







 本文介绍了BERT在NLP领域的突破,特别是其在TensorFlow中的应用,涵盖了文本分类、命名实体识别和语言翻译。文章详细阐述了BERT的工作原理、预训练和微调过程,以及如何使用BERT进行实际任务的示例,如使用BERT进行文本分类和命名实体识别,并指出BERT在语言翻译中的潜在应用。
本文介绍了BERT在NLP领域的突破,特别是其在TensorFlow中的应用,涵盖了文本分类、命名实体识别和语言翻译。文章详细阐述了BERT的工作原理、预训练和微调过程,以及如何使用BERT进行实际任务的示例,如使用BERT进行文本分类和命名实体识别,并指出BERT在语言翻译中的潜在应用。

概述
在不断发展的自然语言处理 (NLP) 领域,BERT(来自 Transformers 的双向编码器表示)已成为一种突破性模型。本指南探讨了 BERT 及其使用 TensorFlow 的各种应用,包括文本分类、命名实体识别 (NER) 和语言翻译。本文详细介绍了每个应用程序的关键概念、步骤和端到端流程,使读者能够在其 NLP 项目中利用 BERT 的强大功能。

了解 BERT
BERT (Bi Direction Encoder Representations from Transformers)是 Google AI 于2018 年开发的革命性自然语言处理(NLP)模型。该模型通过引入一种新颖的预训练和迁移学习方法,显着改变了 NLP 的格局。
- 双向上下文理解:传统语言模型,例如单向 LSTM 和 GPT(生成式预训练变换器),以从左到右或从右到左的方式处理文本,仅捕获上下文的一侧。另一方面,BERT 通过一次训练整个输入句子来引入双向上下文。这使得 BERT 能够从两个方向考虑周围的单词,从而更深入地理解上下文和含义。
- Transformers 和注意力机制:BERT 基于 Transformer 架构构建,该架构已成为 NLP 最新进展的基石。Transformer 旨在处理数据序列,同时保持并行性,使其在现代硬件上进行高效训练。Transformer 中的注意力机制对于 BERT 捕获上下文关系的能力至关重要。注意力允许序列中的每个单词关注所有其他单词,同时考虑到它们的相关性。这种机制非常适合捕获单词之间的远程依赖性和复杂关系。
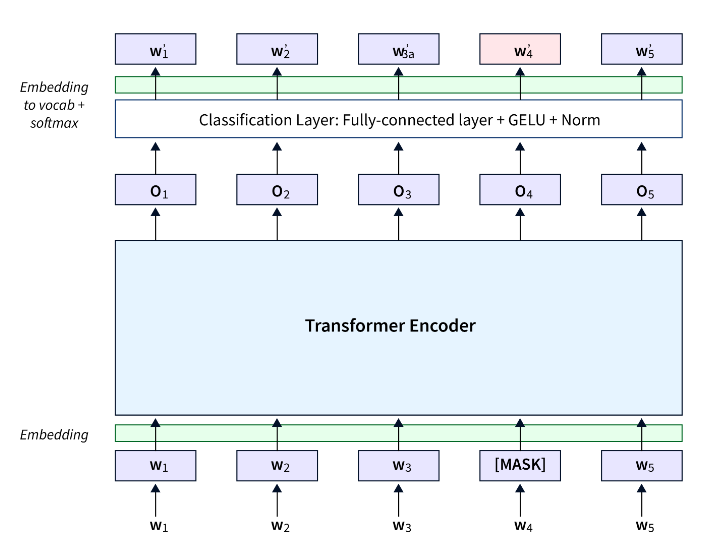
- 预训练和迁移学习:BERT 的训练过程涉及预训练和微调。在预训练阶段,使用大量文本语料库在掩码语言模型 (MLM) 任务上训练模型。在此任务中,每个句子中的一定比例的单词被随机替换为 [MASK] 标记,并且训练模型根据周围的上下文来预测这些被屏蔽的单词。在微调阶段,BERT 会适应特定的 NLP 任务。该模型使用预训练期间学习到的权重进行初始化,然后根据特定于任务的标记数据进行训练。这种迁移学习方法无需为每个任务从头开始训练大型模型,从而节省了计算资源和时间。
