







 超级会员免费看
超级会员免费看
YOLO12在2025年2月新鲜出炉啦~~~~
官方开源地址:github链接
论文下载地址:paper
目录


🔔🔔摘要
长期以来,改进YOLO框架的网络架构一直至关重要,但以往的研究主要集中在基于卷积神经网络(CNN)的改进上,尽管注意力机制在建模能力方面已被证明具有优越性。这是因为基于注意力的模型在速度上无法与基于CNN的模型相匹配。本文提出了一个以注意力为核心的YOLO框架,即YOLOv12,它在保持与之前基于CNN的模型相同速度的同时,利用了注意力机制的性能优势。
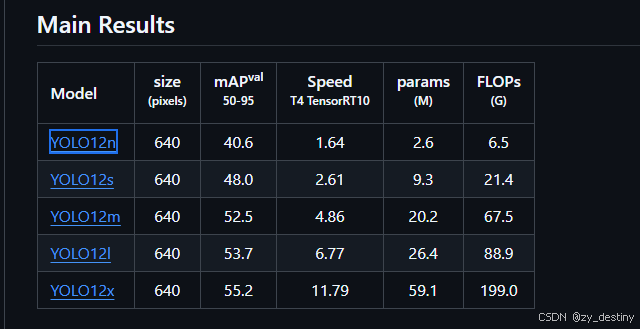
YOLOv12在准确性方面超越了所有流行的实时目标检测器,同时保持了竞争力的速度。例如,YOLOv12-N在T4 GPU上的推理延迟为1.64毫秒,达到了40.6%的mAP,超过了先进的YOLOv10-N和YOLOv11-N,分别提高了2.1%和1.2%的mAP,且速度相当。这种优势还扩展到了其他模型规模。YOLOv12还超越了改进DETR的端到端实时检测器,如RT-DETR和RT-DETRv2:YOLOv12-S在运行速度比RT-DETR-R18和RT-DETRv2-R18快42%的情况下,仅使用了它们36%的计算量和45%的参数,就击败了它们。
🍎🍎0.YOLOv12的主要创新点
🍀架构创新
-
引入注意力机制:YOLOv12采用注意力机制为核心,而YOLOv11则延续了YOLOR的CSPPAN结构和BOF技术。YOLOv12通过精心设计的区域注意力模块和后期优化,如移除位置编码、调整MLP比例、减少层深度等,解决了注意力机制计算速度慢且性能相差较大的问题,实现了在保证实时性的同时大幅提升性能。
-
R-ELAN结构:YOLOv12设计了R-ELAN结构,包括两个改进点:引入块级残差设计和重新设计的特征聚合方法。这种结构有利于更好地保留和整合特征信息,从而提高模型的性能。例如,在YOLOv12-X模型中,R-ELAN结构使得模型能够更准确地识别目标,特别是在复杂背景下的小目标检测,相比YOLOv11的ELAN结构,检测精度得到了显著提升。
-
网络架构优化:YOLOv12的网络架构从YOLOv11的CSPPAN转向类似AELAN+SE的结构。CSPPAN结构虽然具有良好的特征融合能力,但在处理大规模数据时可能会出现计算量较大、模型复杂度过高的问题。AELAN+SE结构通过更高效的特征聚合和通道注意力机制,不仅降低了计算量,还提高了特征表达能力,使模型在检测精度和速度之间达到了更好的平衡。
🍀优化机制
-
多尺度特征融合:YOLOv12优化了多尺度特征融合。YOLOv11在多尺度特征融合方面可能存在一些不足,如不同尺度特征之间的交互不够充分。而YOLOv12在这一方面进行了改进,通过更高效的融合机制,使得模型能够更好地利用不同尺度的特征信息,从而提高检测精度。例如,YOLOv12可能采用了更先进的跨尺度连接方式,使得低层的细节特征和高层的语义特征能够更好地融合,进而提升对不同大小目标的检测性能。
