



自DeepSeek R1发布以来一直在复现 DeepSeek R1。我的主要关注点是信息提取,特别是在零样本 文本到图提取 方面。这是一项任务,当给定一个实体和关系类型的列表时,我们从目标文本中提取实体列表及其之间的关系。
文本到图形输出的示例:
{
"entities": [
{
"id": 0,
"text": "Microsoft",
"type": "company"
},
{
"id": 1,
"text": "Satya Nadella",
"type": "person"
},
{
"id": 2,
"text": "Azure AI",
"type": "product",
}
],
"relations": [
{
"head": "Satya Nadella",
"tail": "Microsoft",
"type": "CEO of"
},
{
"head": "Microsoft",
"tail": "Azure AI",
"type": "developed"
}
]
}
这是一个相当复杂的任务,尤其对于小型生成语言模型而言。语言模型如果不限制输出的实体和关系类型,并允许模型自由地从文本中提取所有实体和关系,表现得相对较好。但是当我们通过实体和关系类型来约束输出时,对于语言模型来说,这确实是一场噩梦。从我的实验来看,很难以监督方式训练小型语言模型,以便条件性地根据输入的实体类型从文本中输出图表。强化学习的方法带来了希望,所以让我们详细讨论一下。
强化学习与监督学习的不同之处在于,我们并不明确告诉模型应该采取哪些行动来实现期望的里程碑。在我们的例子中,里程碑是一个考虑输入实体和关系类型的正确提取图,行动是模型生成的标记。我们可以直接告诉模型如何以 JSON 格式重现这个图,方法是最大化生成期望格式输出的概率。
许多人谈论思维的重要性,认为这是强化学习在LLMs领域带来的主要促进因素之一,许多论文也表明,思维链可以提高模型的性能,因此认为思维可以改善性能是非常合理的。然而,我认为强化学习的其他几个特性也可能产生显著影响。首先,让我们讨论一下 DeepSeek 引入的GRPO方法。以下是该团队使用的损失函数。

不深入数学,让我用高级术语讨论它的含义。基本上,我们生成一组候选解决方案来解决特定问题,并最大化基于其获得的奖励返回解决方案的概率。此外,通过 KL 收敛组件,我们尝试将与我们作为起点的原始模型的偏移最小化。
这样的训练算法可以带来有趣的特性,例如我们强制模型生成几个对于给定问题来说是预先定义的困难负样本的解,因为模型为这些解分配了相对较高的生成概率。因此,从某种意义上说,模型在训练过程中看到了正例和负例。
此外,正如 Andrej Karpathy 指出的,直接的标签示例无法迫使模型利用其知识推断一些新的涌现特性,例如“啊哈”时刻:
