







文章目录
一:本地测试
1.需求
分析需求:给定一个hello.txt文本,如下:
atguigu atguigu
ss ss
cls cls
jiao
banzhang
xue
hadoop
期望输出数据:
atguigu 2
banzhang 1
cls 2
hadoop 1
jiao 1
ss 2
xue 1
2.环境
jdk8、apache-maven-3.6.3、IDEA2021.3
3.创建工程,及前期配置
1.创建工程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LhMZWhI1-1642084975659)(C:\Users\Admin\AppData\Roaming\Typora\typora-user-images\image-20220113214716740.png)]](https://img-blog.csdnimg.cn/f8c95fbd729e4368a8105645689effe0.png)
2.选择maven工程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-m8uqZ5PJ-1642084975660)(C:\Users\Admin\AppData\Roaming\Typora\typora-user-images\image-20220113214746144.png)]](https://img-blog.csdnimg.cn/f093b99841034fd2895201ceac8c66b8.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-prhXV1Al-1642084975661)(C:\Users\Admin\AppData\Roaming\Typora\typora-user-images\image-20220113215111990.png)]](https://img-blog.csdnimg.cn/12038fc9c54c4a02bf494fc05045361b.png)
3.配置pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.yingzi</groupId>
<artifactId>Demo_1</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>
</project>
4.在src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
4.编写程序
先在/main/java下创建一个包名:com.yingzi.mapreduce.wordcount
1.编写Mapper
package com.yingzi.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* @author 影子
* @create 2022-01-13-21:58
**/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割
String[] words = line.split(" ");
// 3 输出
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
}
2.编写Reducer
package com.yingzi.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* @author 影子
* @create 2022-01-13-21:58
**/
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
int sum;
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
// 1 累加求和
sum = 0;
for (IntWritable count : values) {
sum += count.get();
}
// 2 输出
v.set(sum);
context.write(key,v);
}
}
3.编写Driver
package com.yingzi.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* @author 影子
* @create 2022-01-13-21:58
**/
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 获取配置信息以及获取job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 关联本Driver程序的jar
job.setJarByClass(WordCountDriver.class);
// 3 关联Mapper和Reducer的jar
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 4 设置Mapper输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path("C:\\Users\\Admin\\Desktop\\input\\hello.txt")); //文件存放路径
