






1. 数据集介绍
● 数据集原为本人毕设所用,数据集图片全部从滴滴数据集
D²-City中抽帧获得,本人做了二次标注
● 数 据 集 详 细 说 明 文 档 📥下载 📥
① 数据集基本情况
-
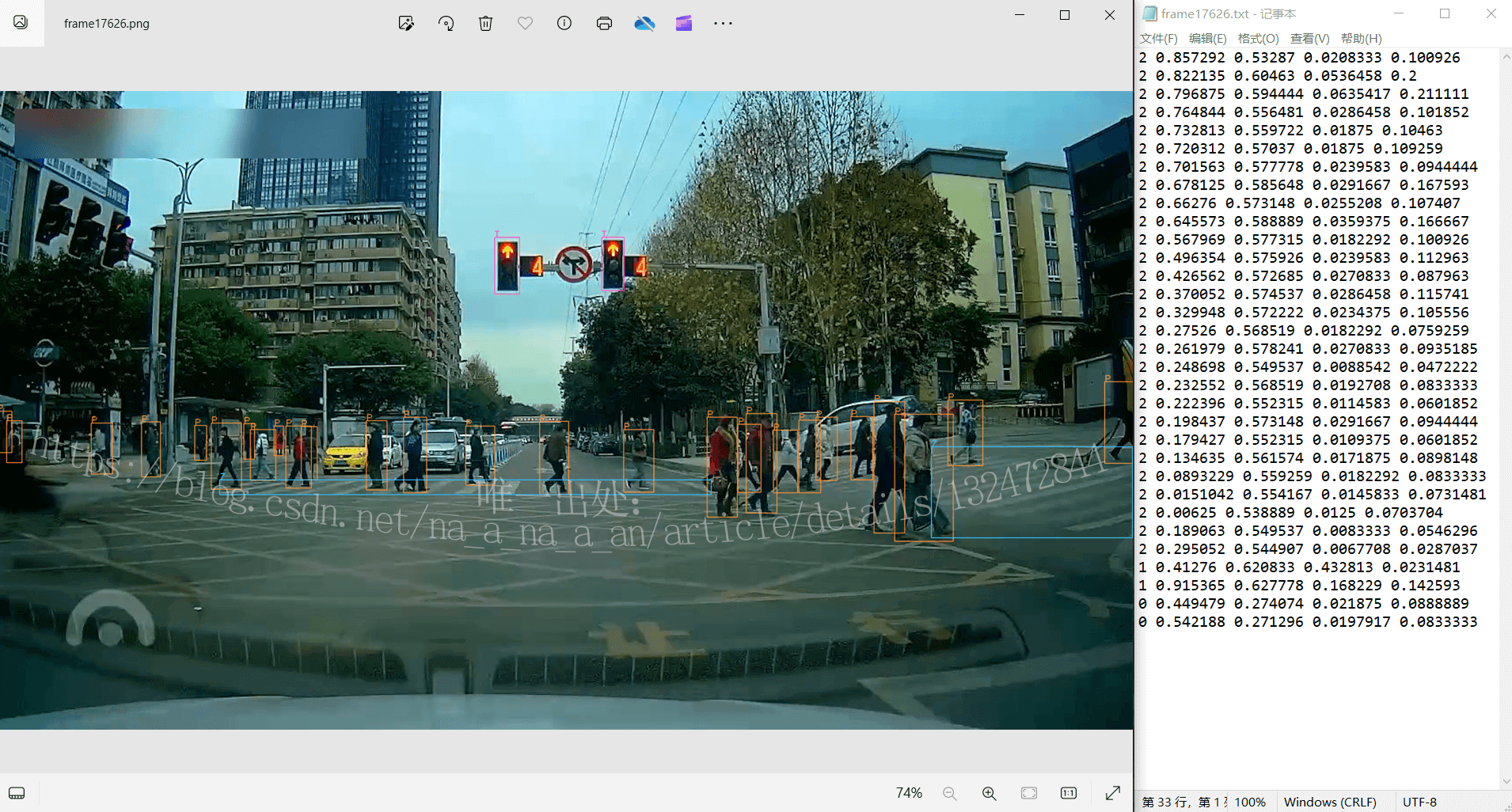
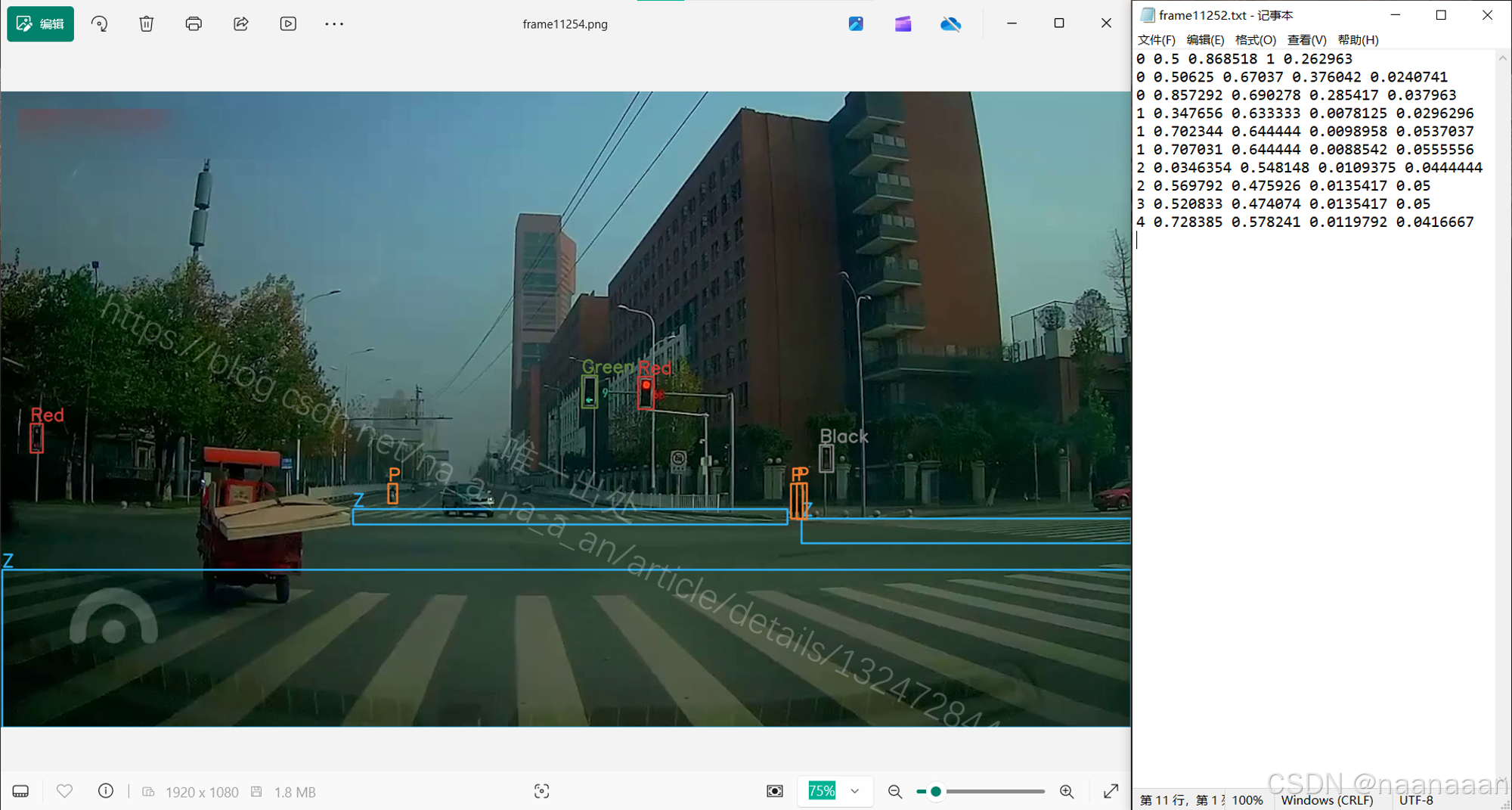
数据集共 12554 张图片,全为行车记录仪视角,标注效果👆;
-
数据集默认提供
txt标签,适合一切目标检测模型训练,包括YOLO 全系列、DETR… -
