









Abstract
递归结构是视频超分辨率任务的常用框架选择。最先进的方法BasicVSR采用双向传播和特征对齐,有效地利用整个输入视频中的信息。在这项研究中,我们通过提出二阶网格传播和流引导变形对齐来重新设计BasicVSR。我们表明,通过增强传播和对齐的递归框架,可以更有效地利用错位视频帧中的时空信息。在类似的计算约束下,新组件可以提高性能。特别是,我们的模型BasicVSR++在参数数目相似的情况下,PSNR比BasicVSR高出0.82 dB。除了视频超分辨率,BasicVSR++还可以很好地推广到其他视频恢复任务,如压缩视频增强。在2021的NTIRE中,BasicVSR++在视频超分辨率和压缩视频增强挑战中获得了三个冠军和一个亚军。
1. Introduction
视频超分辨率(VSR)具有挑战性,因为人们需要收集错位视频帧的补充信息以进行恢复。一种流行的方法是滑动窗口框架[9、32、35、38],其中视频中的每一帧都是使用短时间窗口内的帧来恢复的。与滑动窗口框架不同,递归框架试图通过传播潜在特征来利用长期依赖关系。一般来说,与滑动窗口框架中的方法相比,这些方法[8、10、11、12、14、27]允许更紧凑的模型。然而,在循环模型中传输长期信息和跨帧对齐特征的问题仍然很棘手。
Chan等人最近的一项研究仔细研究了这些问题。它将常见的VSR管道归纳为四个部分,即传播、对齐、聚合和上采样,并提出了基本的VSR。在BasicVSR中,采用双向传播技术从整个输入视频中提取信息进行重建。对于对齐,采用光流进行特征扭曲。BasicVSR是一个简洁而强大的主干,在这里可以轻松添加组件以提高性能。然而,它在传播和对齐方面的初级设计限制了信息聚合的功效。因此,该网络往往难以恢复精细的细节,特别是在处理被遮挡的复杂区域时。这些缺点要求我们在传播和排列方面进行完善的设计。
在这项工作中,我们通过设计二阶网格传播和流动引导的可变形排列来重新设计BasicVSR,使信息能够更有效地被传播和聚集。
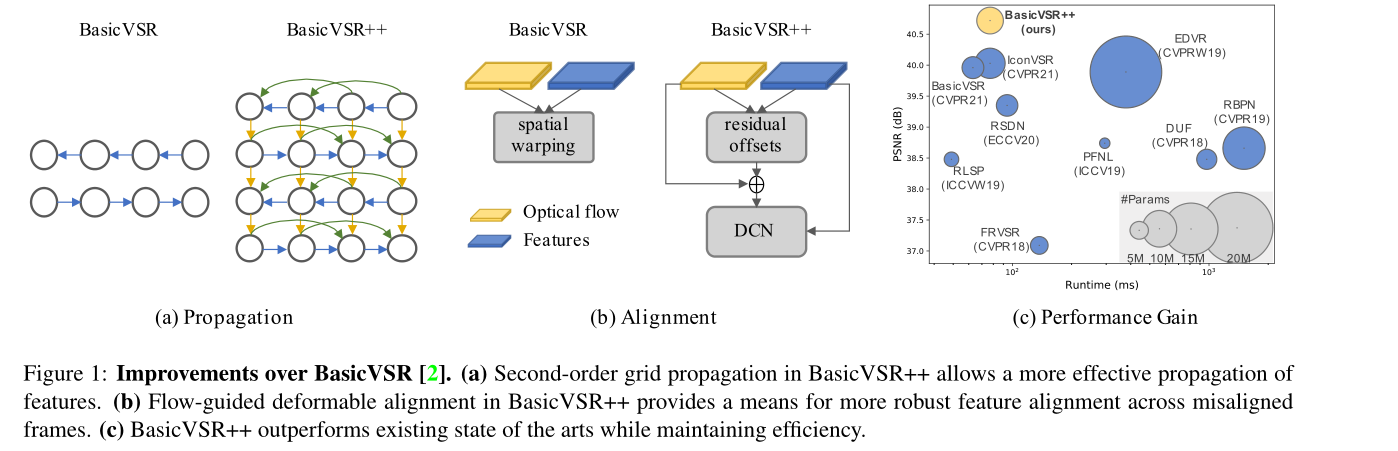
1、拟议的二阶网格传播,如图1(a)所示,解决了BasicVSR的两个限制:i)我们允许更积极的双向传播,以网格的方式排列,和ii)我们放松BasicVSR中的一阶马尔可夫属性的假设,并将二阶连接[28]纳入网络,以便信息可以从不同的时空位置聚合起来。这两个修改都改善了网络中的信息流,提高了网络对遮挡和细小区域的鲁棒性。
2、BasicVSR显示了使用光流进行时间对准的优势。然而,光流对遮挡不稳定。不准确的流量估计可能会危及恢复性能。变形对准[32、33、35]在VSR中显示了其优越性,但在实践中很难进行训练[3]。为了在克服训练不稳定性的同时利用可变形对齐,我们提出了流引导可变形对齐,如图1(b)所示。在所提出的模块中,我们没有直接学习DCN偏移量[6,42],而是通过使用光流场作为由流场剩余量细化的基本偏移量来减少偏移量学习负担。后者比原始DCN偏移更稳定地学习。
