







第一步:打开网址,进入开发者模式,选中 Network,选择 Img 然后刷新页面,静静等待页面加载
等待页面加载完成,你可以看到这边有很多图片的资源

随便点开一个图片选择 Headers 可以看到 Request URL 也就是这张图片的资源路径
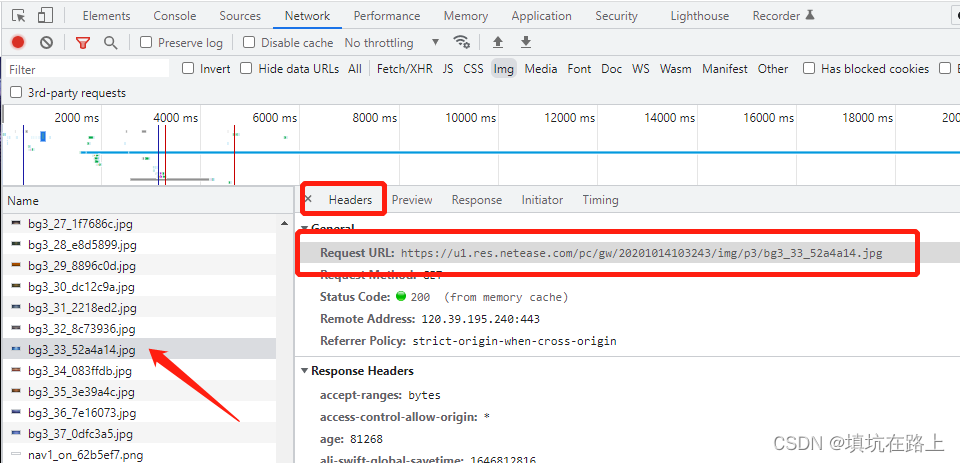
到这里我们就可以开始写第一个方法了,根据图片的资源路径下载图片到本地
# 这是一个示例 Python 脚本。
# 按 Shift+F10 执行或将其替换为您的代码。
# 按 双击 Shift 在所有地方搜索类、文件、工具窗口、操作和设置。
import os
import urllib.request
from pathlib import Path
# 根据图片的资源路径下载图片到本地
def download_by_url(url):
# 获取当前文件名作为保存文件夹
path = os.path.basename(__file__).split('.')[0]
# 获取 url 中文件名称和扩展名作为保存文件名
name = url.split('/')[-1]
