







深度理解DETR
关键点:
其实这篇文章的创新点从标题(End-to-End Object Detection with Transformers)就可以看出来,主要有以下三个重点:
- Object detection
- Transformers
- End-to-end
文章所做的工作,就是将transformers运用到了object detection领域,取代了现在的模型需要手工设计的工作(例如 非极大值抑制 和 anchor generation),并且取得了不错的结果。

如上图所示,文章的主要有两个关键的部分。
第一个是用transformer的encoder-decoder架构一次性生成N个box prediction。其中N是一个事先设定的、比远远大于image中object个数的一个整数;
第二个是设计了bipartite matching loss,基于预测的boxex和ground truth boxes的二分图匹配计算loss的大小,从而使得预测的box的位置和类别更接近于ground truth.
实现方法:
Transformer Encoder
DETR中,首先用CNN backbone处理 3HW 维的图像,得到 CHW 维的feature map(一般
C=2048,H=H0/32,W=W0/32 )。然后将backbone输出的feature map和position encoding相加,输入Transformer Encoder中处理,得到用于输入到Transformer Decoder的image embedding。
将CNN backbone输出的feature map转化为能够被Transformer Encoder处理的序列化数据的过程。主要有以下几个步骤:
- 维度压缩:将CNN backbone输出的 CHW 维的feature map先用 1*1 convolution处理,将channels数量从 C 压缩到 d ,即得到 d 维的新feature map;
- 转化为序列化数据:将空间的维度(高和宽)压缩为一个维度,即把上一步得到的 dHW 维的feature map通过reshape成 d*HW 维的feature map;
- 加上positoin encoding: 由于transformer模型是顺序无关的,而 d*HW 维feature map中 HW 维度显然与原图的位置有关,所以需要加上position encoding反映位置信息。生成的方法不难但讲起来比较啰嗦,大家如果感兴趣可以翻到文章末尾的附录看一下。
Transformer Decoder
transformer decoder主要有两个输入:
- image embedding (由Transformer Encoder输出) 与 position encoding 之和;
- object queries

Object queries有N个(其中 N 是一个事先设定的、比远远大于image中object个数的一个整数),输入Transformer Decoder后分别得到 N个decoder output embedding,经过FFN(后面会讲)处理后就得到了 N个预测的boxes和这些boxes的类别。
具体实现上,object queries是 N 个learnable embedding,训练刚开始时可以随机初始化。在训练过程中,因为需要生成不同的boxes,object queries会被迫使变得不同来反映位置信息,所以也可以称为leant positional encoding (注意和encoder中讲的position encoding区分,不是一个东西)。
此外,和原始的Transformer不同的是,DETR的Transformer Decoder是一次性处理全部的object queries,即一次性输出全部的predictions;而不像原始的Transformer是auto-regressive的,从左到右一个词一个词地输出。
LOSS
假设对于一张图来说,ground truth boxes的个数(即图中object的个数)为 m ,由于N 是一个事先设定好的远远大于image objects个数的整数。作者人为构造了一个新的物体类别 ∅ (表示没有物体)并加入image objects中,上面所说到的多出来的 N-m 个prediction embedding就会和 ∅ 类别配对。这样就可以将prediction boxes和image objects的配对看作两个等容量的集合的二分图匹配了。
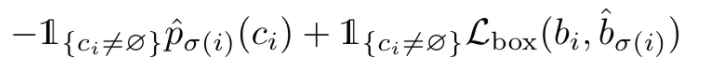
Ci 为第i 个image object的class标签, σ(i) 为与第 i 个object配对的prediction box的index;
l(ci≠Φ)是一个函数,当 ci≠Φ 时为1,否则为0;
左边公式表示Transformer预测的第 σ(i) 个prediction box类别为 ci 的概率
bi和b σ(i)为,第i 个image object的box和第 σ(i) 个prediction box的位置
它在二分匹配成功后又进行了一次损失计算,上面是用于匹配的损失,第二步是匹配成功后的匹配之间的损失
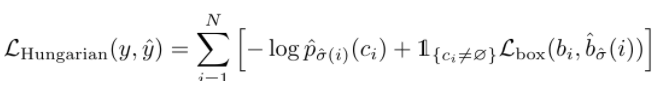

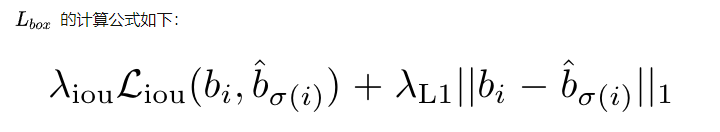
就是结合了中心距离和IoU,这不就是相当于c_loss???
POS(位置编码)

对照下图中Transformer的三个输入:image feature, positional encoding和object queries,分别对应上面代码中的h, pos和self.querypos。虽然代码说明中强调了为了可读性,将encoder中的positional encoding从fix变为learnt的了,但是显然这是针对与代码中的pos(也即self.row_embed和self.colembed)。所以参照代码中self.query_pos的初始化操作nn.Parameter(torch.rand(100, hidden_dim)),可以推断object queries是随机初始化,并在Training过程中学到的embedding。

参考链接
https://zhuanlan.zhihu.com/p/267156624















 590
590











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









