批处理时可以用 tokenizer.enable_padding 将这个批次的句子pad成该批次最大句子长度,当然,也可以pad成一个固定长度。被pad部分不计算attention,所以attention_mask的值为0。
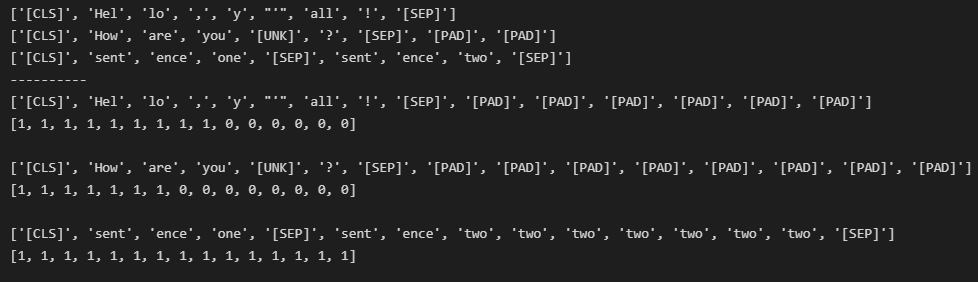
# 批量编码(无pad)
outputs = tokenizer.encode_batch([
"Hello, y'all!",
"How are you 😁 ?",
["sentence one", "sentence two"]
])
for output in outputs:
print(output.tokens)
print("-"*10)
# 批量编码(有pad)
tokenizer.enable_padding(pad_id=0, pad_token="[PAD]") # pad_id 默认是0。因为可能有不同的pad形式,所以用pad_id来区分
outputs = tokenizer.encode_batch([
"Hello, y'all!",
"How are you 😁 ?",
["sentence one", "sentence two two two two two two two"]
])
for output in outputs:
print(output.tokens)
print(output.attention_mask) # 被pad的部分不计算attention,所以attention_mask为0
print()
使用预训练的 tokenzier
从Hugging hub里加载
在 huggingface hub 中的模型,只要有 tokenizer.json 文件就能直接用 from_pretrained 加载。
from tokenizers import Tokenizer
tokenizer = Tokenizer.from_pretrained("bert-base-uncased")
output = tokenizer.encode("This is apple's bugger! 中文是啥?")
print(output.tokens)
print(output.ids)
print(tokenizer.get_vocab_size())

从词表文件里加载
还可以从.txt 词表文件里(每行一个token)加载,得指定已经实现的 Tokenizer 类,比如 BertWordPieceTokenizer。
from tokenizers import BertWordPieceTokenizer
tokenizer = BertWordPieceTokenizer("./bert-base-uncased-vocab.txt", lowercase=True)
output = tokenizer.encode("This is apple's bugger! 中文是啥?")
print(output.tokens)
print(output.ids)
print(tokenizer)

Tokenization 全过程详解
调用 Tokenizer.encode 或 Tokenizer.encode_batch 时,文本经过了以下过程:
- normalization:对原始输入做诸如转小写,去除空格等处理。
- pre-tokenization:把语料库进行拆分,数量为最终词表量的上限,训练时就基于这个拆分结果进行操作。
- model:初始化Tokenizer时传入,比如BPE
- post-processing:后处理
Step1. Normalization
Normalization 对文本进行初次清洗和处理。这里分别进行Unicode正规化、去除读音、转小写等三步。
from tokenizers import normalizers
from tokenizers.normalizers import NFD, StripAccents, Lowercase
# 定义一个normalizer
normalizer = normalizers.Sequence([
NFD(), # Unicode正规化
StripAccents(), # 去除读音
Lowercase()] # 转小写
)
normalizer.normalize_str("Héllò hôw are ü?")
# Output: 'hello how are u?'
tokenizer.normalizer = normalizer # 更新到tokenizer里
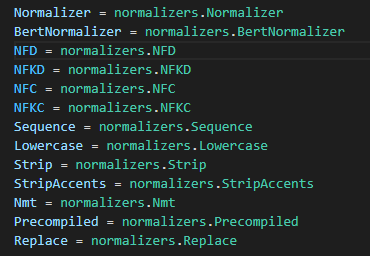
官方代码自带以下这些 normalizers(详见文档举例)(NFD,NFKD,NFC,NFKC,Lowercase,Strip,StripAccents,Replace,BertNormalizer,lowercase):
Step2. Pre-Tokenization
然后是 Pre-Tokenization。比如以空格进行切分,输出一个list,各元素均为元组。代码如下:
from tokenizers.pre_tokenizers import Whitespace
pre_tokenizer = Whitespace()
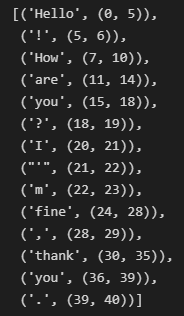
pre_tokenizer.pre_tokenize_str("Hello! How are you? I'm fine, thank you.")
也可以用 pre_tokenizers.Sequence 调用多个 pre_tokenizers。
from tokenizers import pre_tokenizers
from tokenizers.pre_tokenizers import Digits
pre_tokenizer = pre_tokenizers.Sequence([
Whitespace(),
Digits(individual_digits=True) # 如果 individual_digits=False,“911”就不会被单独分成数字
])
pre_tokenizer.pre_tokenize_str("Call 911! How are you? I'm fine thank you")
tokenizer.pre_tokenizer = pre_tokenizer # 更新到tokenizer里