-
FlashAttention技术:YOLOv12引入了FlashAttention技术,这一技术显著优化了注意力计算过程。在YOLOv11中,注意力模块的计算可能会受到内存访问速度的限制,导致计算效率低下。FlashAttention技术通过优化内存访问模式和计算流程,极大地提高了注意力机制的计算效率,使得YOLOv12在保持注意力机制优势的同时,实现了更快的推理速度。
-
优化器微调及质量管理:YOLOv12在训练过程中对优化器进行了微调,并且注重质量管理。通过对学习率调度、权重衰减等参数的精细调整,以及对模型训练过程中的质量监控和管理,确保了模型能够更稳定、更高效地收敛,从而提高了最终模型的性能。例如,YOLOv12可能采用了更先进的学习率调整策略,如余弦退火学习率或动态学习率调整,使得模型能够在训练过程中更好地适应数据的变化,避免过拟合和欠拟合的问题。
-
取消TAL结构:与YOLOv11相比,YOLOv12取消了TAL结构。TAL结构可能在YOLOv11中对多尺度检测起到了一定的作用,但其存在的问题导致了性能瓶颈。YOLOv12通过其他机制替代TAL结构,例如采用更灵活的锚框分配策略或动态调整多尺度特征的权重,从而在不引入额外计算成本的情况下,改善了多尺度检测的性能。
🍀性能优势
-
更高的检测精度:YOLOv12在多个尺度的模型上都实现了更高的检测精度。例如,YOLOv12-N的mAP达到了40.6%,相比YOLOv11-N的39.4%提高了1.2%;YOLOv12-S的mAP为48.0%,比YOLOv11-S的46.9%高出1.1%。
-
更快的推理速度:由于采用了更高效的架构和优化机制,YOLOv12在保持高性能的同时,推理速度也得到了提升。例如,YOLOv12-N在T4 GPU上的推理延迟为1.64ms,而YOLOv11-N为1.5ms。虽然在绝对延迟上略高,但考虑到YOLOv12实现了更高的精度,其性价比更高。
-
更少的计算资源消耗:YOLOv12在计算资源消耗方面也更少。例如,YOLOv12-N的FLOPs为6.5G,与YOLOv11-N相同,但参数量均为2.6M,实现了资源的有效利用。这使得YOLOv12在资源受限的设备上也能够高效运行,如边缘计算设备或移动设备。
⛵⛵运行环境搭建
按照如下命令依次执行,建立虚拟环境yolov12,。
wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.3/flash_attn-2.7.3+cu11torch2.2cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
conda create -n yolov12 python=3.11
conda activate yolov12