- 嵌入和层: BERT 通过嵌入和多层处理文本。输入文本被标记为子词片段或标记,然后映射到相应的嵌入。BERT 使用位置嵌入来保留标记的顺序,这对于理解文本的结构至关重要。
为 BERT 准备数据
为 BERT 准备数据涉及几个关键步骤,以确保模型能够有效地学习和捕获上下文。这包括标记化、输入格式化和创建注意力掩码。
-
步骤 1:标记化 标记化涉及将原始文本分解为小单元,例如单词或子词。BERT 使用 WordPiece 标记化,将单词分割成更小的子词,使模型能够处理词汇表之外的单词。
from transformers import BertTokenizer tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') text = "Preparing data for BERT is essential." tokens = tokenizer.tokenize(text) -
步骤 2:输入格式 BERT 需要对其输入进行特定格式。这包括添加特殊标记,如 [CLS](序列开始)和 [SEP](序列结束)来标记句子的开头和结尾。此外,如果处理多个句子,我们需要对输入序列进行分段。
input_ids = tokenizer.encode(text, add_special_tokens=True) -
步骤 3:创建注意力 掩码 注意力掩码帮助 BERT 区分实际标记和填充标记。添加填充是为了使所有输入序列的长度相同,但 BERT 不应该注意这些填充标记。
attention_mask = [1] * len(input_ids)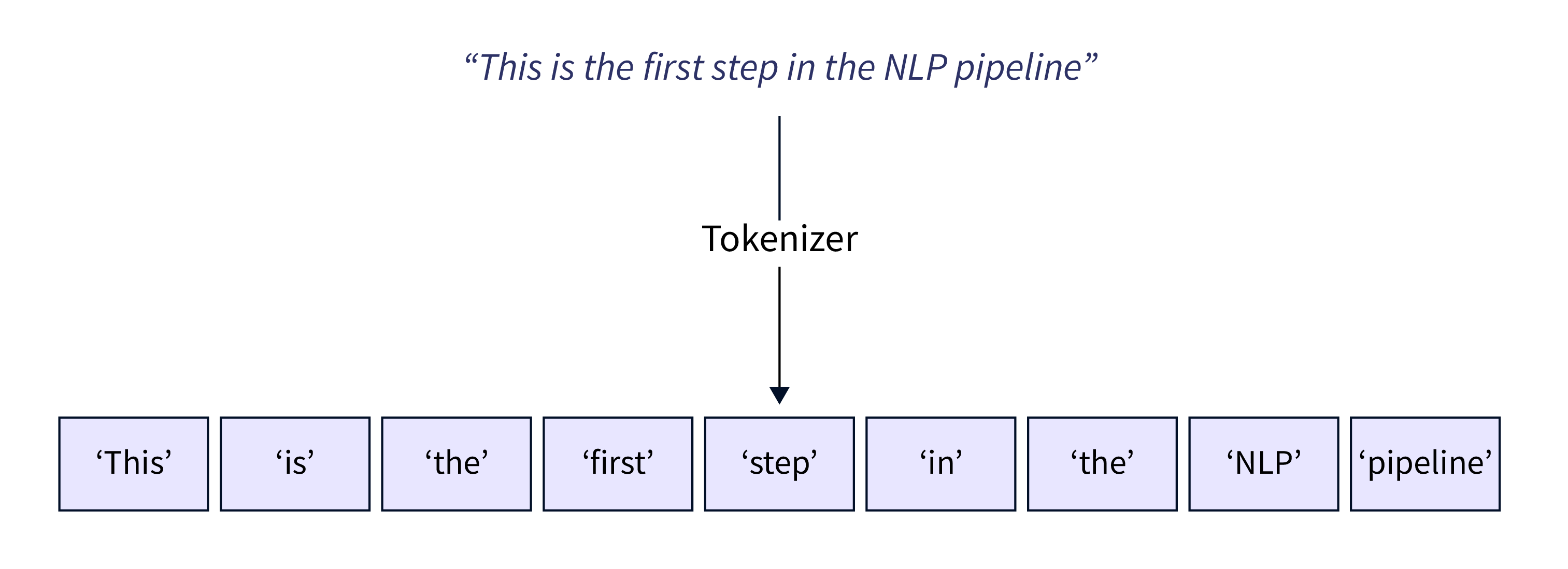
微调 BERT
微调 BERT是调整预训练模型以执行特定任务的关键步骤。此过程涉及使用预训练权重初始化 BERT,然后使用特定于任务的数据对其进行训练。让我们探讨一下微调 BERT 所涉及的步骤:
- 步骤1:在微调之前,BERT 在大量文本数据上进行预训练,以学习通用语言表示。微调利用这些预先训练的知识并使其适应目标任务。
- 步骤2:选择与您的目标N
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2165
2165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