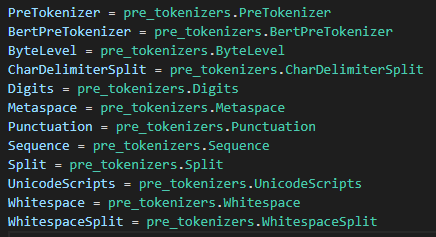
官方代码自带的pre-tokenizer(详见文档举例)有ByteLevel,Whitespace,WhitespaceSplit,Punctuation,Metaspace,CharDelimiterSplit,Digits,Split:
Step3. Model
这一步负责把word拆成token,并把token映射成id。初始化Tokenizer时需要传入这个model,比如第一部分“开始训练”那块的代码 tokenizer = Tokenizer(BPE(unk_token="[UNK]")) 。
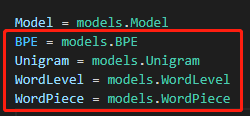
官方代码自带这四个 Model(详见文档举例):WordLevel、BPE、WordPiece、Unigram,也可参考我之前的文章,对这几个算法有详细解释。
Step4. Post-Processing
最后是后处理,实现比如加special token([CLS]、[SEP])等操作。具体可参考前面“自定义后处理模版”的部分。显然,pre-tokenizer 或者 normalizer 修改之后得重新训 tokenzier,而后处理改了就不用重新训。
BERT tokenizer 训练保存编解码全流程
训练bert tokenizer流程
下面是根据上面4步,训练bert tokenizer的全流程:用WordPiece进行分词;用Lowercase, NFD, StripAccents 进行正规化;用Whitespace进行前处理等等,详见代码。
from tokenizers import Tokenizer
from tokenizers.models import WordPiece
from tokenizers import normalizers
from tokenizers.normalizers import Lowercase, NFD, StripAccents
from tokenizers.pre_tokenizers import Whitespace
from tokenizers.processors import TemplateProcessing
from tokenizers.trainers import WordPieceTrainer
# 用 WordPiece 实例化 Tokenizer
bert_tokenizer = Tokenizer(WordPiece(unk_token="[UNK]"))
# 用 Unicode正则化、去除读音、转小写等流程实例化 normalizer,赋给 bert_tokenizer 对象
bert_tokenizer.normalizer = normalizers.Sequence([NFD(), Lowercase(), StripAccents()])
# 用空格和标点进行前处理分词
pre_tokenizer = Whitespace()
bert_tokenizer.pre_tokenizer = pre_tokenizer
# 定义对单句、句对儿做后处理的规则
bert_tokenizer.post_processor = TemplateProcessing(
single="[CLS] $A [SEP]",
pair="[CLS] $A [SEP] $B:1 [SEP]:1",
special_tokens=[
("[CLS]", 1),
("[SEP]", 2),
],
)
# 实例化一个 WordPieceTrainer,加载数据,训练并保存
trainer = WordPieceTrainer(
vocab_size=30522,
special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"]
)
files = [f"./wikitext-103-raw/wiki.{split}.raw" for split in ["test", "train", "valid"]]
bert_tokenizer.train(files, trainer)
bert_tokenizer.save("bert-wiki.json")
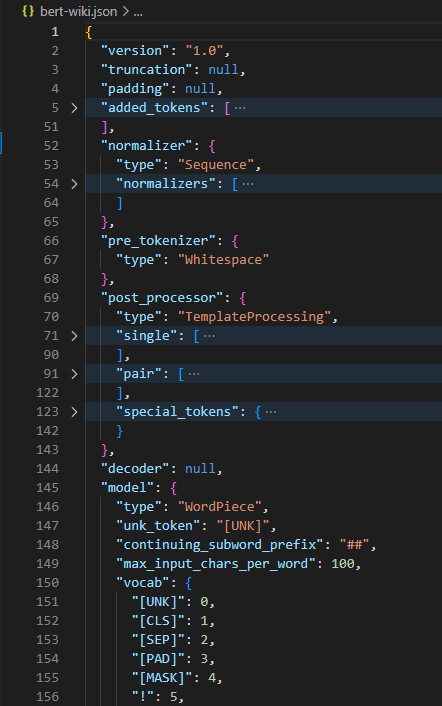
训完之后得到 bert-wiki.json 文件,长这样:
训练完的 BERT tokenizer 编解码测试
decoder 为默认(null)时,解码会有 ##zer 这种没合并的 token;decoder 基于 WordPiece 时,会对结果进行合并,因为训练时就用的 WordPiece 算法,所以对应的解码器实现了合并的过程。代码如下:
from tokenizers import decoders, Tokenizer
# 编解码测试:加载 tokenizer 文件
bert_tokenizer = Tokenizer.from_file("./bert-wiki.json")
# decoder 为默认(null)时,解码会有 '##zer' 这种没合并的 token
encoded_output = bert_tokenizer.encode("Welcome to the 🤗 Tokenizers library.")
print(encoded_output.tokens)
decoded_output = bert_tokenizer.decode(encoded_output.ids)
print(decoded_output)
# decoder 基于 WordPiece 时,会对结果进行合并
bert_tokenizer.decoder = decoders.WordPiece()
decoded_output = bert_tokenizer.decode(encoded_output.ids)
print(decoded_output)

