









先看项目成品的效果

GitHub地址:https://github.com/GTyingzi/Flink_Demo
Gitee地址:https://gitee.com/gtcs/Flink-Demo
主要框架版本选型
| 框架 | 版本 |
|---|---|
| Hadoop | 3.13 |
| Zookeeper | 3.5.7 |
| Kafka | 2.4.1 |
| HBase | 2.0.5 |
| Phoenix | 5.0.0 |
| MySQL | 5.7.16 |
| Redise | 6.2.1 |
| ClickHouse | 20.4.5.36 |
| Flink | 1.13.0 |
| Nginx | 1.12.2 |
| java | 1.8.0_212 |
| SpringBoot | 2.3.7 |
| scala | 2.12 |
集群服务器规划
| 服务名称 | 子服务 | 服务器(hadoop102) | 服务器(hadoop103) | 服务器(hadoop104) |
|---|---|---|---|---|
| HDFS | NameNode | √ | ||
| DataNode | √ | √ | √ | |
| Zookeeper | Zookeeper Server | √ | √ | √ |
| Kafka | Kafka | √ | √ | √ |
| MySQL | MySQL | √ | ||
| Redise | Redis | √ | ||
| ClickHouse | ClicHouse | √ | ||
| Nginx | Nginx | √ | ||
| HBase | HMaster | √ | ||
| HRegionServer | √ | √ | √ | |
| Flink | Flink | √ | √ | √ |
| Phoenix | Phoenix | √ |
实时架构
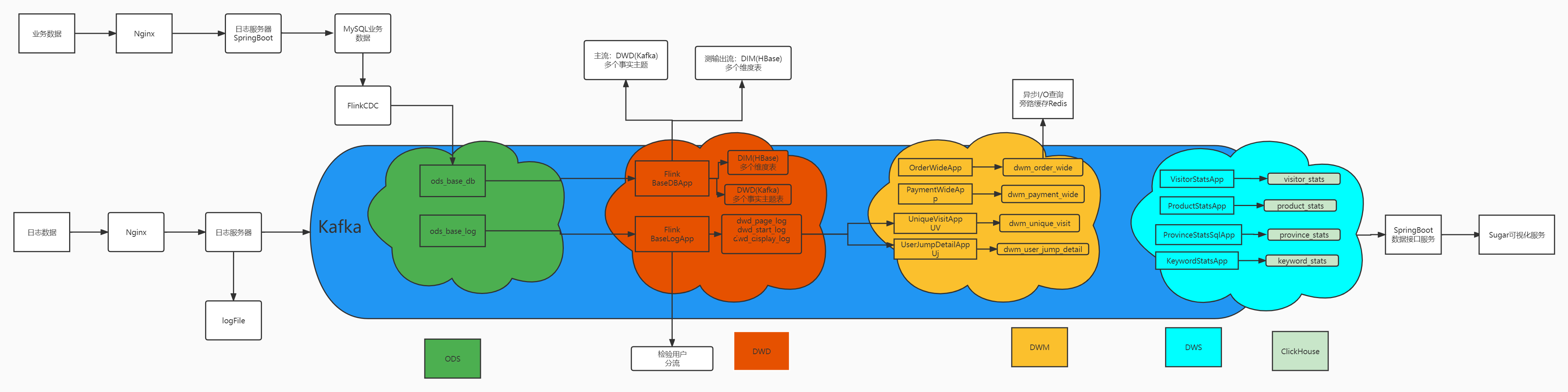
- ODS:原始数据,日志、业务数据
- DWD:根据数据对象为单位进行分流,比如订单、页面访问等
- DIM:维度数据
- DWM:对部分数据对象进行进一步加工,也可和维度数据进行关联,形成宽表
- DWS:根据某个主题将多个事实数据轻度聚合,形成主题宽表
- ADS:将ClickHouse中的数据可视化
架构的选择
分层分析
ODS
数据源:行为数据,业务数据
架构分析:
FlinkCDC:
DataStream/FlinkSQL
FlinkCDC/Maxwell/Canal
保持数据原貌,不做任何修改!
ods_base_log,ods_base_db
DWD-DIM
行为数据:DWD(Kafka)
1、过滤数据 -> 侧输出流 脏数据率
2、新老用户校验 -> 前台校验不准
3、分流 -> 侧输出流 页面、启动、曝光、动作、错误
4、写入Kafka
业务数据:DWD(Kafka)-DIM(Phoenix)
1、过滤数据 -> 删除数据
2、读取配置表创建广播流
3、连接主流和广播流
1)广播流数据:
a、解析数据
b、Phoenix建表
c、写入状态广播
2)主流数据
a、读取状态
b、过滤字段
c、分流(添加SinkTable字段)
4、提取Kafka和HBase流分别对应的位置
5、HBase流:自定义Sink
6、Kafka流:自定义序列化方式
DWM
DWM的定位:服务DWS,部分需求直接从DWD到DWS中间会有一定的计算量,而且这部分计算结果可能被多个DWS主题复用,故这部分DWD会形成一层DWM,这里主要有四个业务:访问UV计算、跳出明细计算、订单宽表、支付宽表
UV(Unique Visitor):独立访客,在实时计算中又被称为DAU(Daily Active User)。从用户行为日志中识别出当日的访客
1、识别出该访客打开的第一个页面,表示该访客开始进入我们的应用
2、访客一天内能多次进入应用,在一天范围内要进行去重
