







为什么要有DETR
总所周知,传统的目标检测算法非常依赖于anchor和nms等手工设计操作,非常费时费力,自然而然的就产生了取消这些操作的想法。但是我们首先需要思考的是,为什么我们需要anchor和nms?
因为我们是没有指定anchor去具体预测哪一个目标的,而且nms操作是建立在纯粹的边界框的距离上的,它完全没有利用到图像的信息,只是根据两个边界框的IoU去做判断,这样造成了两个问题。
一是非常费事,我之前写过一篇介绍NMS算法的博客,具体内容大家可以去看看,这里仅做简要的介绍,NMS的操作首先需要根据置信度的阈值过滤掉一批边界框,形成一个边界框集合B,然后从中挑选出置信度最高的边界框b,然后B集合剩下的边界框挨个去和它做IoU的计算,这个IoU值一旦大于某个阈值,我们就把这个边界框从B集合中删除,这样计算的复杂度至少就是o(n)。
二是对于密度预测,nms的这种操作就很容易把目标给漏掉。我举个例子,

这是斯坦福团队ICCV2015的一篇论文,这篇论文也直接启发了DETR的工作,
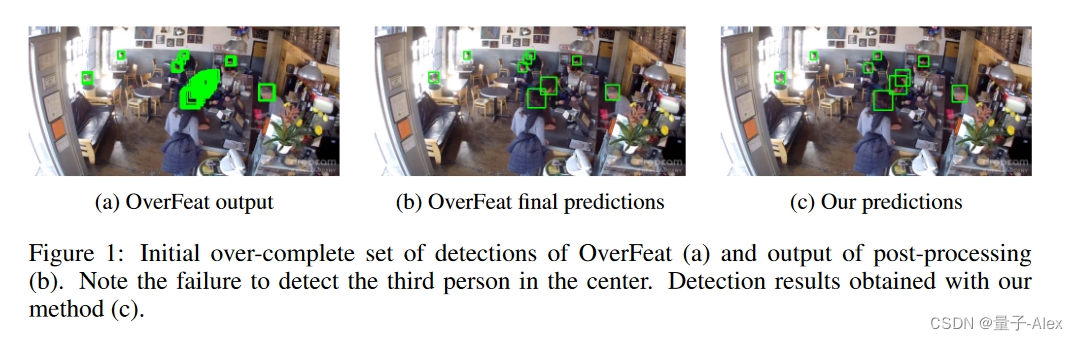
可见在B图中,挨得很近的人被忽略了,这是为什么呢?正是因为我们运用了NMS操作,它基于Iou把相近的边界框给过滤掉了。使用NMS就一定会有正样本被过滤。
说完了NMS操作的问题,我们再来说anchor的问题,关于为什么要使用anchor,我计划用一个博客专门来讲这个问题,这里也只是简要讲一下anchor的问题。
逻辑是这样的:为什么需要nms操作?——因为对同一个目标有冗余的检测框。——为什么会有冗余的检测块?——因为我们运用了anchor 那问题来了,为什么使用anchor就会产生冗余的检测框呢?