# 获取文件扩展名作为文件保存分类
file_type = name.split('.')[1]
path += '/' + file_type
# 判断文件保存路径是否存在,不存在则创建
dirs = Path(path)
if not dirs.is_dir():
os.makedirs(path)
# 根据文件路径获取文件,如果文件不存在则创建
# wb: 以二进制格式打开一个文件只用于写入
file_path = path + '/' + name
file = open(file_path, 'wb')
try:
# 通过 url 获取资源
request = urllib.request.urlopen(url)
# 将图片二进制数据写入文件
file.write(request.read())
print('文件保存成功!')
except IOError:
print('获取资源失败!')
# 关闭文件
file.close()
# 按间距中的绿色按钮以运行脚本。
if __name__ == '__main__':
download_by_url("https://u1.res.netease.com/pc/gw/20201014103243/img/p3/bg3_33_52a4a14.jpg")
# 访问 https://www.jetbrains.com/help/pycharm/ 获取 PyCharm 帮助
运行程序,图片保存成功
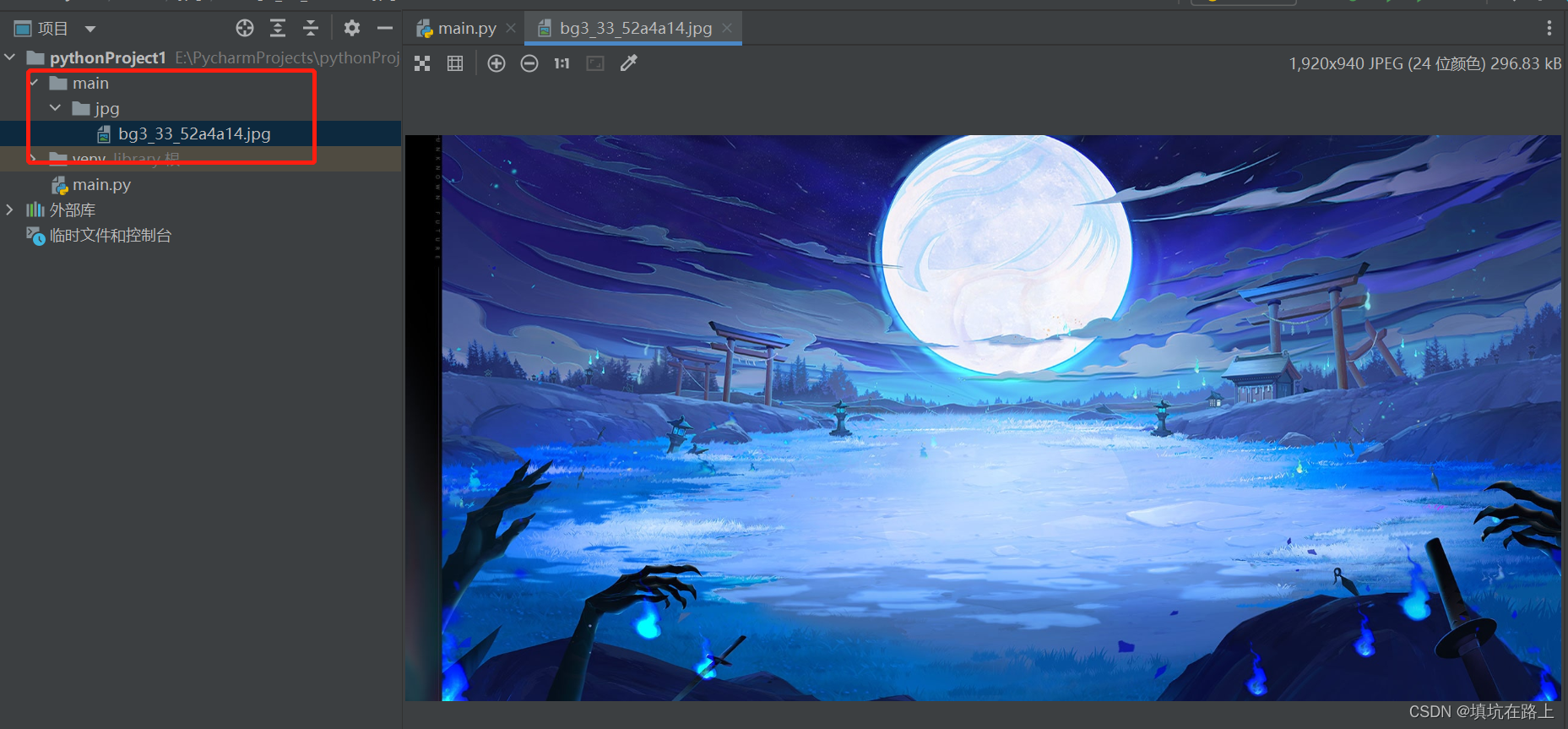
现在我们只要有资源路径就可以下载资源,所以接下来我们需要获取网站内的所有资源路径
第二步:按 ctrl + f 打开控制台搜索,把我们之前得到的 url 粘贴进去,点击刷新,我们可以看到出来了一串数据
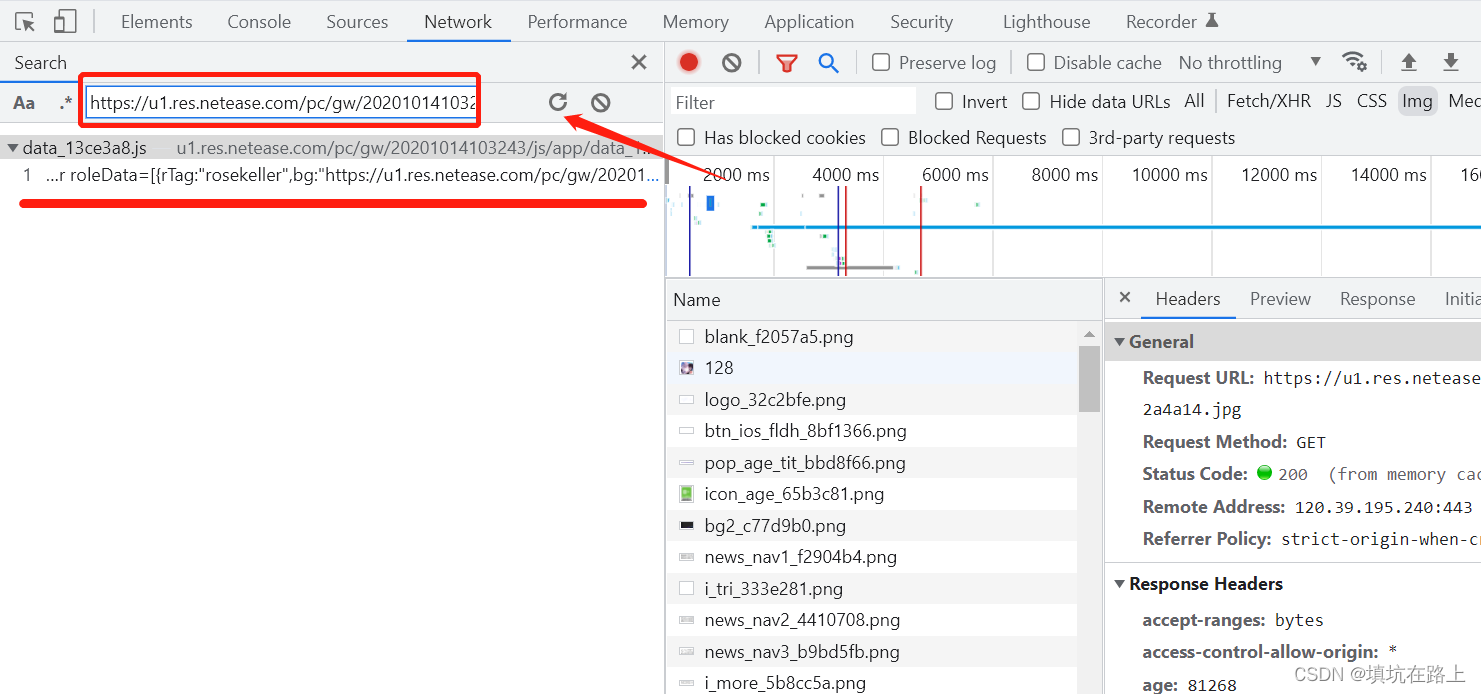
点开数据,我们可以看到我们需要的 url 在一个 js 的 Response 当中,打开 Headers 我们可以看到这个 js 文件的资源路径,通过 js 的资源路径我们就可以获取到 js 里面的数据
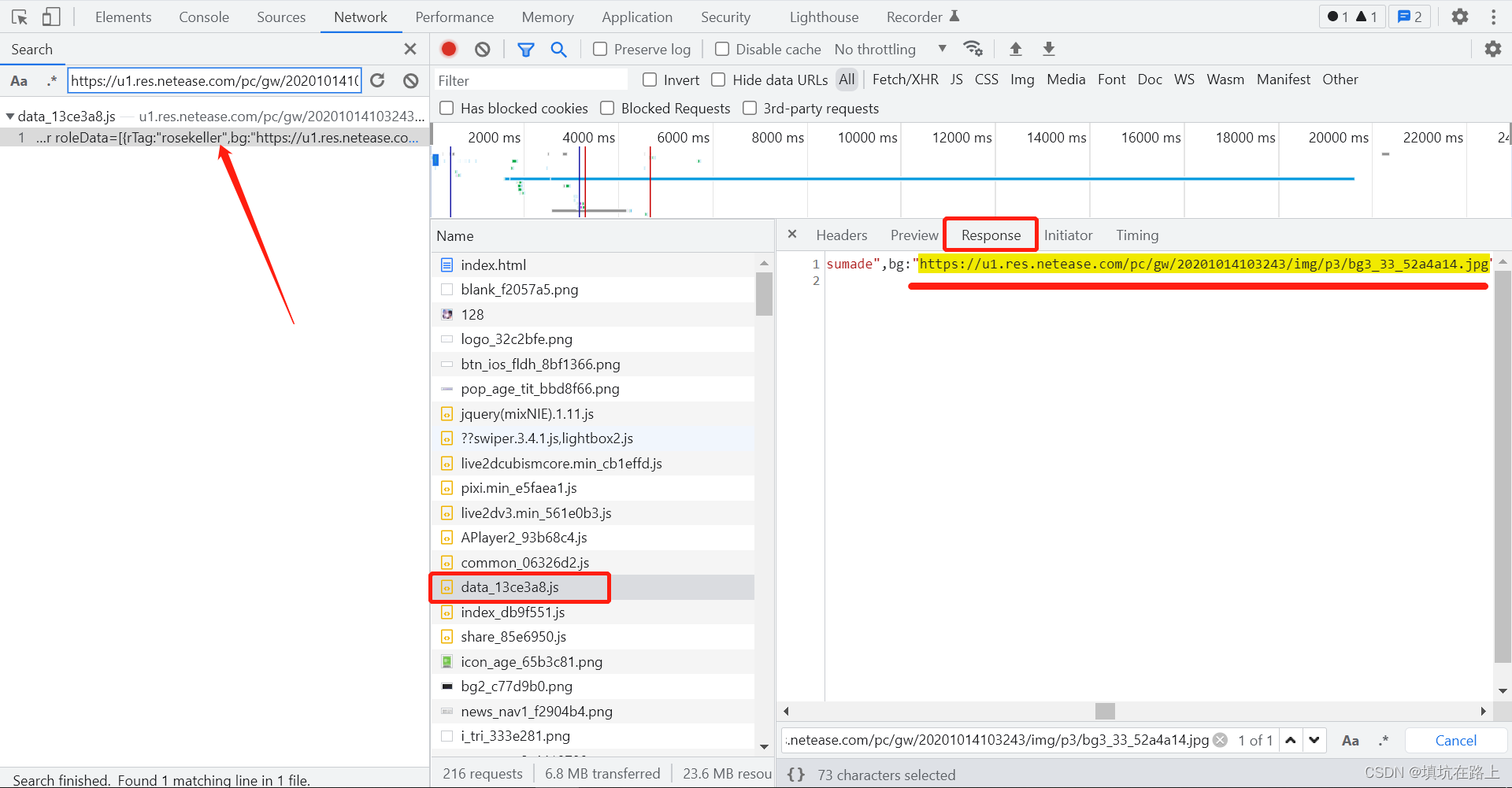
