







from sklearn.covariance import EmpiricalCovariance
parameters:
store_precision : bool
Specifies if the estimated precision is stored.
assume_centered : bool
If True, data are not centered before computation. Useful when working with data whose mean is almost, but not exactly zero. If False (default), data are centered before computation.
if assume_centered:
covariance = np.dot(X.T, X) / X.shape[0]
else:
covariance = np.cov(X.T, bias=1)
--from source code
bias : bool, optional
Default normalization (False) is by ``(N - 1)``, where ``N`` is the
number of observations given (unbiased estimate). If `bias` is True, then
normalization is by ``N``. These values can be overridden by using the
keyword ``ddof`` in numpy versions >= 1.5.
attributes:
covariance_ : 2D ndarray, shape (n_features, n_features)
Estimated covariance matrix
precision_ : 2D ndarray, shape (n_features, n_features)
Estimated pseudo-inverse matrix. (stored only if store_precision is True)
methods:
error_norm(comp_cov[, norm, scaling, squared]) | Computes the Mean Squared Error between two covariance estimators. |
fit(X[, y]) | Fits the Maximum Likelihood Estimator covariance model according to the given training data and parameters. |
get_params([deep]) | Get parameters for this estimator. |
get_precision() | Getter for the precision matrix. |
mahalanobis(observations) | Computes the squared Mahalanobis distances of given observations. |
score(X_test[, y]) | Computes the log-likelihood of a Gaussian data set with self.covariance_ as an estimator of its covariance matrix. |
set_params(\*\*params) | Set the parameters of this estimator. |
score:
def score(self, X_test, y=None):
"""Computes the log-likelihood of a Gaussian data set with
`self.covariance_` as an estimator of its covariance matrix.
Parameters
----------
X_test : array-like, shape = [n_samples, n_features]
Test data of which we compute the likelihood, where n_samples is
the number of samples and n_features is the number of features.
X_test is assumed to be drawn from the same distribution than
the data used in fit (including centering).
y : not used, present for API consistence purpose.
Returns
-------
res : float
The likelihood of the data set with `self.covariance_` as an
estimator of its covariance matrix.
"""
# compute empirical covariance of the test set
test_cov = empirical_covariance(
X_test - self.location_, assume_centered=True)
# compute log likelihood
res = log_likelihood(test_cov, self.get_precision())
return resdef log_likelihood(emp_cov, precision):
"""Computes the sample mean of the log_likelihood under a covariance model
computes the empirical expected log-likelihood (accounting for the
normalization terms and scaling), allowing for universal comparison (beyond
this software package)
Parameters
----------
emp_cov : 2D ndarray (n_features, n_features)
Maximum Likelihood Estimator of covariance
precision : 2D ndarray (n_features, n_features)
The precision matrix of the covariance model to be tested
Returns
-------
sample mean of the log-likelihood
"""
#-------------------------------------------------------------------------
p = precision.shape[0]
log_likelihood_ = - np.sum(emp_cov * precision) + fast_logdet(precision)
log_likelihood_ -= p * np.log(2 * np.pi)
log_likelihood_ /= 2.
return log_likelihood_
#-------------------------------------------------------------------------
error_norm:
def error_norm(self, comp_cov, norm='frobenius', scaling=True,
squared=True):
"""Computes the Mean Squared Error between two covariance estimators.
(In the sense of the Frobenius norm).
Parameters
----------
comp_cov : array-like, shape = [n_features, n_features]
The covariance to compare with.
norm : str
The type of norm used to compute the error. Available error types:
- 'frobenius' (default): sqrt(tr(A^t.A))
- 'spectral': sqrt(max(eigenvalues(A^t.A))
where A is the error ``(comp_cov - self.covariance_)``.
scaling : bool
If True (default), the squared error norm is divided by n_features.
If False, the squared error norm is not rescaled.
squared : bool
Whether to compute the squared error norm or the error norm.
If True (default), the squared error norm is returned.
If False, the error norm is returned.
Returns
-------
The Mean Squared Error (in the sense of the Frobenius norm) between
`self` and `comp_cov` covariance estimators.
"""
mahalanobis:
def mahalanobis(self, observations):
"""Computes the squared Mahalanobis distances of given observations.
Parameters
----------
observations : array-like, shape = [n_observations, n_features]
The observations, the Mahalanobis distances of the which we
compute. Observations are assumed to be drawn from the same
distribution than the data used in fit.
Returns
-------
mahalanobis_distance : array, shape = [n_observations,]
Squared Mahalanobis distances of the observations.
"""
precision = self.get_precision()
# compute mahalanobis distances
centered_obs = observations - self.location_
#-------------------------------------------------------------
mahalanobis_dist = np.sum(
np.dot(centered_obs, precision) * centered_obs, 1)
#-------------------------------------------------------------
return mahalanobis_dist
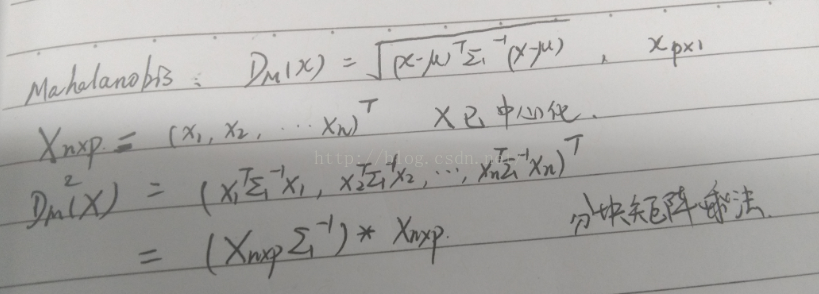















 132
132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