原因很简单,因为anchor之间是没有信息交互的。A anchor去预测了一个目标,其他的anchor是不知道的,他们也会去预测这个目标,只要这个目标落在anchor所在的区域内,这就是产生这个问题的根源。
那么要想解决anchor和nms的问题,解决方案就呼之欲出了,我们需要让anchor之间有信息交互,如果一个anchor预测到了目标,就必须让其他的anchor知道,那么什么方法什么机制能够实现信息交互呢?那就是循环神经网络了。这也是这篇论文的方法 CNN + LSTM
Transformer在2017年被提出来后,其全局注意力机制在NLP领域得到了广泛的应用与成功,自然而然地就会被想到运用于CV领域。
DETR就是第一个把Transformer应用于目标检测领域的工作。

论文的链接:
DETR论文
官方代码的链接
官方DETR代码
我讲解的DETR代码链接:
我讲解的DETR代码
DETR的算法思想、网络结构与具体实现
1.算法思想
目标是做在之前介绍的那篇CNN+LSTM的基础上实现并行的预测。
核心思想,把目标检测问题转换为集合的预测问题。把预测框集合与真实目标集合之间做完全的二分类匹配,也就是左右两边要一对一。
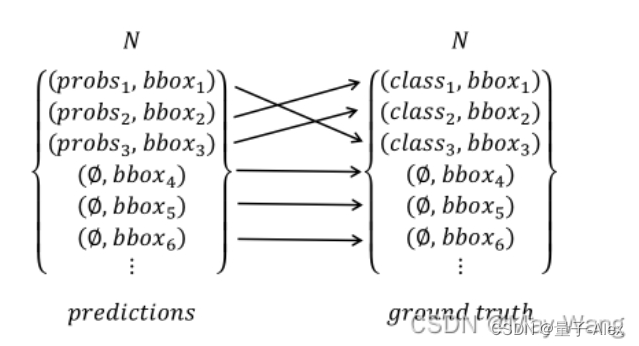
现在假设有两个集合,左边的集合是模型预测到的N个元素,N是指定的超参数,一般指定为100,因为一般的数据集比如COCO都不会有超过100种目标。如果我们预测出现的标签数量不到N怎么办?没关系,就补充ϕ,表现没有检测到目标。集合中每个元素里面包括边界框的坐标和目标的类别信息,右边的集合就是ground truth,同样,不够N怎么办,就补充ϕ,表示是背景。这样把左右两个集合做一对一的匹配,按照哦我们设定的损失函数最小的匹配方法,就实现了把预测框与真实目标的一对一匹配,这就完全避免了冗余的检测框的问题。
根据上面的算法核心思想,
那么接下来有几个问题:
①如何得到检测框,从哪里来
②如何避免检测框之间的重复
③如何在预测的检测框集合与ground truth集合之间实现最佳的一对一匹配
DETR的解决方案是这样的
对于第一个问题和第二个问题,实际上是一个问题。
答案就是利用transformer的Encoder-decoder,首先还是利用一个CNN的backbone去提取特征图,这里要插一点,为什么还是要使用CNN的主干网络提取特征图,因为在这篇论文发表的时候(2020年),当时还没有Swin Transformer这样的可以针对不同分辨率图像输入的transformer backbone,这里还要补充一点,我们输入transformer的都是一个个token,在NLP任务里面,这一个个token可以是单词、字母,那迁移到CV领域,这些token是什么呢?可以是像素、也可以是patch(图像块),但是问题就来了,如果大家对transformer的self-attention计算过程了解的话就可以知道,一般的计算量是token的平方,也就是每个query需要和包括它自己在内的所有Key相乘,因此,如果我们把一个像素作为token,对于一个100*100的原图,我们就有10000个token,那就需要计算10000的平方次,这个计算量是吃不消的,因此用CNN的主干网络的主要目的除了提取特征以外,很重要的一点就是缩减图像的尺寸,变成一个个patch。