数据集按照 交通灯是否分灯色标注 有以下两个版本:
注:3类别数据集训练的模型只能判断画面中是否有交通灯;6类别数据集训练的模型才能直接识别灯色
原始 3 类别 细分灯色 6 类别 行人 行人 斑马线 斑马线 交通灯 红灯 绿灯 黄灯 黑灯(坏灯 或 闪烁中的灯)
② 数据集标注情况
标注效果视频:点这观看
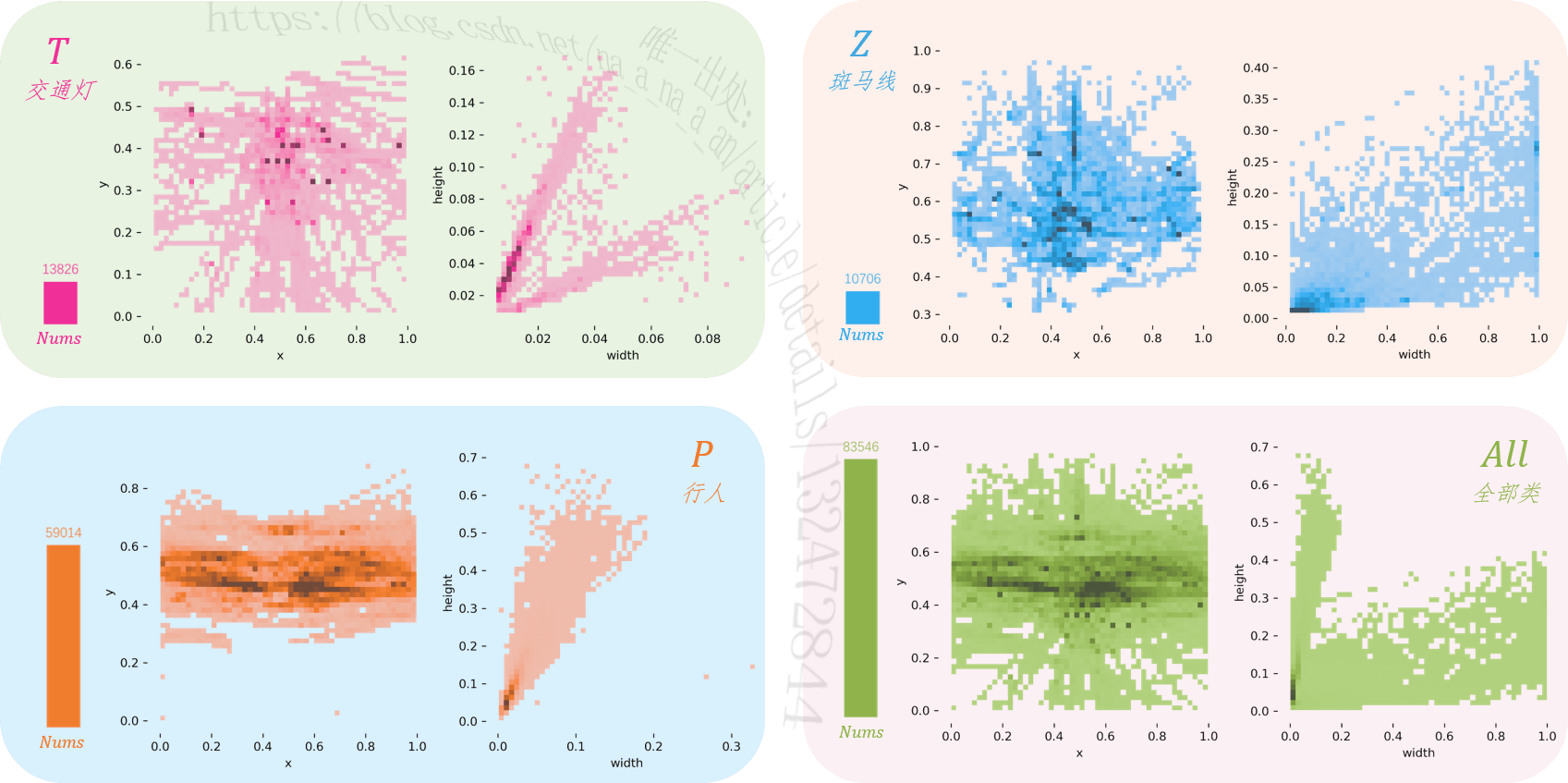

上面统计了各类实例标注框的数量、位置与大小的情况,每一个矩形色块内含有以下内容:
- 柱形图:指明该类具有多少实例(即标注数量),数值显示在柱子顶端;
- X-Y 分布图:
x、y分别为按帧宽高归一化后的标注框中心点横坐标与纵坐标,描述了该类实例标注框的位置分布。图中深色处即为该类实例在图中主要分布的位置。 - width-height 分布图:
width、height分别为按帧宽高归一化后的标注框宽度与高度,描述了该类实例标注框的大小分布。图中深色处即为该类实例标注框的主要宽度与高度。
2. 数据集使用
① 准备数据
请严格走完以下 123 步
-
视频下载:链接 (此步骤必需 ! ! !)
