







基于Supervised Learning Lecture 8
Multi-task learning
- Multi-task learning (MTL) is an approach to machine learning that learns a problem together with other related problems at the same time, using a shared representation. 1
- The goal of MTL is to improve the performance of learning algorithms by learning classifiers for multiple tasks jointly.
- Typical scenario: many tasks many tasks but only few examples per task. If n<d we don’t have enough data to learn the tasks one by one. However, if the tasks are related and set S or the associated regularizer captures such relationships in a simple way, learning the tasks jointly greatly improves over independent task learning (ITL).
- When problems (tasks) are closely related, learning in parallel can be more efficient than learning tasks independently. Also, this often leads to a better model for the main task, because it allows the learner to use the commonality among the tasks.
- Applications: Learning a set of linear classi ers for related objects
(cars, lorries, bicycles), user modelling, multiple object detection in scenes, affective computing, bioinformatics, health informatics, marketing science, neuroimaging, NLP, speech… - Further categorisation is possible, e.g. hierarchical models, clustering of tasks.
- The ideas can be extended to non-linear cases through RKHS.
Mathematical formulation
- Fix probability measures
μ1,⋯,μT
on
Rd×R
– T tasks
– Each task is a probability measure, e.g. μt(x,y)=P(x)δ(⟨w∗,x⟩−y) . δ is a deterministic function, interpreted as the conditional probability and wx is an underlying parameter
– Rd can also be a Hilbert space - Draw data: (xt1vector,yt1scalar),⋯,(xtn,ytn)∼μt,t=1,⋯,T (in practice n may vary with t)
- Learning method:
min(f1,⋯,fT)∈F1T∑t=1T1n∑i=1nℓ(yti,ft(xti))
where F is a set of vector-value functions. A standard choice is a ball in a RKHS, which models interactions between the tasks in the sense that functions with small norm have strongly related components. - Goal is to minimise the multi-task error
R(f1,⋯,fT)=1T∑t=1TE(x,y)∼μtℓ(yti,ft(xti))
Linear MTL
- “task” = “linear model”
– Regression: yti=⟨w∗t,xti⟩+ϵti
– Binary classification: yti=sign(⟨w∗t,xti⟩)ϵti - Learning method: min(w1,⋯,wT)∈S1T∑Tt=11n∑ni=1ℓ(yti,⟨w∗t,xti⟩) . Here, S incorporates the prior knowledge about the regression vector and encourages “common structure” among tasks, e.g. the ball of a matrix norm or other regulariser.
- The multitask error of W=[w1,⋯,wT] is: R(W)=1T∑Tt=1E(x,y)∼μtℓ(yti,⟨wt,x⟩)
- It is possible to give bounds on the uniform deviation
supW∈S{R(W)−1T∑t=1T1n∑i=1nℓ(yti,⟨wt,xti⟩)}
and derive bounds for excess error
R(W^)−minW∈SR(W)
Regularisers for linear MTL
Often we drop the constraint (i.e.
W∈S
) and consider the penalty methods
minw1,⋯,wT1T∑t=1T1n∑i=1nℓ(yti,⟨wt,xti⟩)+λΩ(w1,⋯,wT)
Different regularisers encourage different types of commonalities between the tasks:
- variance (or other convex quadratic regularisers) encourage closeness to mean
Ωvar=1T∑t=1T||wt||2+1−γγVar(w1,⋯,wT) - Joint sparsity (or other structured sparsity regularisers) encourage few shared variables
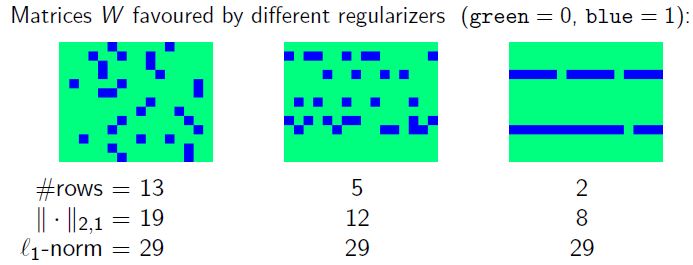
||W||2,1:=∑j=1d∑t=1Tw2tj−−−−−−⎷ - Trace norm (or other spectral regularisers which promote low rank solutions) encourage few shared features
||w1,⋯,wT||tr
– extension of joint sparsity; rotate the initial data representation
– The l1 norm of SVD of this matrix is bounded, so favour low-rank representation (i.e. common low-dimensional subspace) - More sophisticated regularisers which combine the above, promote clustering of tasks, etc.
Quadratic regulariser
- general quadratic regulariser
Ωvar=∑s,t=1T⟨ws,Estwt⟩
where the matrix E=(Est)Ts,t=1∈RdT×dT is positive definite.
- variance regulariser
Let γ∈[0,1] and
Ωvar=1T∑t=1T||wt||2+1−γγVar(w1,⋯,wT)=1T∑t=1T||wt||2+1−γγ∑t=1T||wt−w¯||22
– γ=1 : independent tasks; γ=0 : identical tasks
– regulariser favours weight vectors which are close to its mean.