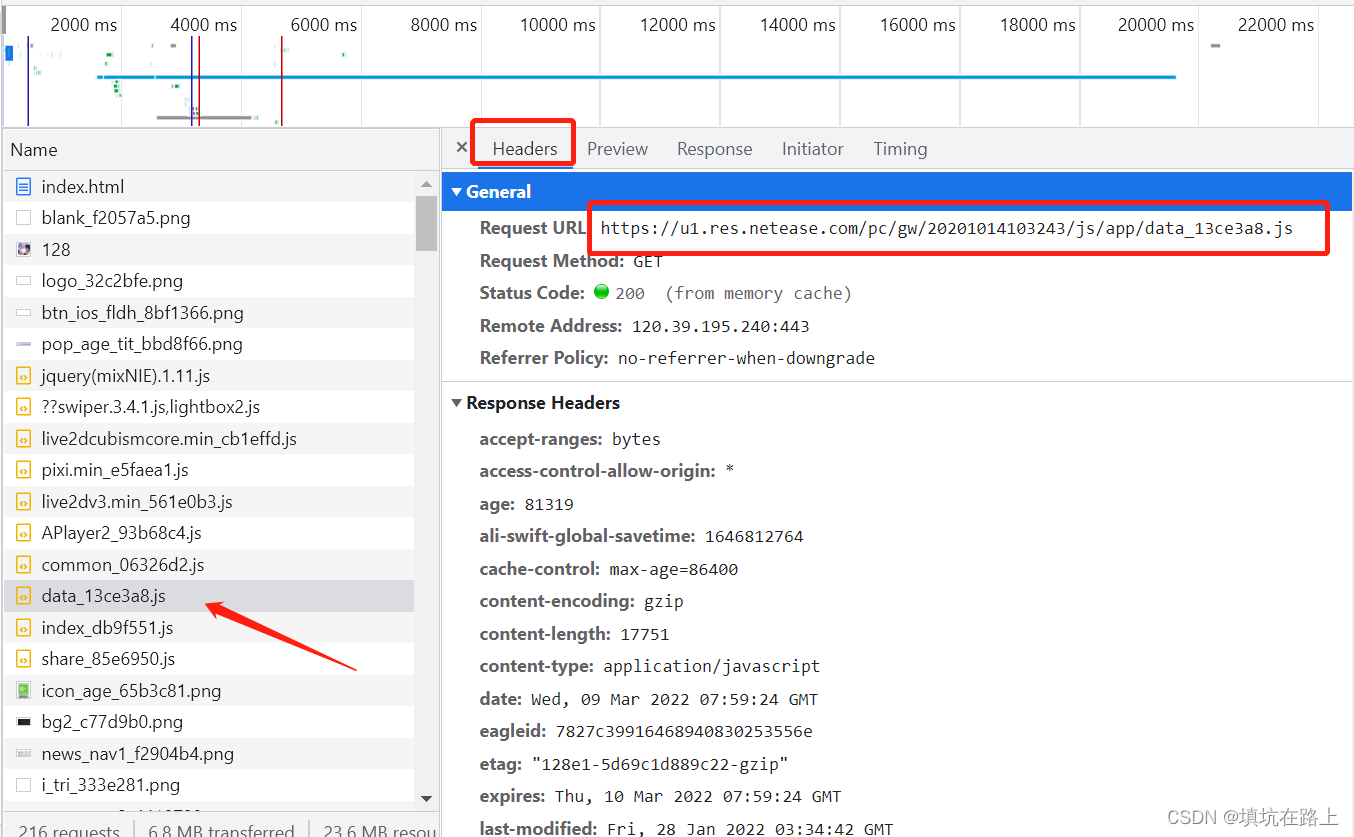
复制 Response 底下的数据到网上随便找个 json 解析工具格式化一下,可以看到里面有一大堆的 jpg 和 png,所以我们需要把这个大字符串里面的 jpg 和 png 的 url 全部给他拿出来
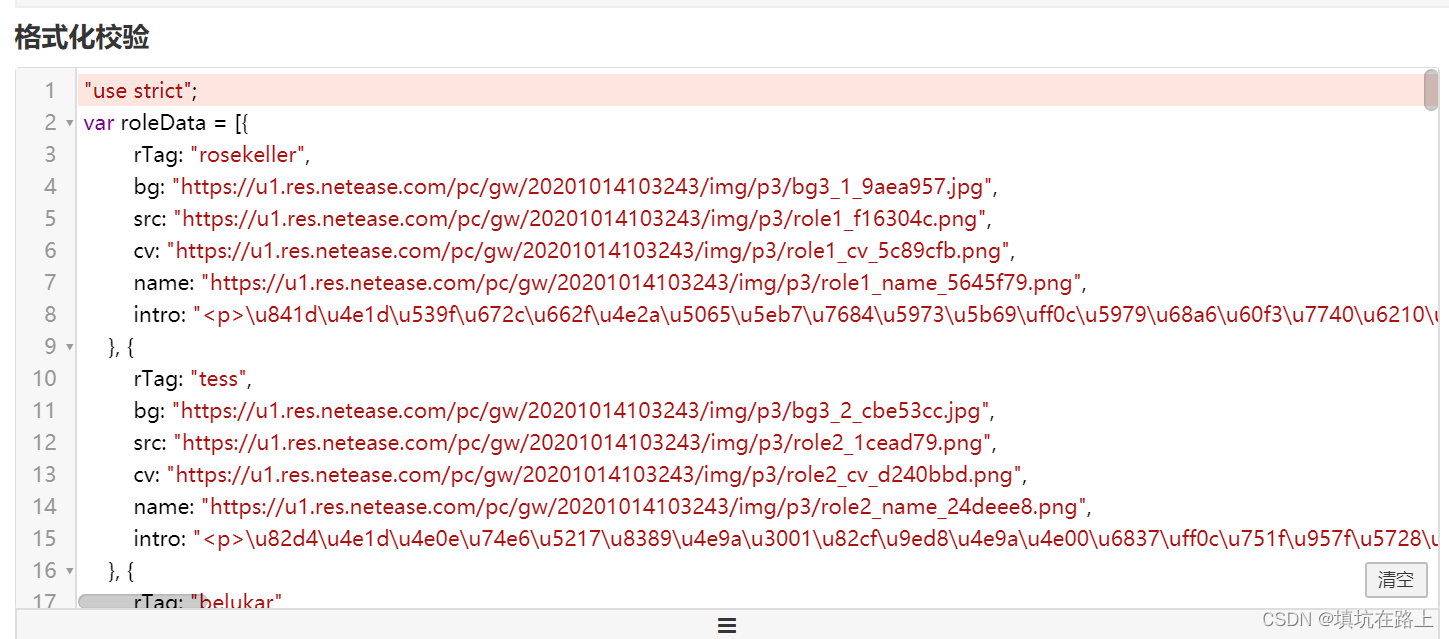
仔细观察这边的数据并不是 json 格式的,而且里面有多个对象,转成 json 格式的话不太方便,所以我打算把里面的 jpg 和 png 的 url 单独切割出来
这个使用到正则表达式
"http.*?"
表示获取 "http 开头 " 结尾的字符串
.*? 只匹配符合条件的最少字符
到了这里我们就可以写我们的第二个方法了,通过 js 的资源路径获取 js 里面的所有 jpg 和 png 路径
# 这是一个示例 Python 脚本。
# 按 Shift+F10 执行或将其替换为您的代码。
# 按 双击 Shift 在所有地方搜索类、文件、工具窗口、操作和设置。
import os
import urllib.request
from pathlib import Path
import re
import requests
# 通过 js 的资源路径获取 js 里面的所有 jpg 和 png 路径
def find_url(url):
file_url_list = []
try:
js_data = requests.get(url)
except IOError:
print('获取JS数据失败!')
return file_url_list
# 拿到所以 http 开头的 url
http_url_list = re.findall('"http.*?"', js_data.text)
for http_url in http_url_list:
# 找到 jpg 和 png 扩展名的 url
if http_url.find('.jpg') != -1or http_url.find('.png') != -1:
# http_url 字符串两头中包含了 " 号,需要截取掉
file_url_list.append(http_url[1:-1])
print('Js 内 URL 获取完毕...')