上述两个组成部分都是新颖的,更多的讨论可以在相关的工作部分中找到。得益于更有效的设计,BasicVSR++可以采用比同类产品更轻量级的主干。因此,BasicVSR++在保持效率的同时,大大超过了现有的技术水平,包括BasicVSR和IconVSR(更详细的BasicVSR变体)(图1(c))。特别是,与之前的BasicVSR相比,在参数数量相似的情况下,REDS4上的峰值信噪比(PSNR)增益为0.82 dB【35】。此外,BasicVSR++在2021 NTIRE视频超分辨率[29]和压缩视频增强[39]挑战赛中获得三个冠军和一个亚军。
2. Related Work
Recurrent Networks:递归框架是各种视频处理任务中采用的流行结构,如超分辨率[8, 10, 11, 12, 14, 27]、去模糊环[24, 41]和帧插值[36]。例如,RSDN[12]采用单向传播,带有递归细节结构块和隐藏状态适应模块,以增强对外观变化和错误积累的鲁棒性。Chan等人[2]提出BasicVSR。这项工作证明了双向传播比单向传播的重要性,以更好地利用时间上的特征。此外,该研究还显示了特征对齐在对齐高度相关但不对齐的特征方面的优势。我们请读者参考[2],了解这些组件与更传统的传播和对齐方式的详细比较。在我们的实验中,我们着重于与BasicVSR进行比较,因为它是最先进的VSR方法。
Grid Connections:在各种视觉任务中可以看到类似网格的设计,如目标检测[5、30、34]、语义分割[7、30、34、43]和帧插值[25]。通常,这些设计将给定的图像/特征分解为多个分辨率,并跨分辨率采用网格来捕获精细和粗糙信息。与上述方法不同,BasicVSR++不采用多尺度设计。相反,网格结构设计为以双向方式跨时间传播。我们将不同的框架与网格连接起来,以反复优化特征,提高表达能力。
Higher-Order Propagation:研究了高阶传播以改善梯度流【16、20、28】。这些方法展示了不同任务的改进,包括分类[16]和语言建模[28]。然而,这些方法没有考虑时间对齐,这在VSR的任务中是至关重要的。为了在二阶传播中实现时间对齐,我们通过将流引导可变形对齐扩展到二阶设置,将对齐合并到我们的传播方案中。
Deformable Alignment:一些工程【32、33、35、37】采用可变形对齐。TDAN[32]使用可变形卷积在特征级执行对齐。EDVR[35]进一步提出了具有多尺度设计的金字塔级联可变形(PCD)对准。最近,Chan等人[3]分析了可变形对齐,并表明相对于基于流的对齐,性能增益来自偏移多样性。受[3]的启发,我们采用了可变形对齐,但采用了一种新的格式来克服训练的不稳定性[3]。我们的流引导可变形对准不同于偏移保真度损失[3]。后者使用光流作为训练期间的损失函数。相比之下,我们直接将光流作为基本偏移量纳入我们的模块中,从而在训练和推理过程中提供更明确的指导。