FileOutputFormat.setOutputPath(job, new Path("C:\\Users\\Admin\\Desktop\\output")); //结果存放路径(注,output目录规定不存在,否则报错)
// 7 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
4.本地测试结果如下
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CB7VVtov-1642084975662)(C:\Users\Admin\AppData\Roaming\Typora\typora-user-images\image-20220113220928753.png)]](https://img-blog.csdnimg.cn/7ad88d3c099949499367cd6f865ddd2a.png)
二:传至集群
1.将文件打包成.jar
往pom.xml添加打包插件,完整配置文件如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.yingzi</groupId>
<artifactId>Demo_1</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tw5Jor0T-1642084975662)(C:\Users\Admin\AppData\Roaming\Typora\typora-user-images\image-20220113221841948.png)]](https://img-blog.csdnimg.cn/ef8825544d3d42e093ebdca4e2b35363.png)
2.将Demo_1-1.0-SNAPSHOT.jar移到桌面,并命名为wc.jar,准备上传到集群
3.打开集群所需的虚拟机,将wc.jar拖拽(上传)至虚拟机内
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JyQC55KN-1642084975662)(C:\Users\Admin\AppData\Roaming\Typora\typora-user-images\image-20220113222247379.png)]](https://img-blog.csdnimg.cn/dd9547b892734c29a412d6df2ddef37d.png)
4.启动集群:
NameNode虚拟机内启动:sbin/start-dfs.sh
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-e4kPPgAj-1642084975663)(C:\Users\Admin\AppData\Roaming\Typora\typora-user-images\image-20220113222638302.png)]](https://img-blog.csdnimg.cn/8f42d710f8ea46a58a3d3c644a285484.png)
RescourceManager虚拟机内启动:sbin/start-yarn.sh
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1pv2Y1xA-1642084975663)(C:\Users\Admin\AppData\Roaming\Typora\typora-user-images\image-20220113223355919.png)]](https://img-blog.csdnimg.cn/ae2c0031f3bc4b2b8cce5251a4f07931.png)
5.网页输入:http://hadoop102:9870/explorer.html#/
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bxpyLs7K-1642084975664)(C:\Users\Admin\AppData\Roaming\Typora\typora-user-images\image-20220113222741032.png)]](https://img-blog.csdnimg.cn/253225c1403943e5abfdf4e1c1dc4a3f.png)
前期已将目标hello.txt文档放入input目录下
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JAqLtmra-1642084975664)(C:\Users\Admin\AppData\Roaming\Typora\typora-user-images\image-20220113222812306.png)]](https://img-blog.csdnimg.cn/86d893271b644ba6b3dadf19d0d3069f.png)
6.输入命令
hadoop jar wc.jar com.yingzi.mapreduce.wordcount.WordCountDriver /input /output
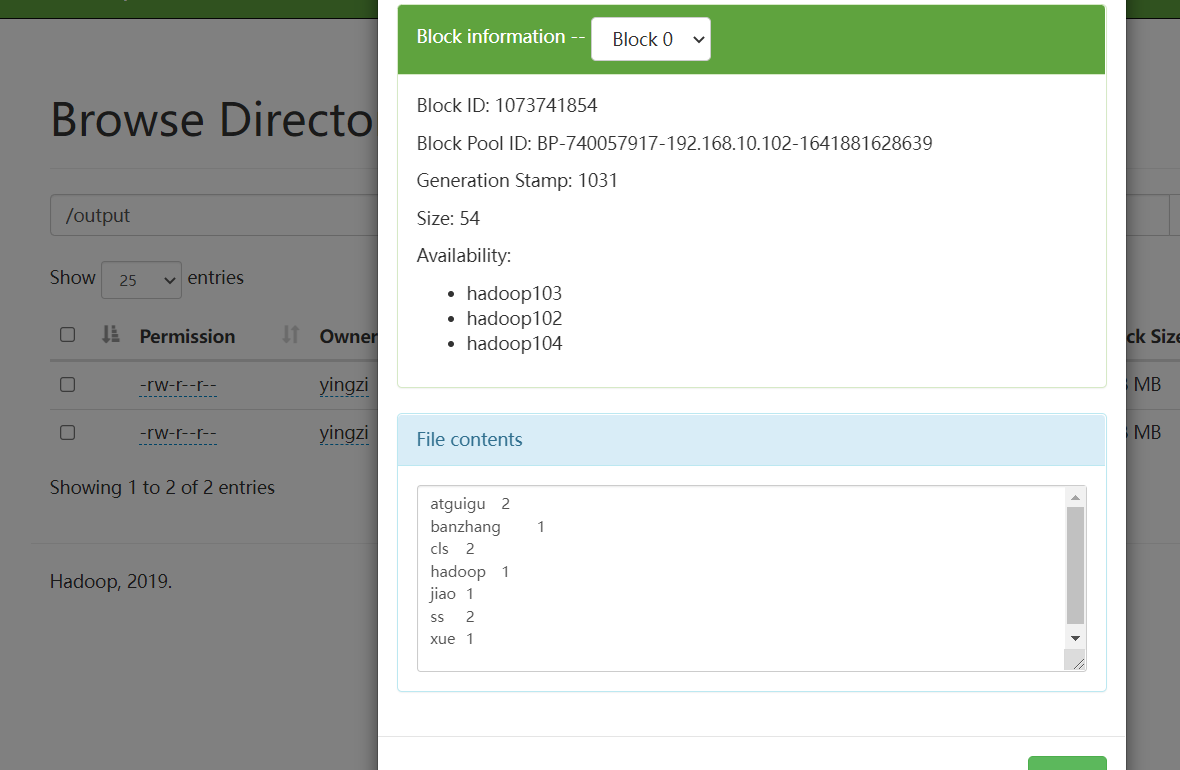
7.查看结果
多出来的output目录里,存放着我们需要的结果
















 167
167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