-
标注下载:(以下各项按自己需要,选择一项或多项)
-
按以下步骤,分帧得数据集图片:
A. 安装opencv: 终端激活环境后,输入pip install opencv-python;
B.按注释配置以下脚本的label_dir、save_dir、video_path;
(注意:若下载了3类别的,需要保证save_dir有18G的空间;单交通灯的需要8G;单斑马线的需要10G;单行人的需要16G)
C.运行脚本,确保save_dir中最终的图片数 =label_dir中的txt文件数import os import re import cv2 from glob import iglob def validate_input(video_path, label_dir): assert os.path.exists(video_path), f'无法找到视频文件: {video_path},请检查该路径是否存在!' assert video_path.endswith(".mp4"), 'video_path 需设置为所下载的mp4视频文件路径!' def label_check(file_path): file_name = os.path.basename(file_path) if file_name.startswith('frame'): try: idx = re.search(r'\d{5}', file_name).group() except AttributeError: raise ValueError(f'错误的文件名 {file_name},请勿修改txt文件名,若已修改,请删除并重新下载!') return int(idx) else: raise ValueError(f'错误的文件名 {file_name},请勿修改txt文件名或向标签所在文件夹增加自己的文件!') valid_idx = list(map( label_check, iglob(os.path.join(label_dir, '*.txt'), recursive=False) )) if not valid_idx: raise ValueError(f'无法在 {label_dir} 目录下找到txt标签文件,请检查该路径是否存在,或txt标签文件是否直接存在于该目录下!') return valid_idx def main(video_path, label_dir, save_dir): valid_idx = validate_input(video_path, label_dir) cap = cv2.VideoCapture(video_path) frame_idx = 0 count = 0 while cap.isOpened(): ret, frame = cap.read() if not ret: cap.release() break if frame_idx in valid_idx: cv2.imwrite(os.path.join(save_dir, f'frame{frame_idx:05d}.png'), frame) count += 1 print(f'\rsaving {count}...',end='') frame_idx += 1 if __name__ == '__main__': label_dir = r'' # 含有所有txt文件的文件夹路径, 不用删掉前面的r, 路径中最好不要有中文 save_dir = r'' # 图片将要保存路径, 不用删掉前面的r, 路径中最好不要有中文 video_path = r'' # 下载的视频路径, 不用删掉前面的r, 路径中最好不要有中文 video_path = os.path.abspath(video_path) label_dir = os.path.abspath(label_dir) save_dir = os.path.abspath(save_dir) os.makedirs(save_dir,exist_ok=True) main(video_path, label_dir, save_dir)
② 划分数据集
按照自定比例(如8:2),以随机抽样的方式抽取训练集与测试集(可自行搜索YOLO数据集划分代码)
③ 开始训练
数据集可用于一切目标检测模型,包括
YOLO全系列、DETR等,这里以YOLOV5为例
原三类别数据集上 YOLOV5 训练结果 | 📥下载 📥 (仅供借鉴,不含权重)
- 去YoLoV5官网下载预训练权重,如 yolov5m.pt
- 在
train.py里完成超参数配置即可开始训练。本人利用YoLoV5的m6权重,在三类别数据集上以imgsz 640训练300轮,mAP 0.5 有 0.956,mAP 0.5~0.95 有 0.7299。
④ 引用
请参考这里酌情介绍本数据集与D²-City的关系,引用D²-City原文(下载),并在脚注中注明
“数据集源于 https://blog.csdn.net/na_a_na_a_an/article/details/132472844”
3. 其他:
① 标签格式转换
标签为txt格式,可直接用于训练。若需转xml格式,可查看 教程1 或 教程2
② 若下载了2种类别的标签,训练前需要进行这两种标签的融合!!!
若不会,可私信

















 702
702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