pip install -r requirements.txt
pip install -e .🍉🍉1.数据集介绍
首先介绍使用的数据集,数据集中共包含7774张影像,部分影像展示如下:
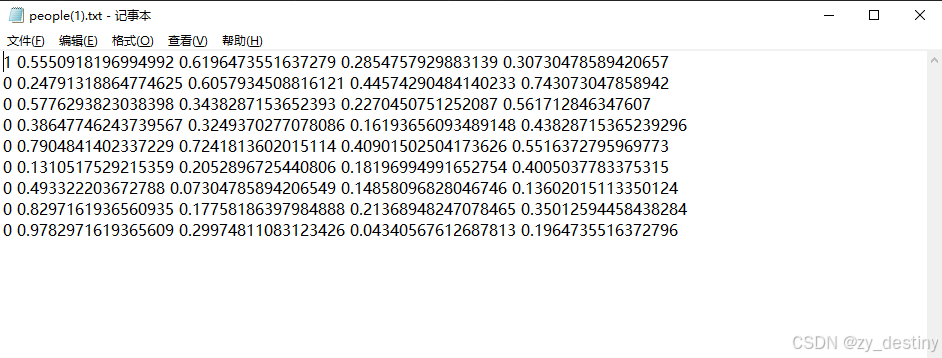
label为txt格式的yolo目标检测格式,示例txt文件内容为:
其中训练验证比例为7:1,6802张(训练): 972张(验证),也可自行分数据集。
🍇🍇2.实现效果
使用YOLOv12实现的预测效果如下:


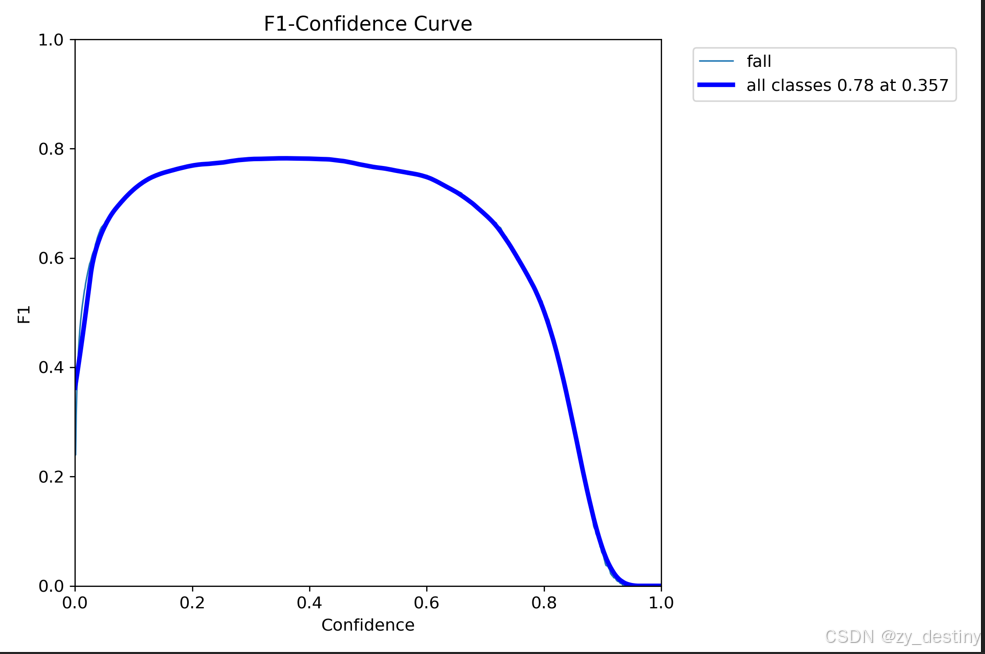
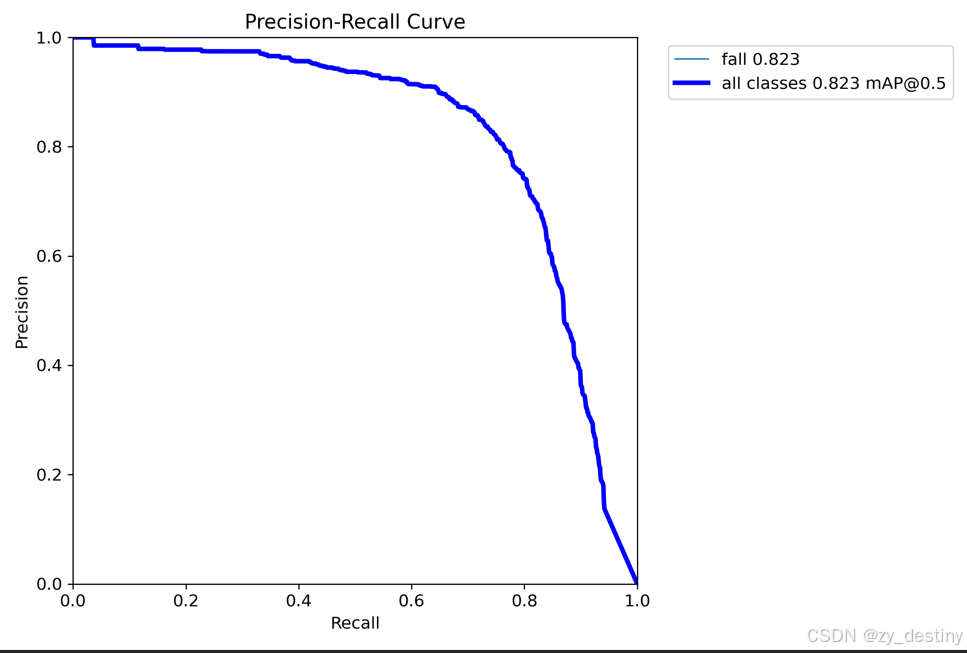
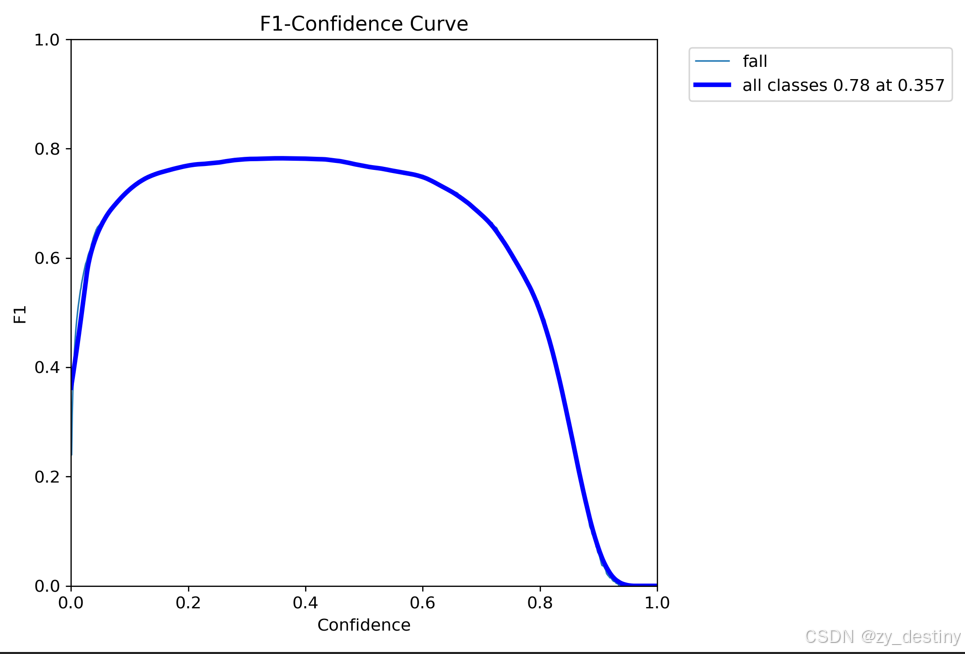
摔倒检测识别精度为82.3%
🍓🍓3.YOLOv12算法步骤
🍋3.1数据准备
数据集共包含7774张影像,其中训练集6802张 ,验证集972张。主要是摔倒,从混淆矩阵中可以看到,摔倒的占比最高。

模型训练label部分采用的是YOLO格式的txt文件,所以如果自己的数据集是xml格式需要进行转换哦。具体txt格式内容如1.数据集介绍中所示。
🍋3.2模型选择
以YOLOv12n为例,模型选择代码如下:
from ultralytics import YOLO
# Load a model
model = YOLO('yolov12.yaml') # build a new model from YAML
其中yolov12.yaml为./ultralytics/cfg/models/v12/yolov12n.yaml,可根据自己的数据进行模型调整,打开yolov12n.yaml显示内容如下:
# YOLOv12 🚀, AGPL-3.0 license
# YOLOv12 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov12n.yaml' will call yolov12.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 465 layers, 2,603,056 parameters, 2,603,040 gradients, 6.7 GFLOPs
s: [0.50, 0.50, 1024] # summary: 465 layers, 9,285,632 parameters, 9,285,616 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 501 layers, 20,201,216 parameters, 20,201,200 gradients, 68.1 GFLOPs
l: [1.00, 1.00, 512] # summary: 831 layers, 26,454,880 parameters, 26,454,864 gradients, 89.7 GFLOPs