提取完特征图后,把特征图展开,成为一个token序列,每一个token都是一个个特征图的patch,这样输入到encoder中使用self-attention进行全局推理。这样的token之间就进行了信息交互
然后,初始化object query,这个object query的数量也是人为设定的,我们要预测多少个目标就设置多少个object query,object query的初始化就是0+positional encoder
初始化的object query输入到transformer的decoder,与encoder feature 输出的key进行cross-attention,找到带有全局信息的与物体相关的区域,同时Self-attention 则在不同的 query 之间进行交互,实现类似 NMS 的效果。
最后的 prediction heads 基于每个 query 在 decoder 中提取到的特征,预测出物体的 bounding box 的位置和类别。
至于第三个问题,作者用了匈牙利算法做最优二部图匹配,这一点会在损失函数这一部分进行深入介绍

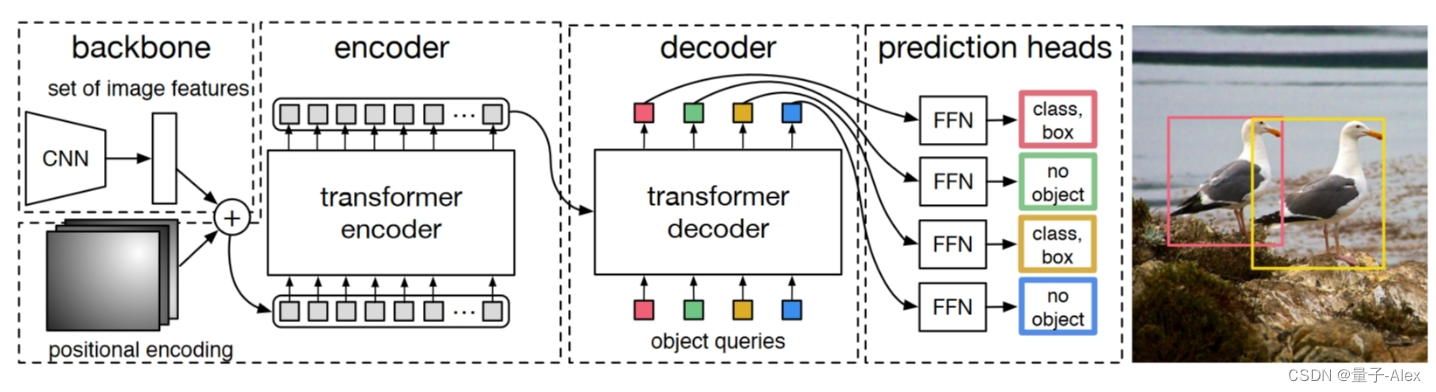
DETR把目标检测视为一个直接的集合预测问题,简化了检测管道,有效地消除了对anchor和nms这样手工设计组件需求。
2.网络结构
DETR的网络结构如上图所示:基本可以分为四个部分
①CNN Backbone
②encoder
③decoder
④FFN head
CNN Backbone
Backbone 的输出通道为 2048,图像高和宽都变为了 1/32
Transformer Encoder
在得到Feature Map之后,DETR首先通过一个 卷积将其通道数调整为更小的d,得到一个大小为 dHW
的新的Feature Map。DETR的下一步则是将其转换为序列数据,这一步是通过reshape操作完成的,转换之后的数据维度是 d*(HW)
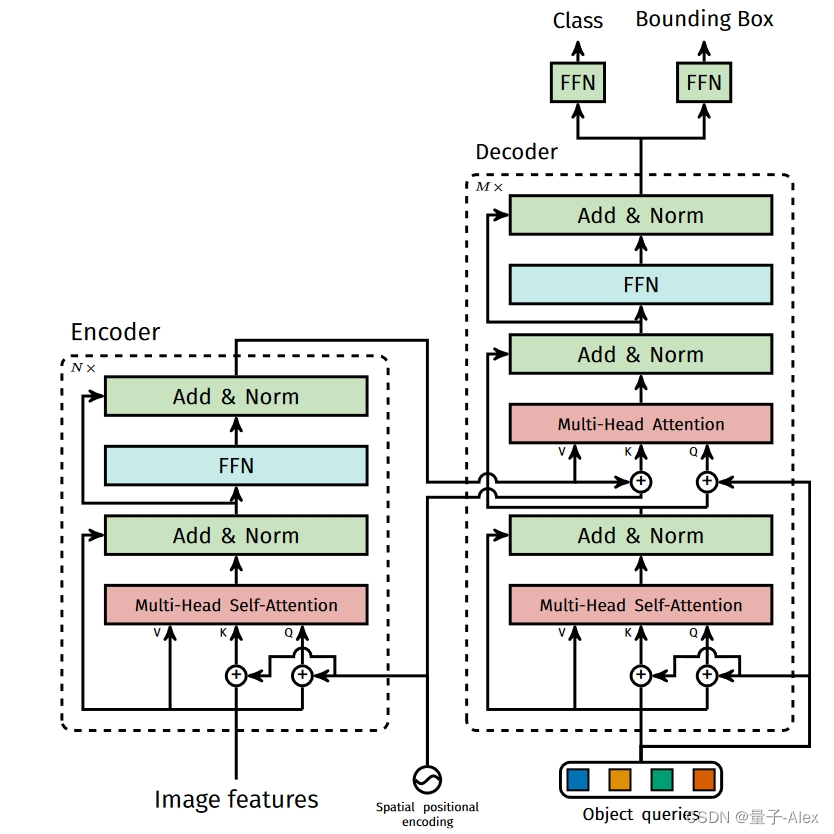
。因为Transformer是与输入数据的顺序无关的,因此它需要加上位置编码加入位置信息。这一部分会作为编码器的输入。DETR的编码器的Transformer使用的是多头自注意力模型加上一个MLP。
经过 Backbone 后,将输出特征图 reshape 为 C × H W 因为 C = 2048 是每个 token 的维度,还是比较大,所以先经过一个 1 × 1 的卷积进行降维,然后再输入 Transformer Encoder 会更好。此时自注意力机制在特征图上进行全局分析,因为最后一个特征图对于大物体比较友好,那么在上面进行 Self-Attention 会便于网络更好的提取不同位置不同大物体之间的相互关系的联系,比如有桌子的地方可能有杯子,有草坪的地方有树,有一个鸟的地方可能还有一个鸟等等。所以 DETR 在大目标上效果比 Faster RCNN 好就比较容易理解到了。然后位置编码是被每一个 Multi-Head Self-Attention 前都加入了的,这个就比较狠了。为了体现图像在 x 和 y 维度上的信息,作者的代码里分别计算了两个维度的 Positional Encoding,然后 Cat 到一起。整个 Transformer Encoder 和之前的没什么不同。