3. Methodology
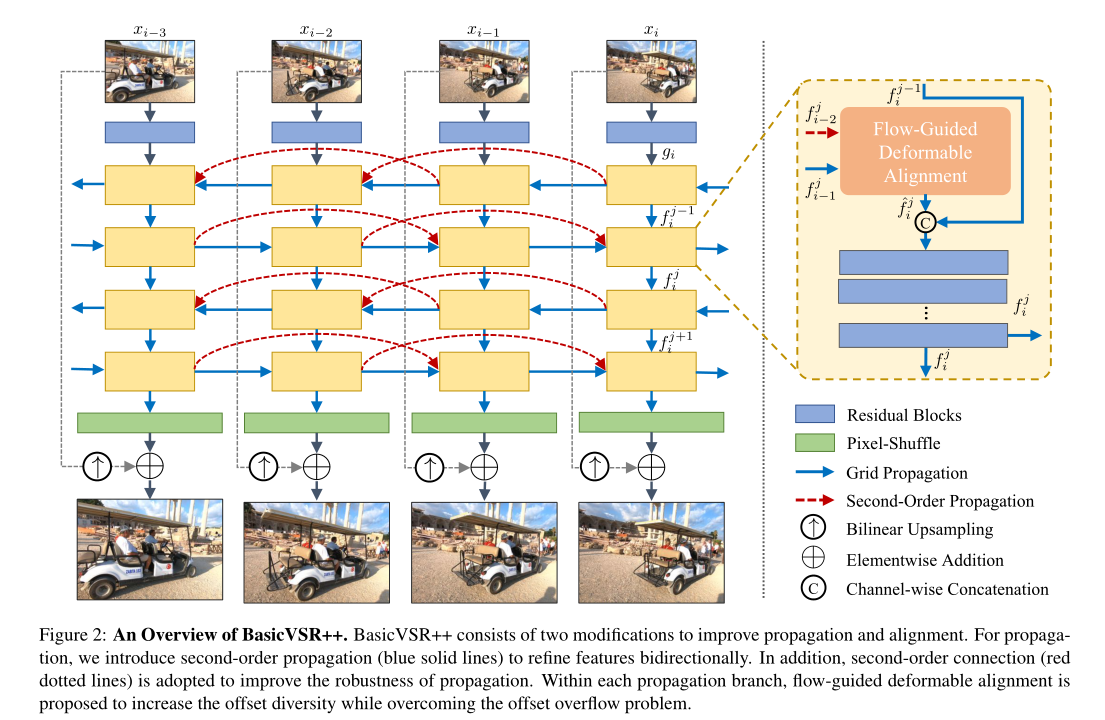
BasicVSR++包含两个有效的修改,用于改进传播和对齐。如图2所示,给定一个输入视频,首先应用剩余块从每一帧中提取特征。然后在我们的二阶网格传播方案下传播特征,其中对齐由我们的流引导可变形对齐执行。传播后,聚集的特征通过卷积和像素洗牌生成输出图像。
 3.1. Second-Order Grid Propagation
3.1. Second-Order Grid Propagation
大多数现有方法采用单向传播[12、14、27]。一些作品[2、10、11]采用双向传播来利用视频序列中可用的信息。特别是,IconVSR[2]由具有顺序连接分支的耦合传播方案组成,以促进信息交换。
基于双向传播的有效性,我们设计了一种网格传播方案,以通过传播实现重复细化。更具体地说,中间特征以交替方式在时间上前后传播。通过传播,可以“重新访问”来自不同帧的信息,并将其用于特征细化。与只传播一次特征的现有工作相比,网格传播可以重复地从整个序列中提取信息,从而提高特征的表达能力。
为了进一步提高传播的稳健性,我们放宽了BasicVSR中一阶马尔可夫属性的假设,采用二阶连接,实现了二阶马尔可夫链。通过这种放松,信息可以从不同的时空位置聚集起来,提高了在遮挡和精细区域的鲁棒性和有效性。
综合上述两个部分,我们设计了如下的二阶网格传播。设xi为输入图像,gi为通过多个残差块从xi中提取的特征,f j i为在第j个传播分支的第i个时间步计算的特征。在这一节中,我们描述了前向传播的程序,后向传播的程序定义与此类似。为了计算特征f j i,我们首先使用我们提出的流动引导的可变形对齐方式对f j i-1和f j i-2进行对齐(遵循二阶马尔科夫链),这将在下一节讨论。

3.2. Flow-Guided Deformable Alignment
可变形对齐[33, 35]比基于流动的对齐[9, 38]有明显的改进,这要归功于可变形卷积(DCN)[6, 42]中固有的偏移多样性[3]。然而,可变形配准模块可能很难训练[3]。训练的不稳定性常常导致偏移量溢出,恶化了最终的性能。为了利用偏移量的多样性,同时克服不稳定性,我们建议采用光流来指导可变形配准,这是由可变形配准和基于光流的配准之间的密切关系所激发的[3]。图3中显示了图形说明。在本节的其余部分,我们将详细介绍前向传播的对齐程序。后向传播的程序定义与此类似。为了简化记法,上标j被省略了。
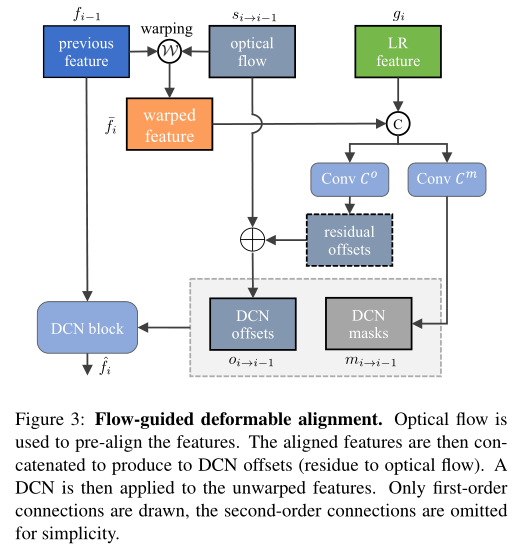
