







在E:\0.code\2014drebin\drebin-master\newpaper文件中进行测试
样本的特征值与模型的权重向量相乘代表什么
样本的特征值与模型的权重向量相乘(即点积)代表每个特征在模型预测中所起的作用或贡献。具体来说,在线性分类模型(如线性支持向量机(Linear SVM)或线性回归模型)中,这种乘法计算表示每个特征对决策函数输出的影响。
详细解释
假设我们有一个线性模型,其决策函数表示为:

点积的意义
点积计算表示每个特征值与其对应的权重相乘,然后将这些乘积相加得到一个总和,这个总和反映了模型对给定样本的预测:
![]()

例子
假设我们有一个简单的二分类问题,通过一个线性模型进行预测。假设模型的权重向量 w和一个样本的特征向量 x如下:

预测解释
- 第一个特征:权重为 0.2,特征值为 0.5,对预测结果贡献了 0.10。
- 第二个特征:权重为 -0.1,特征值为 0.3,对预测结果贡献了 −0.03。
- 第三个特征:权重为 0.4,特征值为 0.2,对预测结果贡献了 0.08。
总的贡献值 0.15 是决策函数的输出(忽略偏置项),通常这个值再经过一个激活函数(例如 SVM 中的符号函数)得到最终的分类结果。
在代码中的应用
在你的代码中,点积计算用于解释模型预测时各个特征的贡献:
for i in range(v.shape[0]):
wx = v[i, :] * w # 计算每个特征的权重贡献
wv_vocab = list(zip(wx, vocab)) # 将特征权重与特征名称配对
# 对特征权重进行排序并提取前几个重要特征
if y_pred[i] == 1:
wv_vocab.sort(reverse=True)
explanations[os.path.basename(x_test_samplenames[i])]['top_features'] = wv_vocab[:NumTopFeats]
elif y_pred[i] == -1:
wv_vocab.sort()
explanations[os.path.basename(x_test_samplenames[i])]['top_features'] = wv_vocab[-NumTopFeats:]
通过这种方式,你可以识别出在每个样本的预测中最重要的特征,并生成相应的解释。
classification_report(y_test, y_pred, target_names=newsgroups_test.target_names)
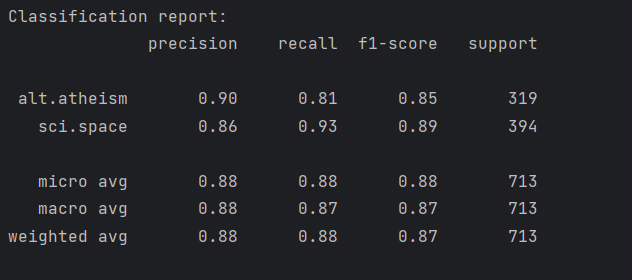
classification_report 是 Scikit-learn 中一个用于评估分类模型性能的函数。它生成了分类结果的详细报告,包含了每个类的精确度 (precision)、召回率 (recall)、F1 分数 (F1-score) 和支持数 (support)。让我们详细解释一下你的代码中的这部分:
print(classification_report(y_test, y_pred, target_names=newsgroups_test.target_names))
其中:
y_test是测试集的真实标签。y_pred是模型对测试集的预测标签。target_names是标签对应的类别名称,即newsgroups_test.target_names。
classification_report 会生成如下形式的报告:
让我们解释每一列的含义:
-
precision(精确度):
- 精确度是指在所有被预测为正类的样本中,实际为正类的比例。公式为:
TP / (TP + FP),其中TP是真正类(true positives),FP是假正类(false positives)。 - 例如,如果有100个样本被预测为
class0,其中80个样本实际为class0,那么class0的精确度为0.80。
- 精确度是指在所有被预测为正类的样本中,实际为正类的比例。公式为:
-
recall(召回率):
- 召回率是指在所有实际为正类的样本中,被正确预测为正类的比例。公式为:
TP / (TP + FN),其中FN是假负类(false negatives)。 - 例如,如果实际有100个
class0的样本,其中85个被正确预测为class0,那么class0的召回率为0.85。
- 召回率是指在所有实际为正类的样本中,被正确预测为正类的比例。公式为:
-
f1-score(F1 分数):
- F1 分数是精确度和召回率的调和平均数。公式为:
2 * (precision * recall) / (precision + recall)。 - F1 分数综合了精确度和召回率,给出一个总体的评估分数。
- F1 分数是精确度和召回率的调和平均数。公式为:
-
support(支持数):
- 支持数是指每个类在测试集中实际的样本数量。
- 例如,如果有200个样本实际属于
class0,那么支持数为200。
-
accuracy(准确率):
- 准确率是指所有分类正确的样本数占总样本数的比例。公式为:
(TP + TN) / (TP + TN + FP + FN)。 - 例如,如果总共有400个测试样本,其中312个被正确分类,那么准确率为0.78。
- 准确率是指所有分类正确的样本数占总样本数的比例。公式为:
-
macro avg(宏平均):
- 宏平均是对每个类别的精确度、召回率和 F1 分数进行平均,不考虑每个类别的支持数。这种方法对各类别一视同仁。
- 例如,(0.80 + 0.75) / 2 = 0.78。
-
weighted avg(加权平均):
- 加权平均是对每个类别的精确度、召回率和 F1 分数按支持数加权平均。这种方法考虑了类别样本数量的不平衡。
- 例如,(0.80 * 200 + 0.75 * 200) / 400 = 0.78。
在你的例子中, target_names 对应的是 newsgroups_test.target_names,这两个类别是 ['alt.atheism', 'sci.space']。因此,报告将显示这两个类别的分类性能。
完整代码(例子)
data = fetch_20newsgroups(subset=subset, categories=categories, remove=('headers', 'footers', 'quotes'), data_home=data_home)是在调用 sklearn.datasets.fetch_20newsgroups 函数来下载并加载20类新闻组数据集,并将其存储在指定的文件夹中。具体参数的含义如下:
subset=subset:指定要加载的数据子集。可以是'train'(训练集),'test'(测试集),或者'all'(全部数据集)。categories=categories:指定要加载的新闻组类别。categories是一个包含类别名称的列表。在这个例子中,是['alt.atheism', 'sci.space']。remove=('headers', 'footers', 'quotes'):移除新闻组文本中的某些部分。'headers'会移除邮件头,'footers'会移除邮件脚,'quotes'会移除引用的部分。这有助于减少噪音,专注于邮件正文内容。data_home=data_home:指定数据集的下载位置。data_home参数设置了数据将被下载和存储的目录。在这个例子中,data_home是当前脚本所在的目录,因此数据集会被下载到这个目录中。
使用了网格搜索和支持向量机
E:\0.code\2014drebin\drebin-master\src\explaination.py
# -*- coding: utf-8 -*-
import os
import json
import time
import numpy as np
from tqdm import tqdm
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import LinearSVC
