







数据库设计就是根据业务系统的具体需求,结合我们所选用的DBMS(数据库管理系统),为这个业务系统构造出最优的数据库存储模型
| 优良的设计 | 糟糕的设计 |
|---|---|
| 减少数据冗余 | 存在大量的数据冗余 |
| 避免数据维护异常 | 存在数据插入,更新,删除异常 |
| 节约存储空间 | 浪费大量的存储空间 |
| 高效的访问 | 访问数据低效 |
ps:某个列的数据可以由其他列计算得到,也称为数据冗余。
第一部分 数据库设计流程
一个完整的数据库设计流程包含以下四个组成部分:需求分析、逻辑设计、物理设计和维护优化

1. 需求分析
需求分析主要的任务是分析:
- 数据是什么
- 数据有哪些属性
- 数据和属性各自的特点有哪些
2. 逻辑设计
逻辑设计就是使用ER图对数据库进行逻辑建模
一个简单的例子如下:
图中:矩形表示实体集,菱形表示联系集,椭圆表示实体的属性,线段将属性连接到实体集或将实体集连接到联系集
3. 物理设计
根据数据库自身的特点将逻辑设计转换为物理设计
4. 维护优化
主要任务包括:
- 新的需求进行建表
- 索引优化
- 大表拆分
第二部分 数据库设计范式
参考链接:https://www.cnblogs.com/gdwkong/p/9012262.html
常见的数据库设计范式包括:第一范式,第二范式,第三范式及BC范式,这是目前我们大多数数据库设计所要遵循的范式。
在了解范式之前,我们有必要了解一下数据操作异常及数据冗余的定义。
- 插入异常:如果某实体随着另一个实体的存在而存在,即缺少某个实体时无法表示这个实体,那么这个表就存在插入异常
- 更新异常:如果更改表所对应的某个实体市里的单独属性时,需要将多行更新,那么就说这个表存在更新异常
- 删除异常:如果删除表的某一行来反映某实体实例失效时导致另一个不同实体实例信息丢失,那么这个表就存在删除异常
1. 第一范式(1NF)
定义:数据库表中的所有字段都是单一属性,不可再分的。
1NF是所有关系型数据库的最基本要求,你在关系型数据库管理系统(RDBMS),例如SQL Server,Oracle,MySQL中创建数据表的时候,如果数据表的设计不符合这个最基本的要求,那么操作一定是不能成功的。
关键点:字段不可分,解释:原子性 字段不可再分,否则就不是关系数据库。
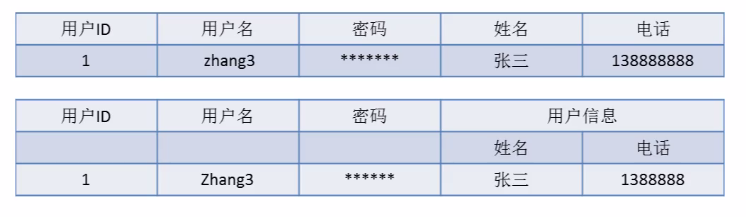
2. 第二范式(2NF)
定义:数据库的表中不存在非关键字段对任一候选关键字段的部分函数依赖。
部分函数依赖是指存在着组合关键字中的某一关键字决定非关键字的情况。
换句话说:所有单关键字段的表都符合第二范式。即每条记录的字段值都只能由一个关键字决定
关键点:有主键,非主键字段依赖主键; 解释:唯一性 一个表只说明一个事物。
举一个简单的例子:

在这里使用商品名称和供应商名称标识出一件商品
上表存在以下的部分函数依赖关系:商品名称—>价格、描述、重量、商品有效期供应商名称—>供应商电话
存在问题:插入异常、删除异常、更新异常、数据冗余
所以对上表进行拆分:
3. 第三范式(3NF)
定义:第三范式是在第二范式的基础上定义的,如果数据表中不存在非关键字段对任意候选关键字段的传递函数依赖则符合第三范式。
关键点:非主键字段不能相互依赖; 解释:每列都与主键有直接关系,不存在传递依赖;
举一个简单的例子:

PS:商品 —> 分类 —> 分类描述,分类描述传递依赖于商品,修改为:
4. Boyce.Codd范式(BCNF)
定义:在第三范式的基础之上,数据库表中如果不存在任何字段对任一候选关键字段的传递函数依赖则符合BC范式。
也就是说如果是复合关键字,则复合关键字之间也不能存在函数依赖关系
举一个简单的例子:
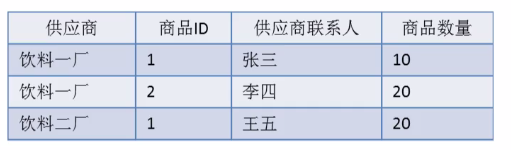
假定:供应商联系人只能受雇于一家供应商,每家供应商可以供应多个商品,则存在如下决定关系:
(供应商,商品id)—>(供应商联系人,商品数量)
(供应商联系人,商品id)—>(供应商,商品数量)
所以有两种组合关键字的选择
存在以下关系不符合BCNF要求:
(供应商)->(供应商联系人)
(供应商联系人)->(供应商)
并且存在数据操作异常和数据冗余
所以要拆表:
第三部分 物理设计细节(以MySql为例)
根据数据库自身的特点把逻辑设计转换为物理设计
物理设计要做什么:
- 选择合适的数据库管理系统
- 定义数据库、表及字段的命名规范
- 根据所选的DBMS系统选择合适的字段类型
- 反范式设计
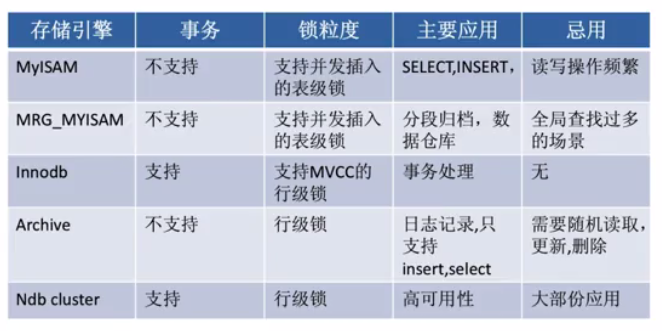
1. MySql常用的存储引擎
MySQL常用的存储引擎(建议使用Innodb引擎):
MySQL如何设置存储引擎:https://jingyan.baidu.com/article/f3ad7d0f50e9be09c3345ba1.html
表级锁与行级锁:https://www.cnblogs.com/guanghe/p/9217421.html
2. 定义数据库、表及字段的命名规范
表及字段的命名规范:
1) 可读性原则
使用大写和小写来格式化库对象名字以获取良好的可读性
例如:使用CustAddress而不是custaddress来提高可读性(这里要注意的是有些DBMS系统对表名的大小写是敏感的)
2) 表意性原则,对象的名字应该能够描述它所标识的对象
3) 长名原则,尽可能少使用或者不使用缩写,适用于数据库名之外的任一对象。
3. 根据所选的DBMS系统选择合适的字段类型
列的数据类型一方面影响数据存储空间的开销,另一方面也会影响数据查询性能。当一个列可以选择多种数据类型时,应该优先考虑数字类型,其实是时间或二进制类型,最后是字符类型。对于相同级别的数据类型,应该优先选择占用空间小的数据类型。
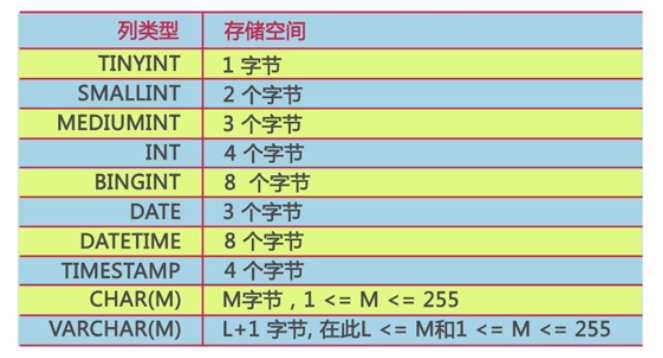
MySQL的TIMESTAMP只能存储到2037年。
以上选择原则主要从下面两个角度考虑:
1) 在对数据进行比较(查询条件、join条件及排序)操作时,同样的数据,字符处理往往比数字处理慢。
2) 在数据库中,数据处理以页为单位,列的长度越小,利用性能越高。
char与archer如何选择?
1) 如果列中要存储的数据长度差不多是一致的(例如电话或身份证号码),应该考虑用char,否则应该考虑用varchar
2) 如果列中的数据最大长度小于50byte,则一般也考虑使用char(当然,如果这个列很少用,则基于节省空间和减少I/O的考虑,还可以使用varchar)
3) 一般不宜定于大于50byte的char类型列
decimal与float如何选择?
1) decimal用于存储精确数据,而float只能由于存储非精确数据,故精确数据只能选择用decimal类型
2) 由于float的存储空间开销一般比decimal下(精确到7位小数只需啊4个字节,而精确到15位小数只需要8字节),故非精确数据优先选择float类型
时间类型如何存储?
1) 使用int来存储时间字段的优缺点
优点:字段长度比datetime小
缺点:使用不方便,要进行函数转换
限制:只能存储到2038-1-19 11:14:07 即 2^32
2) 需要考虑存储的时间粒度
如存储是年还是月等
其它注意事项
如何选择主键?
1) 区分业务主键和数据库主键
业务主键用于标识业务数据,进行表与表之间的关联
数据库主键为了优化数据存储(Innodb会生成6个字节的隐含主键)
2) 根据数据库的类型,考虑主键是否要顺序增长
有些数据库是按主键的顺序逻辑存储的
3) 主键的字段类型所占空间要尽可能的小
对于使用聚集索引方式存储的表,每个索引后都会附加主键信息
PS:数据库一般是按照主键逻辑顺序存储的
避免使用外键约束
1) 降低数据导入的效率
2) 增加维护成本
3) 虽然不建议使用外键约束,但是相关联的列上一定要建立索引
PS:高并发数据库尽量不要使用外键约束
避免使用触发器
1) 降低数据导入的效率
2) 可能会出现意想不到的数据异常
3) 使业务逻辑变的复杂
触发器:https://baike.baidu.com/item/%E8%A7%A6%E5%8F%91%E5%99%A8/16782
约束作用于同一张表,触发器可以跨表
关于预留字段
1) 无法准确的知道预留字段的类型
2) 无法准确知道预留字段中所存储的内容
3) 后期维护预留字段所要的成本,同增加一个字段所需要的成本是相同的
4) 严禁使用预留字段
4、反范式设计
反范式化是针对范式化而言的,在前面介绍了数据库设计的第三范式,所谓的反范式化就是为了性能和读取效率的考虑而适当的对第三范式的要求进行违反,而允许存在少量的数据冗余
换句话说反范式化就是使用空间来换取时间
反范式设计的原因:
- 减少表的关联数量
- 增加数据的读取数量
- 反范式一定要适度
第四部分 维护优化细节
维护与优化要做什么
- 维护数据字典
- 维护索引
- 维护表结构
- 在适当的时候对表进行水平拆分或垂直拆分
1. 如何维护数据字典
- 利用第三方工具对数据字典进行维护
- 利用数据库本身的备注字段来维护数据字典,以MySQL为例:

- 导出数据字典
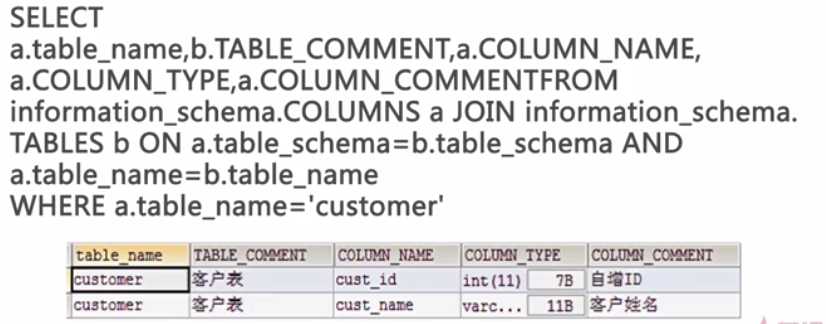
2. 如何维护索引
如何选择合适的列建立索引:
- 出现在WHERE从句,GROUP BY从句中的列
- 可选择性高的列要放到索引的前面
- 索引中不要包含太长的数据类型
注意事项:
- 索引并不是越多越好,过多的索引不但会降低写效率而且会降低读的效率
- 定期维护索引碎片
- 在SQL语句中不要使用强制索引关键字
SQL语句如何使用索引:https://blog.csdn.net/xingkongtianma01/article/details/80658086
3. 如何维护表结构
注意事项
- 使用在线变更表结构的工具
MySQL5.5之前可以使用pt-online-schema-change;
MySQL5.6之后本身支持在线表结构的变更;
- 同时对数据字典进行维护
- 控制表的宽度和大小
数据库中适合的操作
- 批量操作VS逐条操作
- 禁止使用SELECT * 这样的查询
- 控制使用用户自定义函数
- 不要使用数据库中全文索引
4. 在适当的时候对表进行水平拆分或垂直拆分
为了控制表的宽度可以进行表的垂直拆分
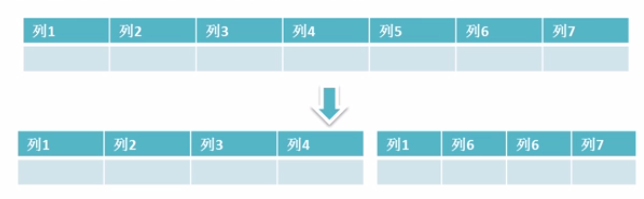
1) 经常一起查询的列放在一起
2) text,blob等大字段拆分出到附加表中
为了控制表的大小可以进行表的水平拆分
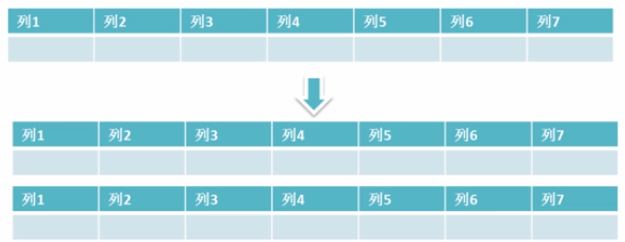
可以通过主键哈希的方式
















 323
323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