Discussion:与现有的直接计算DCN偏移量的方法[32, 33, 35, 37]不同,我们提出的流动引导的可变形对准采用了光流作为引导。其好处是双重的。首先,由于CNN已知有局部感受野,通过使用光流对特征进行预对准,可以帮助学习关集。其次,通过只学习残差,网络工作只需要学习与光流的微小偏差,减少了典型的可变形对齐模块的负担。此外,DCN中的调制掩码不是直接连接扭曲的特征,而是作为注意力图来权衡不同像素的贡献,提供额外的灵活性。
4. Experiments

训练采用了两种广泛使用的数据集:REDS[23]和Vimeo-90K[38]。对于RED,遵循BasicVSR[2],我们使用REDS43作为测试集,使用REDSval44作为验证集。其余片段用于训练。我们使用Vid4【21】、UDM10【40】和Vimeo90K-T【38】以及Vimeo-90K作为测试集。所有模型均采用4×下采样进行测试,使用两种退化-双三次(BI)和模糊下采样(BD)
我们采用Adam优化器[17]和Cosine Annealing方案[22]。主网络和流量网络的初始学习速率设置为1×10−4和2.5×10−5。总迭代次数为600K,在前5000次迭代中,流网络的权重是固定的。批量大小为8,输入LR帧的补丁大小为64×64。我们使用Charbonnier损失[4],因为它比传统的“2-损失[18]更好地处理异常值并提高性能。我们使用预训练的SPyNet[26]作为我们的流网络。其参数和运行时间在我们的方法中考虑全面。每个分支的剩余块数设置为7。功能通道的数量为64个。补充材料中提供了详细的实验设置和模型结构。
4.1. Comparisons with State-of-the-Art Methods
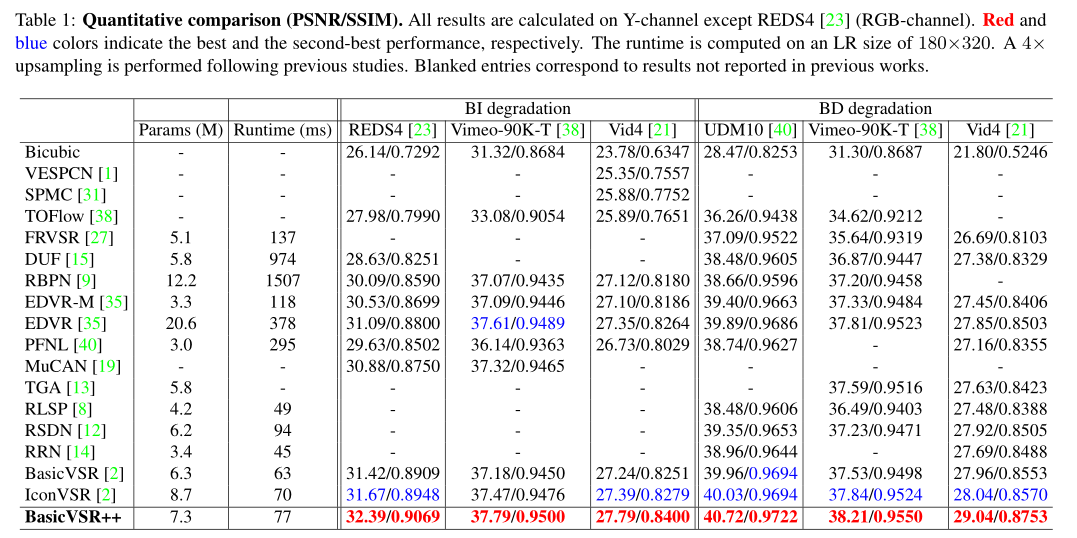 我们通过与16个模型进行比较,进行了全面的实验,如表1所示。表1总结了定量结果,图1(c)提供了速度和性能比较。注意,上述参数包括光流网络中的参数(如有)。所以这个比较是公平的
我们通过与16个模型进行比较,进行了全面的实验,如表1所示。表1总结了定量结果,图1(c)提供了速度和性能比较。注意,上述参数包括光流网络中的参数(如有)。所以这个比较是公平的
如表1所示,BasicVSR++在两种退化的所有数据集上都实现了最先进的性能。特别是,BasicVSR++优于EDVR[35],EDVR是一种大容量滑动窗口方法,峰值信噪比高达1.3 dB,同时参数减少了65%。与以前最先进的IconVSR[2]相比,BasicVSR++具有更少的参数,但提高了1 dB。如表2所示,即使我们训练一个较轻版本的BasicVSR++(表示为BasicVSR++(S)),其网络参数和运行时间与BasicVSR和IconVSR相当,我们的模型仍然显示比BasicVSR提高了0.82 dB,比IconVSR提高了0.57 dB。这种增益在VSR中被认为是显著的。