Transformer Decoder
Transformer Decoder 也有几个地方需要着重强调。首先就是如何考虑同时进行一个集合预测?之前讲分类的时候都是给一个 class token,因为只进行一类预测。那么现在同时进行不知道多少类怎么办呢?因为目标预测框和输入 token 是一一对应的,所以最简单的做法就是给超多的查询 token,超过图像中会出现的目标的个数(在过去也是先生成 2000 个框再说)。所以在 DETR 中,作者选择了固定的 N = 100 个 token 作为输入,只能最多同时检测 100 个物体。据闻,这种操作可能跟 COCO 评测的时候取 top 100 的框有关。输入 100 个 decoder query slots (Object Query),并行解码N个object,对应的 Transformer decoder 也就会输出 100 个经过注意力和映射之后的 token,然后将它们同时喂给一个 FFN 就能得到 100 个框的位置和类别分数(因为是多分类,所以类别个数是 K + 1,1 指的是背景类别)。
固定预测个数更为简单,定长的输出有利于显存对齐,但是 N = 100 会不会冗杂呢?作者的实验表明,当图像内目标个数在 50 左右的时候,网络就已经区域饱和了,之后就会出现目标丢失。当图像内目标在一百个左右时,其实网络只能检测出来三四十个,这比图像中只有 50 个实例被检测到的情况还要少。作者认为出现这样反常的原因还是因为检测结果与训练分布相差甚远,是训练集中没有那么多多目标图片所造成的。
FFN
最后的 FFN 是由具有 ReLU 激活函数且具有隐藏层的 3 层线性层计算的,或者说就是 1 × 1 1 \times 11×1 卷积。FFN 预测框标准化中心坐标,高度和宽度,然后使用 softmax 函数激活获得预测类标签。
3.损失函数
通过上面对DETR的模型的分析我们知道对于一张图片DETR会输出 N个不同的bounding box,那么我们如何评估这 N个bounding box的效果的好坏呢?在DETR中的策略是对这 N个bounding box以及 N个ground truth进行最优二部图匹配,并根据匹配的结果计算loss来对模型进行优化。
上面提到了计算loss需要生成 N个ground truth,但是一张图片的待检测目标的个数往往是不足 N个的。为了解决这个问题,DETR构造了一个新的类ϕ ,它表示没有目标物体的背景类。通过调整 ϕ中的样本的大小我们可以将ground truth的样本数可控制在 N个,这样我们便得到了两个等容量的集合。
有了这 N 个ground truth,那么我们只要定义好ground truth和bounding box的匹配代价,便可以使用匈牙利匹配算法来得到ground truth和bounding box的最优二部图匹配方案了。
用 y y y来表示对象的真实集,而用 y ^ = { y ^ i } i = 1 N \hat{y} = \{\hat{y}_i\}^N_{i=1} y^={y^i}i=1N来表示N个预测集。假设N大于图像中对象的数量,将y也视为一组大小为N的集合,填充有∅(无对象)。找到这两个集合之间的二分匹配,