跳出:用户成功访问了网站的一个页面后就退出。不在继续访问网站的其他页面。跳出率 = 跳出次数/访问次数,关注跳出率可以看出引流来的访客是否能很快被吸引,渠道引流来的用户质量对比。跳出行为特征(本质是条件时间+超时时间的组合)
1、该页面是用户近期访问的第一个页面
2、首次访问之后很长一段时间,用户没继续再有其他页面的访问
订单宽表:订单是统计分析的重要对象,围绕订单有很多的维度统计需求,如用户、地区、商品、品类、品牌等为了之后统计计算方便,减少大表之间的关联,故在实时计算过程中将围绕订单的相关数据整合成为一种订单宽表
旁路缓存优化
异步查询优化
支付宽表:支付宽表的目的,最主要的原因是支付表没有到订单明细,支付金额没有细分到商品上,没有办法统计商品级的支付状况。支付宽表的核心是支付表的信息与订单宽表关联上
1、一个是把订单宽表输出到 HBase 上,在支付宽表计算时查询 HBase,这相当于把订单宽表作为一种维度进行管理
2、一个是用流的方式接收订单宽表,然后用双流 join 方式进行合并。因为订单与支付产生有一定的时差。所以必须用 intervalJoin 来管理流的状态时间,保证当支付到达时订单宽表还保存在状态中。
DWS
DWS层的定位:
轻度聚合,因为 DWS 层要应对很多实时查询,如果是完全的明细那么查询的压力是非常大的
将更多的实时数据以主题的方式组合起来便于管理,同时也能减少维度查询的次数
需求分析与思路:
接收各个明细数据,变为数据流
把数据流合并在一起,成为一个相同格式对象的数据流
对合并的流进行聚合,聚合的时间窗口决定了数据的时效性
把聚合结果写在数据库中
FlinkCDC的选取
| FlinkCDC | Maxwell | Canal | |
|---|---|---|---|
| 断点续传 | CK | MySQL | 本地磁盘 |
| SQL -> 数据 | 无 | 无 | 一对一(炸开) |
| 初始化功能 | 有(多库多表) | 有(单表) | 无 |
| 封装格式 | 自定义 | JSON | JSON(c/s自定义) |
| 高可用 | 运行集群高可用 | 无 | 集群(ZK) |
旁路缓存优化
一种非常常见的按需分配缓存的模式。如下图,任何请求优先访问缓存, 缓存命中,直接获得数据返回请求。如果未命中则,查询数据库,同时把结果写入缓存以备 后续请求使用
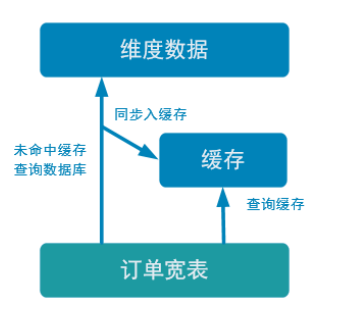
该缓存策略的注意事项
- 缓存要设过期时间,不然冷数据会常驻缓存浪费资源
- 要考虑维度数据是否会发生变化,如果发生变化要主动清除缓存
缓存选型
一般两种:堆缓存或者独立缓存服务(redis,memcache)
- 堆缓存:性能角度看更好,访问数据路径更短,减少过程消耗。但是管理性差, 其他进程无法维护缓存中的数据
- 独立缓存服务:本身性能也不错,不过会有创建连接、网络 IO 等消耗。但是考虑到数据如果会发生变化,那还是独立缓存服务管理性更强,而且如果数据量特别大,独立缓存更容易扩展
异步查询优化
默认情况下,在 Flink 的 MapFunction 中,单个并行只能用同步方式去交互: 将请求 发送到外部存储,IO 阻塞,等待请求返回,然后继续发送下一个请求。这种同步交互的方式往往在网络等待上就耗费了大量时间。为了提高处理效率,可以增加 MapFunction 的并 行度,但增加并行度就意味着更多的资源,并不是一种非常好的解决方式
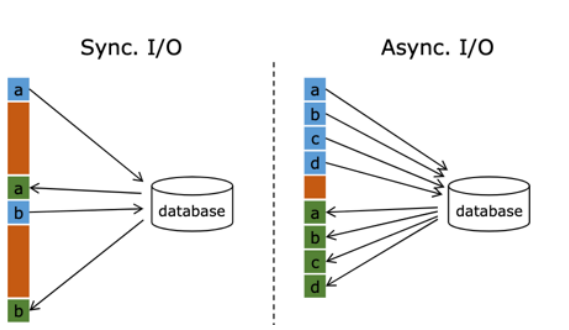
异步查询实际上是把维表的查询操作托管给单独的线程池完成,这样不会因为某一个查 询造成阻塞,单个并行可以连续发送多个请求,提高并发效率,这种方式特别针对涉及网络 IO 的操作,减少因为请求等待带来的消耗
原文链接:Flink实时数仓完结~
















 1608
1608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