一些定性比较如图11至图14所示。BasicVSR++成功地恢复了精细细节。特别是,BasicVSR++是恢复图11中车轮辐条、图13中楼梯和图14中建筑结构的唯一方法。补充材料中提供了更多示例。
5. Ablation Studies
为了了解拟议组件的贡献,我们从基线开始,逐步插入组件。从表3可以看出,每个分量都带来了显著的改善,峰值信噪比从0.14 dB到0.46 dB不等。
理论上,我们提出的传播方案可以扩展到更高阶和更多的传播迭代。然而,当从一阶增加到二阶时,性能增益相当大(即(B)→(C) )和一到两次迭代(即(C)→BasicVSR++),我们在初步实验中观察到,进一步增加迭代次数和次数不会导致显著改善(峰值信噪比为0.05 dB),所以我们将迭代次数保持为2。
Second-Order Grid Propagation:
我们进一步提供了一些定性比较,以了解拟议传播方案的贡献。如图7的两个示例所示,在包含精细细节和复杂纹理的区域中,二阶传播和网格传播的贡献更为显著。在这些区域中,当前帧中可用于重建的信息有限。为了提高这些区域的输出质量,需要从其他视频帧进行有效的信息聚合。通过我们的二阶传播方案,可以通过稳健有效的传播来传输信息。这种补充信息基本上有助于恢复细节。如示例所示,网络使用我们的组件成功地恢复了细节,而没有我们的组件的对应部分会产生模糊的输出。
Flow-Guided Deformable Alignment:在图8(a-d)中,我们将偏移量与BasicVSR++中流量估计模块计算的光流进行比较。通过仅学习光流的残差,该网络产生的偏移量与光流高度相似,但存在明显差异。与仅从运动(光流)指示的一个空间位置聚合信息的基线相比,我们提出的模块允许从周围的多个位置检索信息,提供了额外的灵活性。
这种灵活性使特征具有更好的质量,如图8(g-h)所示。当使用光流执行扭曲时,由于空间扭曲中的插值操作,对齐的特征包含模糊边缘。相反,通过从邻居那里收集更多信息,由我们提出的模块对齐的特征更清晰,保留了更多细节。
为了证明我们设计的优越性,我们将我们的对准模块与两种变体进行了比较:(1)没有使用光流。(2) 光流用于偏移保真度损耗[3],即光流仅用作损耗函数中的监督(而不是在我们的方法中用作基本偏移)。如表4所示,如果不使用光流作为引导,不稳定性会导致训练崩溃,导致PSNR值非常低。当使用偏移保真度损失时,训练是稳定的。然而,从我们的完整模型中观察到下降了2.17 dB。我们的flowguided可变形对准直接将光流合并到网络中,以提供更明确的引导,从而获得更好的结果
Temporal Consistency:在这里,我们研究了时间一致性,这是VSR中的另一个重要方向。与滑动窗口框架相比,递归框架本质上保持了更好的时间一致性。在滑动窗口框架(例如EDVR[35])中,每个帧都是独立重建的。在这种设计中,无法保证输出之间的一致性。相反,在递归框架中(例如BasicVSR[2]),输出通过中间特征的传播而相关。时间传播本质上有助于保持更好的时间一致性。