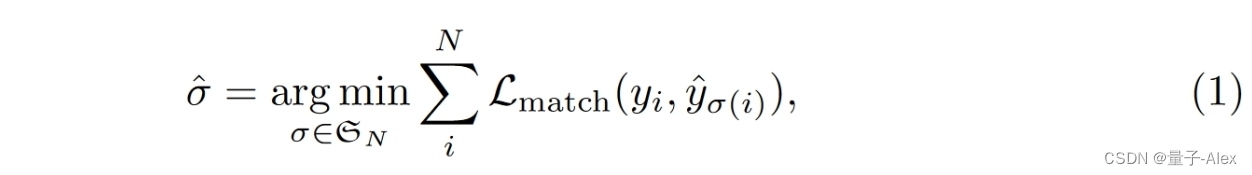
其中 L m a t c h ( y i , y ^ σ ( i ) ) \mathcal{L}_{match}(y_i, \hat{y}_{σ(i)}) Lmatch(yi,y^σ(i))是ground truth y i y_i yi和具有指示函数 σ ( i ) σ(i) σ(i)的预测之间的成对匹配代价
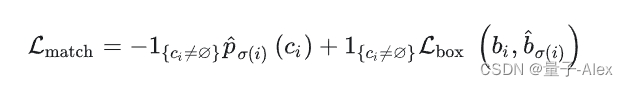
将类 c i c_i ci的概率定义为 p ^ σ ( i ) ( c i ) \hat{p}_{σ(i)}(ci) p^σ(i)(ci),预测框定义为 b ^ σ ( i ) \hat{b}_{σ(i)} b^σ(i)。根据这些符号,将 L m a t c h ( y i , y ^ σ ( i ) ) \mathcal{L}_{match}(y_i, \hat{y}_{σ(i)}) Lmatch(yi,y^σ(i))定义为 − 1 c i ≠ ∅ p ^ σ ( i ) ( c i ) + 1 c i ≠ ∅ L b o x ( b i , ˆ b ^ σ ( i ) ) −\mathbb{1}_{{c_i\neq∅}} \hat{p}_{σ(i)}(ci) + \mathbb{1}_{{c_i\neq∅}}\mathcal{L}_{box}(bi, ˆ\hat{b}_{σ(i)}) −1ci=∅p^σ(i)(ci)+1ci=∅Lbox(bi,ˆb^σ(i))。
匈牙利算法的损失函数分为类别损失和坐标回归损失两部分
−
1
c
i
≠
∅
p
^
σ
(
i
)
(
c
i
)
−\mathbb{1}_{{c_i\neq∅}} \hat{p}_{σ(i)}(ci)
−1ci=∅p^σ(i)(ci)这是类别的损失,前面的是一个布尔函数,也就是当类别不为背景的时候为1,否则为0
损失函数肯定是希望越小越好,只有预测是目标而不是背景才有
p
^
σ
(
i
)
(
c
i
)
\hat{p}_{σ(i)}(ci)
p^σ(i)(ci),否则为0,因此在千米加上负号,后面是边界框的回归损失,肯定是希望预测的框与真实目标的越接近越好。
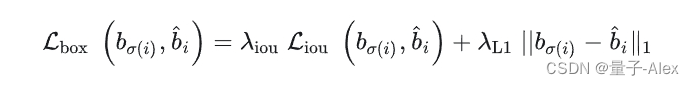
其中
λ
i
o
u
,
λ
L
1
∈
R
λ_{iou}, λ_{L1} ∈ \mathbb{R}
λiou,λL1∈R是超参数。使用了L1损失和广义IoU损失
L
i
o
u
(
⋅
,
⋅
)
L_{iou}(·, ·)
Liou(⋅,⋅)的线性组合
当我们通过上面的策略得到ground truth和预测bounding box的最优二部图匹配后,便可以根据匹配的结果计算损失函数了。DETR的损失函数和匹配代价非常类似,不同的是它的类别预测使用的是对数似然,
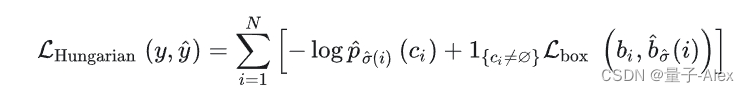
它们另外一个不同是bool函数作用的位置不同,在 前者中背景目标不参与匹配代价的计算,
后 则也要计算背景目标的分类损失。
















 205
205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