x: [1.00, 1.50, 512] # summary: 831 layers, 59,216,928 parameters, 59,216,912 gradients, 200.3 GFLOPs
# YOLO12n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 4, A2C2f, [512, True, 4]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 4, A2C2f, [1024, True, 1]] # 8
# YOLO12n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, A2C2f, [512, False, -1]] # 11
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, A2C2f, [256, False, -1]] # 14
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 11], 1, Concat, [1]] # cat head P4
- [-1, 2, A2C2f, [512, False, -1]] # 17
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 8], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 20 (P5/32-large)
- [[14, 17, 20], 1, Detect, [nc]] # Detect(P3, P4, P5)
主要需要修改的地方为nc,也就是num_class,此处数据集类别为1类,所以nc=1。
🍋3.3加载预训练模型
加载预训练模型yolov12n.pt,可以在第一次运行时自动下载,如果受到下载速度限制,也可以自行下载好(下载链接),放在对应目录下即可。
🍋3.4数据组织
yolov12还是以yolo格式的数据为例,./ultralytics/cfg/datasets/data.yaml的内容示例如下:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco8 # dataset root dir
train: images/train # train images (relative to 'path') 4 images
val: images/val # val images (relative to 'path') 4 images
test: # test images (optional)
# Classes (80 COCO classes)
names:
0: person
1: bicycle
2: car
# ...
77: teddy bear
78: hair drier
79: toothbrush这个是官方的标准coco数据集,需要换成自己的数据集格式,此处建议根据自己的数据集设置新建一个fall_detect_coco128.yaml文件,放在./ultralytics/cfg/datasets/目录下,最后数据集设置就可以直接用自己的fall_detect_coco128.yaml文件了。以我的fall_detect_coco128.yaml文件为例:
path: /home/datasets/fall_datset # dataset root dir
train: images/train # train images (relative to 'path') 4 images
val: images/val # val images (relative to 'path') 4 images
test: images/test # test images (optional)
names:
0: fall
🍭🍭4.目标检测训练代码
准备好数据和模型之后,就可以开始训练了,train.py的内容显示为:
from ultralytics import YOLO
model = YOLO('yolov12n.yaml')
# Train the model
results = model.train(
data='fall_detect_coco128.yaml',
epochs=600,
batch=256,
imgsz=640,
scale=0.5, # S:0.9; M:0.9; L:0.9; X:0.9
mosaic=1.0,
mixup=0.0, # S:0.05; M:0.15; L:0.15; X:0.2
copy_paste=0.1, # S:0.15; M:0.4; L:0.5; X:0.6
device="0,1,2,3",
)
# Evaluate model performance on the validation set
metrics = model.val()
# Perform object detection on an image
results = model("path/to/image.jpg")
results[0].show()
训练完成后的结果如下:
其中weights文件夹内会包含2个模型,一个best.pth,一个last.pth。

至此就可以使用best.pth进行推理检测是否有人员摔倒。
🌷4.1训练结果展示
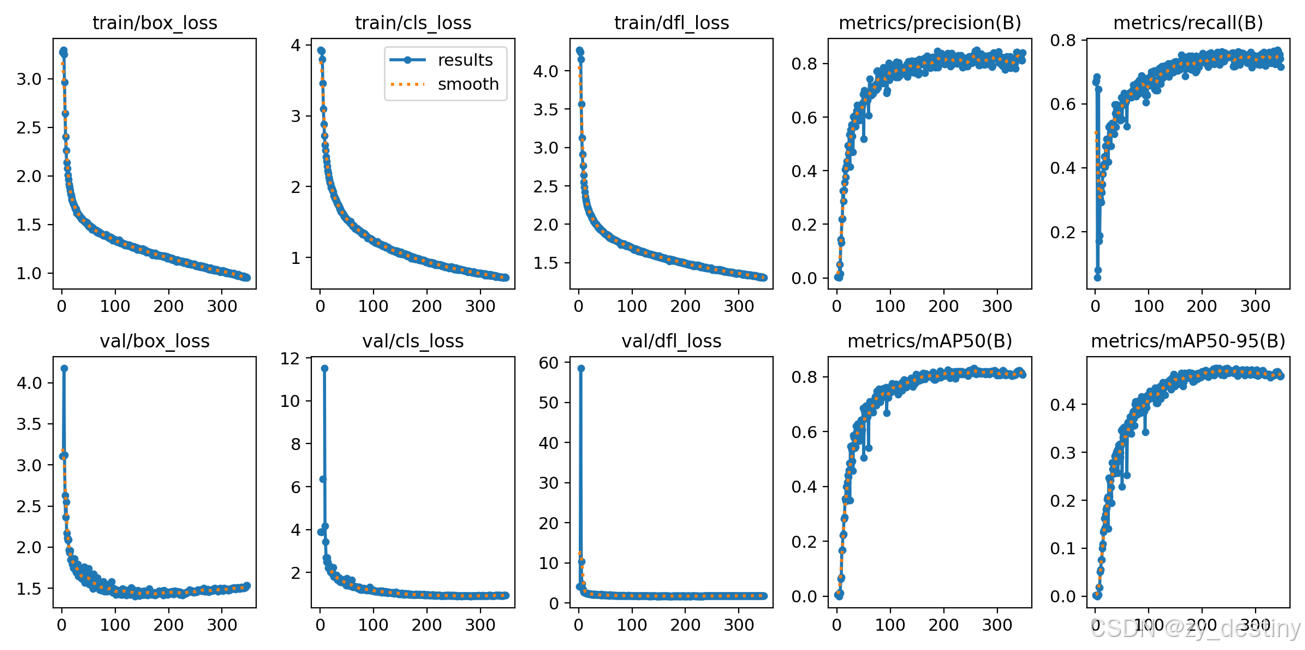
在此贴上我的训练结果:

🐸🐸5.目标检测推理代码
推理python代码如下:
from ultralytics import YOLO
model = YOLO('yolov12{n/s/m/l/x}.pt')
model.predict()若需要完整数据集和源代码可以私信。
整理不易,欢迎一键三连!!!
送你们一条美丽的--分割线--
🌷🌷🍀🍀🌾🌾🍓🍓🍂🍂🙋🙋🐸🐸🙋🙋💖💖🍌🍌🔔🔔🍉🍉🍭🍭🍋🍋🍇🍇🏆🏆📸📸⛵⛵⭐⭐🍎🍎👍👍🌷🌷


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