在图9中,我们比较了BasicVSR++和两种最先进的方法——EDVR和BasicVSR之间的时间剖面。对于滑动窗口方法,EDVR的时间剖面包含显著的噪声,表明输出视频中存在闪烁伪影。相反,对于递归网络,在没有显式时间一致性建模的情况下,来自BasicVSR和BasicVSR++的配置文件表现出更好的一致性。然而,BasicVSR的剖面仍然包含不连续性。得益于我们增强的传播和对齐,BasicVSR++能够从视频帧中聚集更丰富的信息,显示出更平滑的时间过渡。补充材料中给出了视频结果。
6. NTIRE 2021 Challenge Results
在NTIRE 2021,BasicVSR++以紧凑高效的结构赢得了视频超分辨率轨道[29]。除了VSR之外,BasicVSR++还可以很好地推广到其他恢复任务。BasicVSR++在压缩视频增强挑战赛中获得两个冠军和一个亚军[39]。图10显示了压缩视频的三个不同补丁的恢复结果。BasicVSR++成功地减少了伪影,并产生了质量更好的输出。在比赛中的良好表现证明了BasicVSR++的通用性和多功能性。
7. Conclusion
在这项工作中,我们使用两个新组件重新设计了BasicVSR,以提高其在视频超分辨率任务中的传播和对齐性能。我们的模型BasicVSR++在保持效率的同时,大大优于现有的先进水平。这些设计很好地推广到其他视频恢复任务,包括压缩视频增强。这些组件是通用的,我们推测它们将用于其他基于视频的增强或恢复任务,例如去模糊和去噪。
A. Network Architecture
我们使用预训练的SPyNet[26]作为我们的流网络。初始特征提取的剩余块数设置为5,每个传播分支的剩余块数设置为7。功能通道设置为64。我们的二阶可变形对齐的架构与一阶对应结构非常相似(主要论文中的图3)。唯一的区别是,来自不同时间步长的预对准特征和光流被串联,并传递给偏移估计模块Co和掩码估计模块Cm。他们的架构详见表5。我们将DCN内核大小设置为3,可变形组的数量设置为16。代码将被发布。
B. Experimental Settings
数据集。训练采用了两种广泛使用的数据集:REDS[23]和Vimeo-90K[38]。对于RED,遵循BasicVSR[2],我们使用REDS45作为测试集,使用REDSval46作为验证集。其余片段用于训练。我们使用Vid4[21]、UDM10[40]和Vimeo-90K-T[38]以及Vimeo-90K作为测试集。
















 5252
5252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