– If we are working on SVM with hinge loss, the objective function is a compromise between maximising individual margins and minimising the variance (i.e. keeping the tasks close to each other) - Link to the kernel methods (quadratic regulariser)
The problem
minw1,⋯,wT1T∑t=1T1n∑i=1nℓ(yti,⟨wt,xti⟩)+λ∑s,t=1T⟨ws,Estwt⟩
is equivalent to
minv1T∑t=1T1n∑i=1nℓ(yti,⟨v,Btxti⟩)+λ⟨v,v⟩(1)
where Bt are p×d matrices (typically p≫d ) linked to E byE=(BTB)−1,Bdim=p×dT=[B1,⋯,BT]concatenate by columns and wt=(Bt)Tvt
Interpretation:
– We learn a single function (x,t)↦ft(x) using the feature map (x,t)↦Bt(x) and corresponding multitask kernel K((x1,t1),(x2,t2))=⟨Bt1x1,Bt2x2⟩
– Writing ⟨v,Btx⟩=⟨BTtv,x⟩ , we interpret this as having a single regression vector which is transformed by matrix Bt to obtain the task specific weight vector. - Link to the kernel methods (variance regulariser)
The problem
minw1,⋯,wT1Tn∑t,iℓ(yti,⟨wt,xti⟩)+λ(1T∑t=1T||wt||2+1−γγVar(w1,⋯,wT))
is equivalent to
minw0,u1,⋯,uT1Tn∑t,iℓ(yti,⟨w0+ut,xti⟩)+λ(1γT∑t=1T||ut||2+11−γ||w0||2)(2)
by setting wt=w0+ut and minimise over w0 .
It is of the form (1) with
vBTtdim=(T+1)d×d=((1−γ)−12w0,(γT)−12u1,⋯,(γT)−12uT)=[1−γ−−−−√Id×d,0d×d,⋯,0d×dt-1,γT−−−√Id×d,0d×d,⋯,0d×dT-t]
and the corresponding kernel K((x1,t1),(x2,t2))=(1−γ+γTδt1t2)⟨x1,x2⟩
By writing (2) as the following, it is more apparent that we regularise around some common vector w0
minw01T∑t=1Tminw{1n∑i=1nℓ(yti,⟨w,xti⟩)+λγ||w−w0||2}+λ1−γ||w0||2 - More multitask kernels
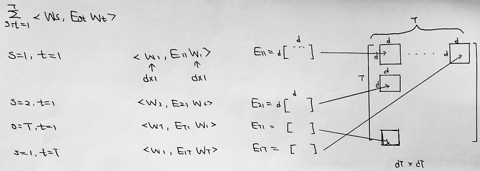
Structured sparsity
- general sparsity regulariser
||W||2,1:=∑j=1d∑t=1Tw2tj−−−−−−⎷
– sum of the l2 norm of the row of matrix
– encourages a matrix has only a few non-zero rows
– regression vectors are sparse, but the sparsity pattern is contained in a small cardinality
Clustered MTL
Further topics
Transferring to new tasks
- Having found a feature map
h
, to test it on the environment we
1) draw a taskμ∼E
2) draw a sample z∼μn
3) run the algorithm to obtain a(h)z=f^h,z∘h
4) measure the loss of a(h)z on a random pair (x,y)∼μ - The error associated with the algorithm
a(h)
is
Rn(h)=Eμ∼EEz∼μnE(x,y)∼μ[ℓ(a(h)z(x),y)] - The best value for a representation
h
given complete knowledge of the environment is then
minh∈HRn(h) Compare to the very best we can do:
R∗=minh∈HEμ∼E[minf∈FE(x,y)∼μℓ(f(h(x)),y)]The excess error associated with h is then
Rn(h)−R∗
Case of the variance regulariser
- Training
minw01T∑t=1Tminw{1n∑i=1nℓ(yti,⟨w,xti⟩+λγ||w−w0||2}+λ1−γ||w0||2 - Testing
minw1n∑i=1nℓ(yi,⟨w,xi⟩)+λγ||w−w0||2 - Error
Rn(w0)=Eμ∼EEz∼μnE(x,y)∼μℓ(y,⟨w0+wz,x)⟩ - Best we can do
R∗=minw0Eμ∼E[minwE(x,y)∼μℓ(y,⟨w0+w,x)⟩] - Excess error of w0 : Rn(w0)−R∗
Informal reasoning
The feature map B learned from the training tasks can be used to learn a new task more quickly (a kind of bias learning heuristic).
- Learn a new task by the method
minv{1n∑i=1nℓ(yt,⟨v,B∗xi⟩)+λ2||v||22} - Give more weight to important features. In particular, if some eigenvalues of G=B∗B are zero, the corresponding eigenvectors are discarded when learning a new task.
- In the case of diagonal matrices, some elements may be zero which results in a decreased number of parameters to learn.
- A statistical justification of an approach similar to this based on dictionary learning can be given.
Take home message
- MLT objective function
- regulariser
- link to kernel trick
- Multi-task learning, wikipedia
https://en.wikipedia.org/wiki/Multi-task_learning ↩















 7187
7187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