“模型永远无法通过模仿以 1 学习这一点,因为模型的认知和人工标注者的认知是不同的。人类永远不会知道如何正确标注这些类型的问题解决策略,以及它们应该是什么样子。这些策略必须在强化学习过程中发现,因为它们在经验和统计上对最终结果是有用的。”
RL 的另一个有趣特性是我们可以优化不同的目标并手动控制它们的影响,例如,如果我们发现我们的模型在关系提取上很困难,我们可以为正确提取的关系生成的示例分配更高的奖励,与其他特征相比。
所以,让我们讨论一下我们到底做了什么来训练一个使用 GRPO 进行文本到图形推断的模型,你可以看到一个展示它的视觉图表:
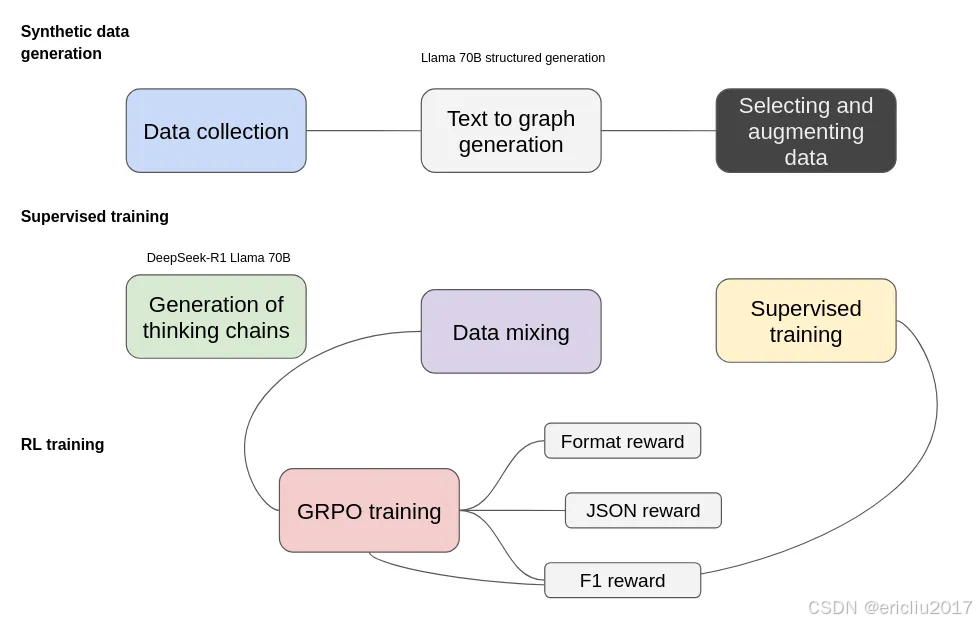
训练过程包括三个主要阶段:合成数据生成、监督训练和强化学习(RL)训练。这三个阶段在提升模型提取结构化信息的能力方面发挥着至关重要的作用。
- 合成数据生成
为了启动这个过程,我们从数据收集开始,在这里我们收集与目标领域相关的多种文本来源。接下来的文本转图生成步骤,由Llama 70B结构化生成驱动,将非结构化文本转换为基于图的表示。然而,这一步并不完美,因此,选择和增强数据变得至关重要,以过滤掉低质量的提取,并用更多样化的结构来丰富数据集。
此外,我们将生成的结构化预测 JSON 数据和文本输入到DeepSeek-R1 Llama 70B中,以生成能够解释提取过程的思维链。
我们在启用和禁用思维模式下进行实验,并发现小模型在发现一些有趣和重要的思维策略方面存在困难。
- 监督训练
在开始强化学习之前,考虑到我们使用的是小模型,需要额外的监督训练,以将模型返回的数据调整为正确的格式。我们仅使用了 1000 个示例用于这个目的。
- 使用 GRPO 的强化学习
单靠监督训练并不能完全解决问题,尤其是在模型输出需要针对预定义的实体和关系类型进行调整时。为了解决这个问题,我们采用了群体相对策略优化 (GRPO) 进行强化学习。
- 格式奖励确保输出遵循结构化格式,其中思考被封装在相应的标签中(在思考模式的情况下)。
- JSON 奖励 特别验证结构良好、机器可读的 JSON 表示,并且其结构符合期望的格式。
- F1 奖励 通过将提取的实体和关系与真实的图进行比较来评估其准确性。
我为奖励函数给出了不同的系数,优先考虑 F1 奖励,因为在我早期的实验中,模型在生成小的 JSON 输出时陷入了局部最小值。
强化学习阶段允许模型动态调整其生成策略,在必要时强调正确的关系提取。此外,GRPO使模型能够生成多个候选解决方案,并从正面和负面例子中学习,从而导致更强大的文本到图形提取。
下面您可以看到不同奖励随时间的变化,正如您所见,F1 奖励 不断增长,而 JSON 奖励 由于监督预训练而迅速饱和。
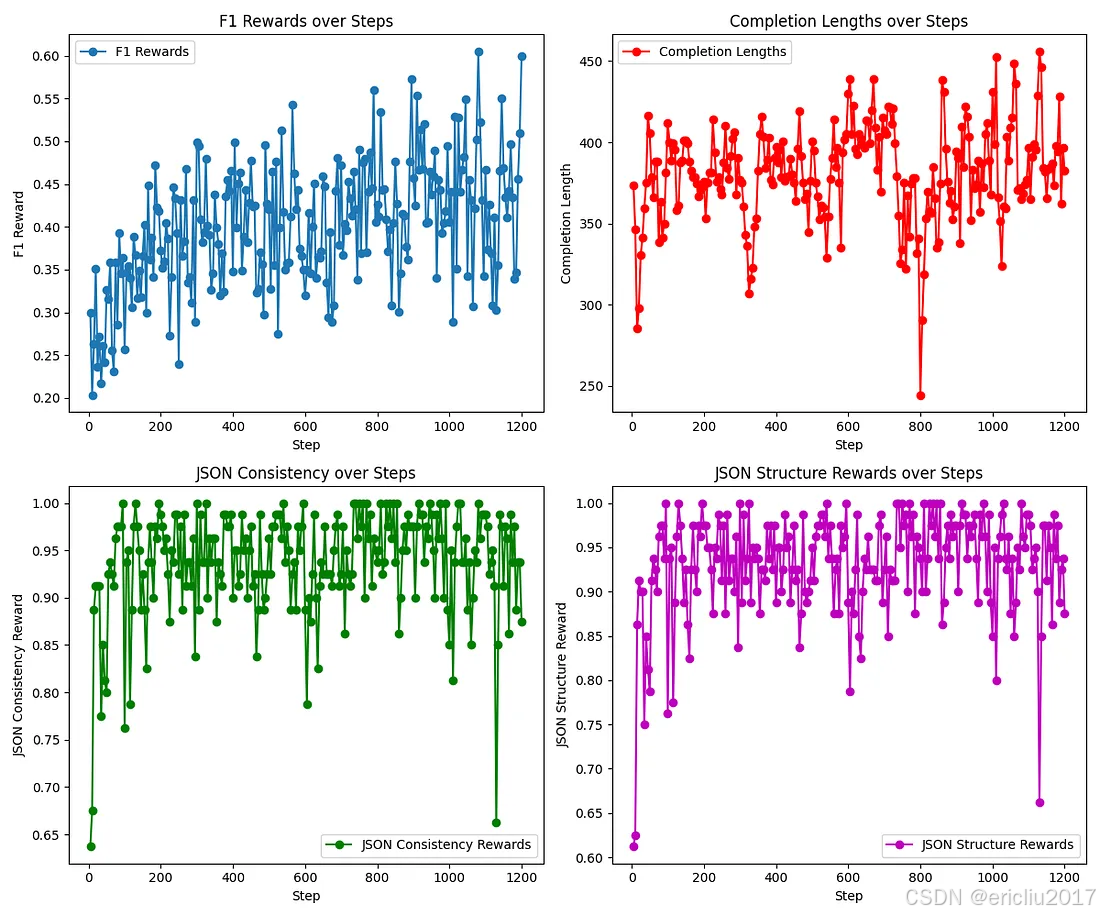
该模型在短时间的无监督学习后能够提高其性能,并且通过更多的强化学习训练步骤,其性能甚至可以更好。
我们计划进行更多实验,使用更大模型和更高质量的数据,请保持关注。与此同时,您可以尝试我们实验中的一个模型:
https://huggingface.co/Ihor/Text2Graph-R1-Qwen2.5-0.5b
要运行该模型,请参考下面的代码片段:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Ihor/Text2Graph-R1-Qwen2.5-0.5b"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
text = """Your text here..."""
prompt = "Analyze this text, identify the entities, and extract meaningful relationships as per given instructions:{}"
messages = [
{"role": "system", "content": (
"You are an assistant trained to process any text and extract named entities and relations from it. "
"Your task is to analyze user-provided text, identify all unique and contextually relevant entities, and infer meaningful relationships between them"
"Output the annotated data in JSON format, structured as follows:\n\n"
"""{"entities": [{"type": entity_type_0", "text": "entity_0", "id": 0}, "type": entity_type_1", "text": "entity_1", "id": 0}], "relations": [{"head": "entity_0", "tail": "entity_1", "type": "re_type_0"}]}"""
)},
{"role": "user", "content": prompt.format(text)}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
代码可以在这个 repo 找到,非常感谢 Hugging Face Open-R1 和 TRL 项目。
本研究项目中使用的数据集可以在这里找到。
随时分享您的想法和提问!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