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
from sklearn.datasets import fetch_20newsgroups
from joblib import dump, load
# 获取当前脚本所在的目录
current_dir = os.path.dirname(os.path.abspath(__file__))
# 定义一个函数来显示数据加载进度
def fetch_20newsgroups_with_progress(subset, categories, data_home):
data = fetch_20newsgroups(subset=subset, categories=categories, remove=('headers', 'footers', 'quotes'), data_home=data_home)
for _ in tqdm(range(len(data.data)), desc="Loading {} data".format(subset)):
pass
return data
# 第一步:加载数据
categories = ['alt.atheism', 'sci.space']
newsgroups_train = fetch_20newsgroups_with_progress(subset='train', categories=categories, data_home=current_dir)
newsgroups_test = fetch_20newsgroups_with_progress(subset='test', categories=categories, data_home=current_dir)
# 定义保存数据的函数
# 定义保存数据的函数,使用 UTF-8 编码写入文件
# 定义保存数据的函数,兼容 Python 2.7
def save_to_txt(data, filename):
with open(filename, 'w') as file:
for i in range(len(data.data)):
file.write("Target: {}\n".format(data.target[i]))
file.write("Text: {}\n".format(data.data[i].encode('utf-8'))) # 使用 UTF-8 编码写入文本
file.write("="*50 + "\n") # 用于分隔不同的文档
# 保存训练集和测试集到 .txt 文件
save_to_txt(newsgroups_train, 'newsgroups_train.txt')
save_to_txt(newsgroups_test, 'newsgroups_test.txt')
print("Datasets have been saved to .txt files.")
# 将文本数据转换为TF-IDF特征
vectorizer = TfidfVectorizer()
x_train = vectorizer.fit_transform(newsgroups_train.data)
x_test = vectorizer.transform(newsgroups_test.data)
feature_names = vectorizer.get_feature_names()
print(feature_names)
y_train = newsgroups_train.target
y_test = newsgroups_test.target
x_test_samplenames = newsgroups_test.filenames # 测试集样本文件名
# 第二步:训练模型
Parameters = {'C': [0.001, 0.01, 0.1, 1, 10, 100, 1000]} # 定义超参数范围
T0 = time.time()
Clf = GridSearchCV(LinearSVC(max_iter=5000), Parameters, cv=5, scoring='f1', n_jobs=1) # 使用网格搜索和交叉验证寻找最佳模型
SVMModels = Clf.fit(x_train, y_train) # 训练模型
print("Processing time to train and find best model with GridSearchCV is %s sec." % (round(time.time() - T0, 2)))
BestModel = SVMModels.best_estimator_ # 获取最佳模型
print("Best Model Selected : {}".format(BestModel))
# 保存模型
filename = 'svm_model'
dump(Clf, filename + ".pkl") # 保存模型
# 第三步:在测试集上评估最佳模型
T0 = time.time()
y_pred = SVMModels.predict(x_test)
print("Classification report:")
print(classification_report(y_test, y_pred, target_names=newsgroups_test.target_names))
# 第四步:解释模型预测
w = BestModel.coef_
w = w[0].tolist()
v = x_test.toarray()
vocab = vectorizer.get_feature_names() # 获取特征名称,使用 get_feature_names 替代 get_feature_names_out
NumTopFeats = 10 # 选择前10个重要特征
explanations = {os.path.basename(s): {} for s in x_test_samplenames} # 初始化解释字典
for i in range(v.shape[0]):
wx = v[i, :] * w # 计算每个特征的权重贡献
wv_vocab = list(zip(wx, vocab)) # 将特征权重与特征名称配对
if y_pred[i] == 1:
wv_vocab.sort(reverse=True)
explanations[os.path.basename(x_test_samplenames[i])]['top_features'] = wv_vocab[:NumTopFeats]
elif y_pred[i] == 0:
wv_vocab.sort()
explanations[os.path.basename(x_test_samplenames[i])]['top_features'] = wv_vocab[-NumTopFeats:]
explanations[os.path.basename(x_test_samplenames[i])]['original_label'] = int(y_test[i])
explanations[os.path.basename(x_test_samplenames[i])]['predicted_label'] = int(y_pred[i])
# 保存解释字典为JSON文件
with open('explanations.json', 'w') as FH:
json.dump(explanations, FH, indent=4)
print("Explanations saved to explanations.json")















 1906
1906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