除了 WordPiece 之外,官方代码里还有 ByteLevel、Metaspace 共三种 Decoder,详见文档。
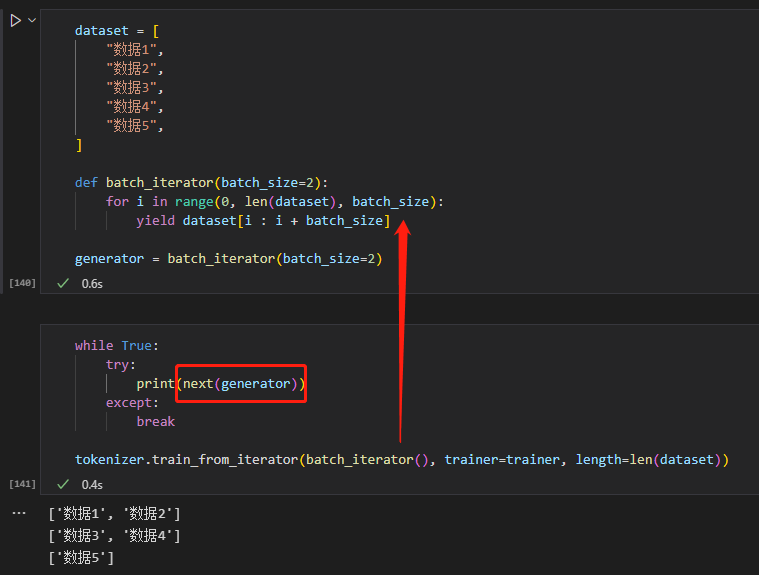
语料库分批加载与处理
如果一次性加载语料库加载不进来,则可以使用迭代器分批次加载,使用 tokenizer.train_from_iterator 方法,或参考API文档。
官方文档:https://huggingface.co/docs/tokenizers

















 184
184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









