







python拥有直接操作excel表格的第三方库xlwt,xlrd。调用对应的方法就可以读写excel表格数据。
读取excel操作代码如下:
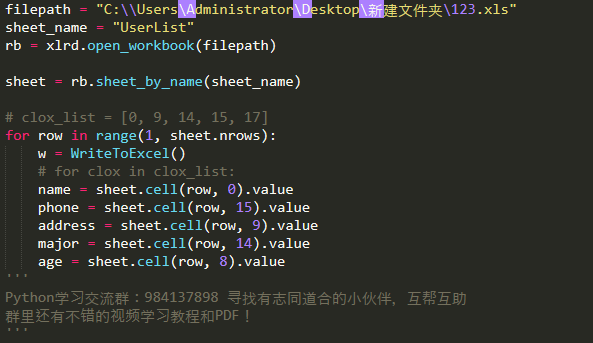
其中row是表格数据对应的行数, cell获取具体行数,列数的具体数据。
三、Python读取doc文档数据
python读取doc文档是最麻烦的。处理逻辑复杂。处理的方式也有很多种。
python 没有直接处理doc文档的第三方库,但是有一个处理docx的第三方库。可以通过将doc文件转换为docx文件,再调用第三方python库pydocx来读取doc文档的内容。
这里需要注意的是,不要直接修改doc的后缀来修改成docx文件。直接通过修改后缀获取的docx文件,pydocx无法读取内容。
我们可以使用另外一个库来修改doc为docx。
具体代码如下:
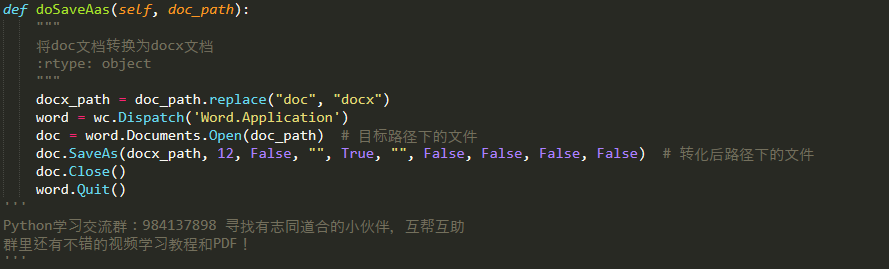
代码所需的包接口:
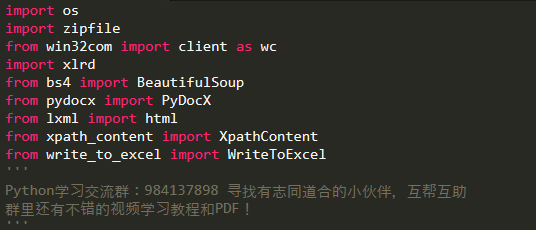
python处理docx文档的方法有很多种,具体使用情况,根据个人需求来决定。
No.1 解压docx文件
docx文件的原理,本质上就是一个压缩的zip文件,通过解压以后,就可以获取原来文件的各个内容。
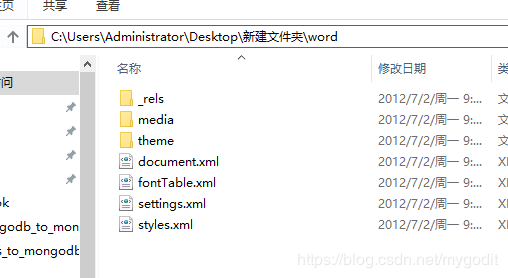
docx解压后的文件结构如下:

docx文件的文本内容存储结构如下:
文本内容存储于word/document.xml文件中。
第一种方法,我们就可以先将docx还原成zip压缩文件,再解压zip文件,读取word/document.xml文件的内容就ok了。
具体操作代码如下:
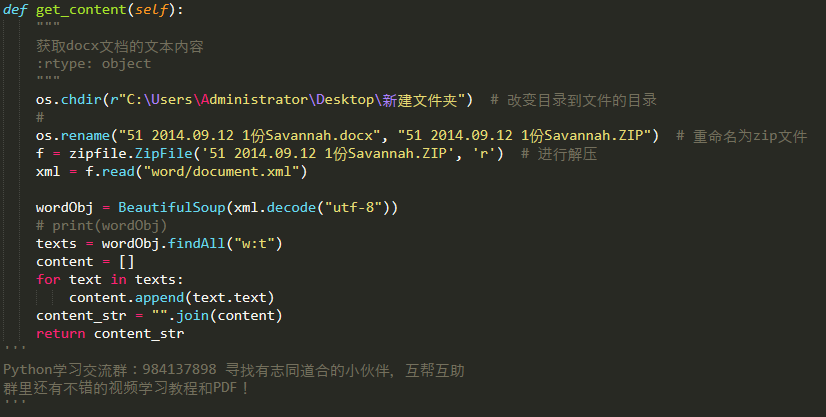
最后获取到的就是docx文档的所有文本数据了。
No.2 将docx文档转换成python能够处理的文本格式
第一种方法,是依据docx文档的原理来获取数据,流程有点繁琐,有没有能直接读取docx文档内容的方法呢?答案,肯定是没有的,别想了,洗洗回家睡吧。
直接读取docx文档的方法没有,有没有能够将docx文档转换成python能够轻松处理的文本格式呢?
这个可以有,前面说了,python拥有大量丰富的第三方库(先夸一波我大python),历经千辛万苦终于找到了,一个能转换docx文档格式的第三方库,pydocx,pydocx库中有个方法pydocx.to_html()就可以直接将docx文档转换为html文件,怎么样?意不意外,惊喜不惊喜!
第二种方法,转换文本格式的代码如下:
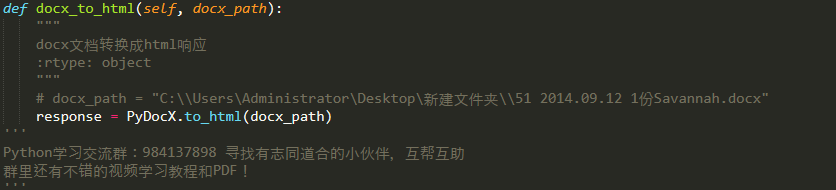
获取到的response是html文件内容。
四、Python处理mht文件
mht文件是一种只能在IE浏览器上展示的文本格式,在chrome浏览器中打开是一堆的乱码。
No.1 伪造IE请求mht文件内容
最基础的读取mht文本的方法就是伪造IE浏览器请求。
调用requests库,发送get请求网页链接,构造IE的请求头信息。
理论上来说,这种方法是可行的。但是呢,不建议用,原因大家都懂得。


感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 9058
9058











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