return file_url_list
# 根据图片的资源路径下载图片到本地
def download_by_url(url):
# 获取当前文件名作为保存文件夹
path = os.path.basename(__file__).split('.')[0]
# 获取 url 中文件名称和扩展名作为保存文件名
name = url.split('/')[-1]
# 获取文件扩展名作为文件保存分类
file_type = name.split('.')[1]
path += '/' + file_type
# 判断文件保存路径是否存在,不存在则创建
dirs = Path(path)
if not dirs.is_dir():
os.makedirs(path)
# 根据文件路径获取文件,如果文件不存在则创建
# wb: 以二进制格式打开一个文件只用于写入
file_path = path + '/' + name
file = open(file_path, 'wb')
try:
# 通过 url 获取资源
request = urllib.request.urlopen(url)
# 将图片二进制数据写入文件
file.write(request.read())
except IOError:
print('获取资源失败!')
# 关闭文件
file.close()
# 按间距中的绿色按钮以运行脚本。
if __name__ == '__main__':
for url in find_url("https://u1.res.netease.com/pc/gw/20201014103243/js/app/data_13ce3a8.js"):
download_by_url(url)
# 访问 https://www.jetbrains.com/help/pycharm/ 获取 PyCharm 帮助
程序运行,效果如下
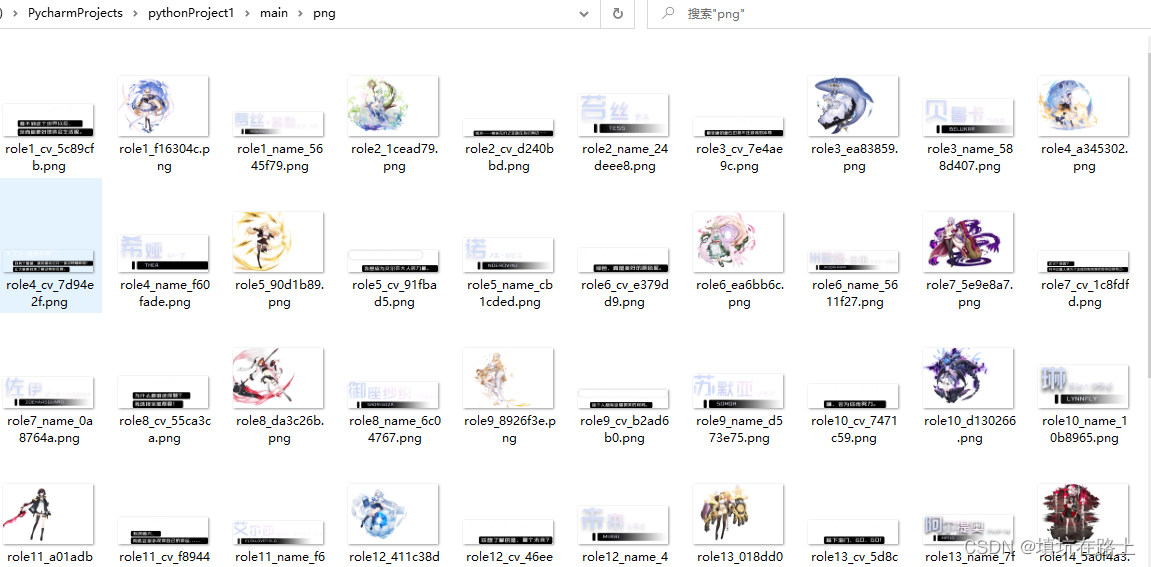
到这里就可以通过 JS 资源下载图片了,接下来开始第三步,获取网页内全部的JS
