







这篇论文也是用的CSR格式在GPU上计算,是AMD发的一篇研究。上一篇论文说这一片论文是SpMV GPU计算的SOTA。
首先简单介绍一下AMD GPU的结构,如下图所示:
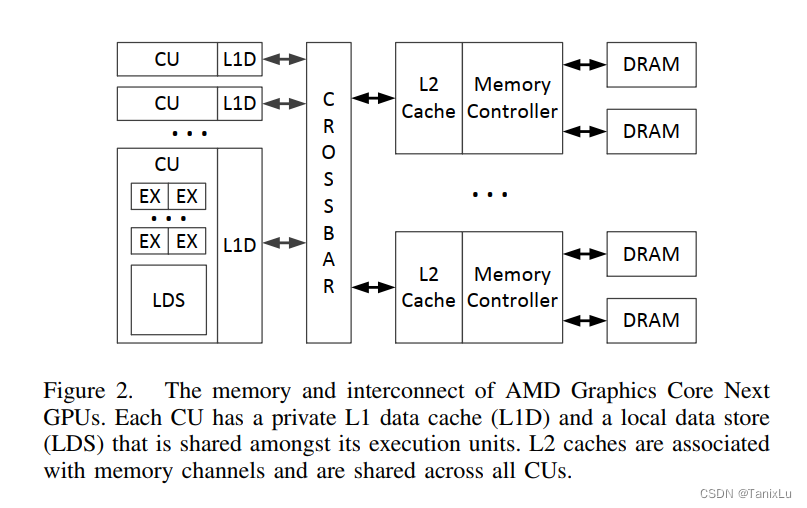
主要就是有一个LDS,每个CU(Computing Unit)本地的存储,也叫Shared Memory。
稀疏矩阵每一行的计算有两个极端,一种是每个线程一行,另一种是所有线程一行。
传统的CSR格式算法也有两个极端,CSR-Scalar和CSR-Vector,分别对应上述两个极端。但是传统的CSR-Scalar在CPU上运行的不错,在GPU上就不行了:

这是因为访问内粗不规则。
文中提出了一种针对GPU的类似于CSR-Scalar的算法,叫CSR-Stream。就是把数据先Stream到LDS上,然后再每个线程一行计算:

CSR-Stream对短行集合效果不错,但是如果行很长,就不能用这种方法了,可以中CSR-Vector。这两者结合,就形成了CSR-Adaptive算法,它会先将行划分成一个个row blocks,划分的标准应该是能否装到LDS里去。如果blocks行数过少,说明每行非零元过多,所以要用CSR-Vector,否则就用CSR-Stream。
文中做了实验确定了一些参数,一个是每个workgroup多少个非零元,结果是1024最好,然后行数为1或2的workgroup使用CSR-Vector。最终的效果非常好。
我觉得这篇文章提速的关键在于利用了LDS(shared memory)这个GPU存储结构,使得原来内存带宽的瓶颈缓解了。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