第三步:有了第二步经验,我们很快就能找到 JS 的 url 地址来源
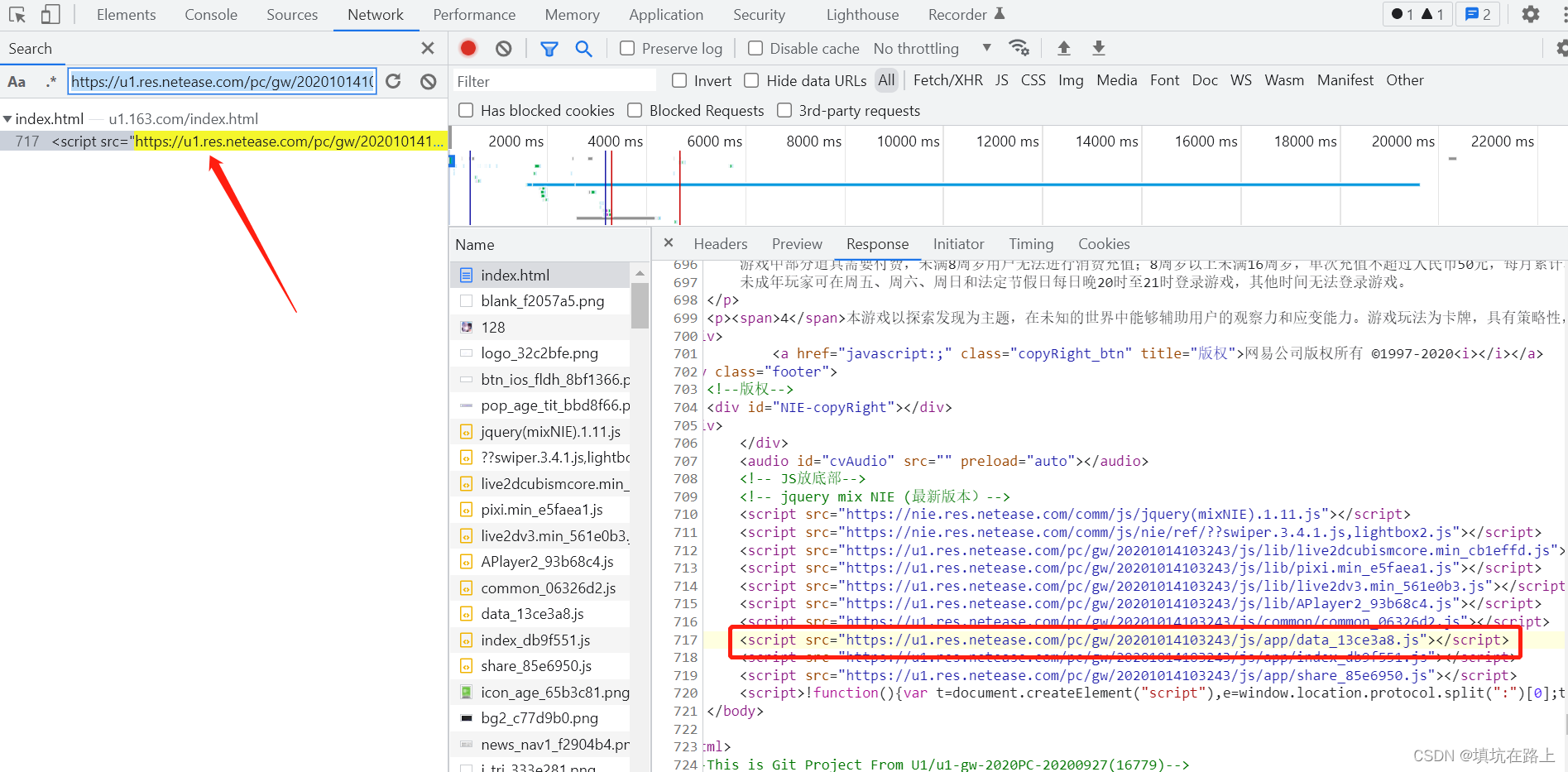
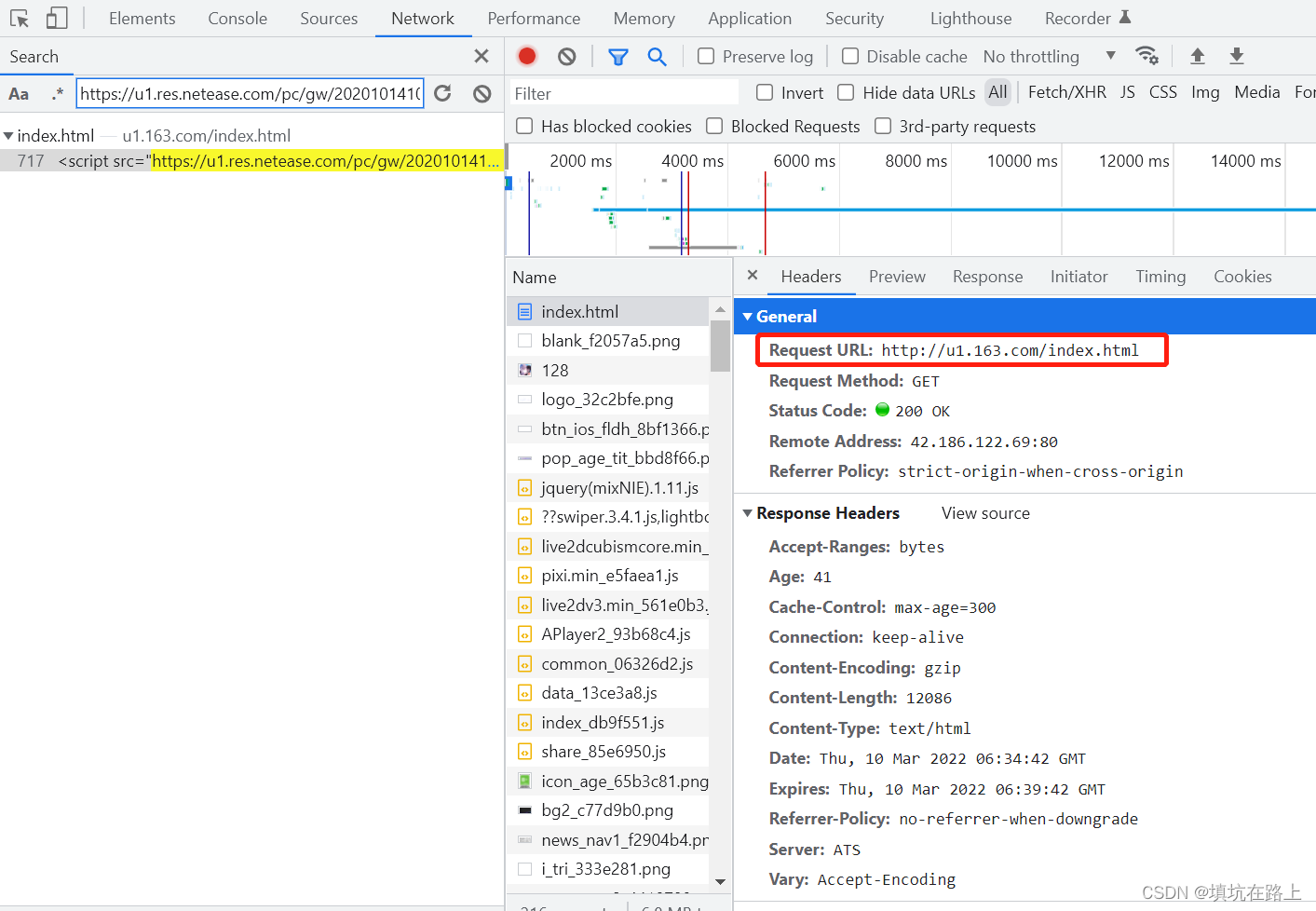
由此我们知道,通过网站地址获取 js 资源的方式和第二步,通过 js 获取图片资源的方式是一样的,所以我把第二步的方法进行了修改
# 这是一个示例 Python 脚本。
# 按 Shift+F10 执行或将其替换为您的代码。
# 按 双击 Shift 在所有地方搜索类、文件、工具窗口、操作和设置。
import os
import urllib.request
from pathlib import Path
import re
import requests
# 通过资源路径获取里面的所有URL路径
def find_url(url, file_type):
file_url_list = []
try:
js_data = requests.get(url)
except IOError:
print('获取JS数据失败!')
return file_url_list
# 拿到所以 http 开头的 url
http_url_list = re.findall('"http.*?"', js_data.text)
for http_url in http_url_list:
# 找到 jpg 和 png 扩展名的 url
if http_url.find('.' + file_type) != -1:
# http_url 字符串两头中包含了 " 号,需要截取掉
file_url_list.append(http_url[1:-1])
print('URL 获取完毕...')
return file_url_list
# 根据图片的资源路径下载图片到本地
def download_by_url(url):
# 获取当前文件名作为保存文件夹
path = os.path.basename(__file__).split('.')[0]
# 获取 url 中文件名称和扩展名作为保存文件名
name = url.split('/')[-1]
# 获取文件扩展名作为文件保存分类
file_type = name.split('.')[1]
path += '/' + file_type
# 判断文件保存路径是否存在,不存在则创建
dirs = Path(path)
if not dirs.is_dir():
os.makedirs(path)
# 根据文件路径获取文件,如果文件不存在则创建
# wb: 以二进制格式打开一个文件只用于写入
file_path = path + '/' + name
file = open(file_path, 'wb')
try:
# 通过 url 获取资源
request = urllib.request.urlopen(url)
# 将图片二进制数据写入文件
file.write(request.read())
except IOError:
print('获取资源失败!')
# 关闭文件
file.close()
# 按间距中的绿色按钮以运行脚本。
if __name__ == '__main__':
for js in find_url("http://u1.163.com/index.html", 'js'):
for jpg in find_url(js, 'jpg'):
download_by_url(jpg)
for png in find_url(js, 'png'):
download_by_url(png)
# 访问 https://www.jetbrains.com/help/pycharm/ 获取 PyCharm 帮助
至此,全篇结束(本文仅作技术研究,不涉及任何商业用途)














 572
572











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









