






 本文深入探讨了多种排序算法,包括遗忘比较交换算法、0-1排序引理、列排序、比较网络、排序网络、奇偶排序、双调排序及奇偶移项排序。详细介绍了每种算法的工作原理、实现方式及其在不同场景下的应用。
本文深入探讨了多种排序算法,包括遗忘比较交换算法、0-1排序引理、列排序、比较网络、排序网络、奇偶排序、双调排序及奇偶移项排序。详细介绍了每种算法的工作原理、实现方式及其在不同场景下的应用。
目录
一,遗忘比较交换算法
出自算法导论:
遗忘比较交换算法是指算法只按照事先定义好的操作执行,即需要比较的位置下标必须事先确定好。
虽然算法可能依靠待排序元素的个数,但它不能依靠待排序元素的值,也不能依赖任何之前的比较交换操作的结果。
在排序算法一文中有提到,插入排序、选择排序、冒泡排序、归并排序、堆排序、快速排序、希尔排序都是基于比较的排序,而这里面,冒泡排序是遗忘比较,希尔排序是嵌套了其他排序算法的,如果嵌套了遗忘比较算法,那么整个希尔排序也是遗忘比较算法,另外几个都不是遗忘比较算法。
二,0-1排序引理
0-1排序引理:如果一个遗忘比较交换算法能够对所有只包含0和1的输入序列排序,那么它也可以对包含任意值的输入序列排序。
三,列排序


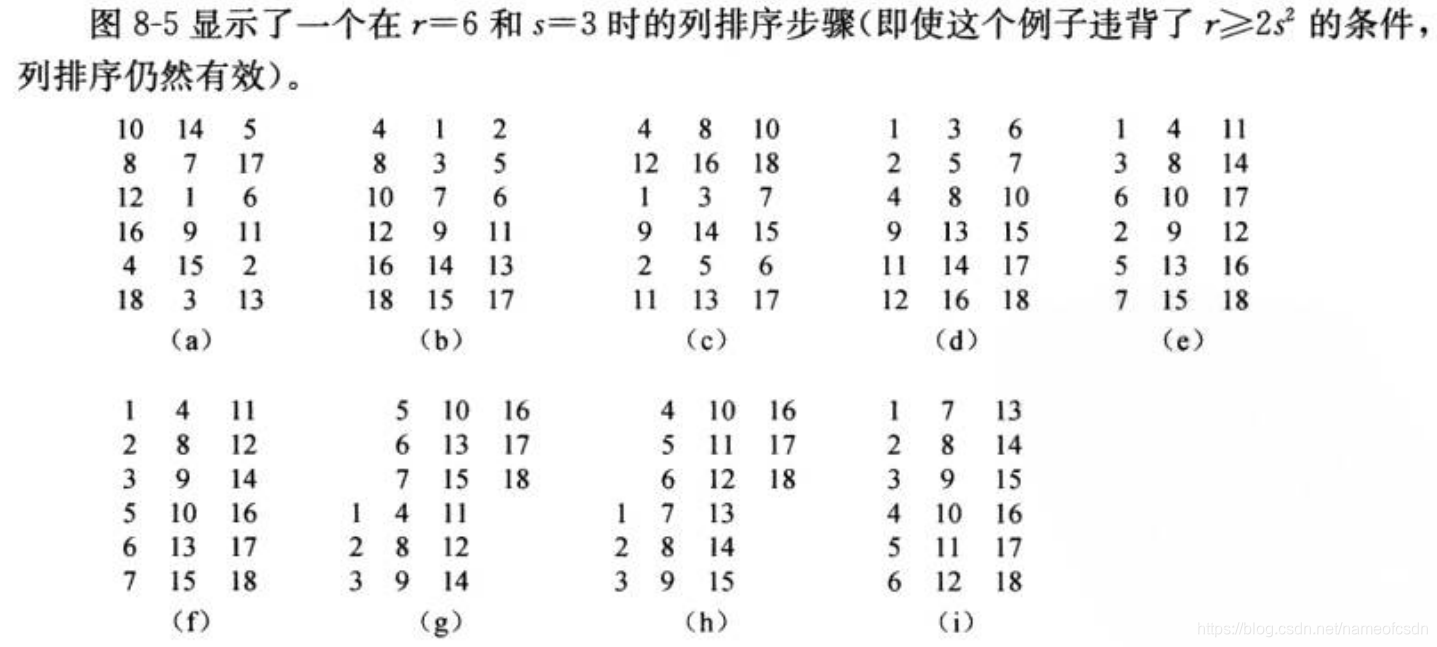
即使不知道奇数步中,对每一列的排序采取的是什么排序算法,我们仍然可以认为,列排序算法是遗忘比较交换算法。
书中后面有提示,如何根据0-1排序引理证明上述八步操作可以完成排序,不难,略。
以s=5为例,我们把数组的长度补到50的倍数x(x>=250),那么r=x/5,r>=50,即满足条件,排序完成之后再把多余的元素删掉即可。
代码:
template<typename T>
void Sort(T* arr, int len, bool(*cmp)(T a, T b))
{
if (len < 250 || len % 50) {
int b = max(len / 50, 5);
int len2 = b * 50;
T m = GetMax(arr, len);
T* p = new T[len2];
for (int i = 0; i < len; i++)p[i] = arr[i];
for (int i = len; i < len2; i++)p[i] = m;
Sort(p, len2, cmp);
for (int i = 0; i < len; i++)arr[i] = p[i];
return;
}
const int s = 5;
int r = len / s; //r行s列
T* p = new T[len];
for (int i = 0; i < len; i += r)Sort2(arr + i, r, cmp);//每一列排序
for (int i = 0; i < len; i++) p[i / s + i % s * r] = arr[i];//转置
for (int i = 0; i < len; i += r)Sort2(p + i, r, cmp);//每一列排序
for (int i = 0; i < len; i++) arr[i] = p[i / s + i % s * r];//逆转置
for (int i = 0; i < len; i += r)Sort2(arr + i, r, cmp);//每一列排序
for (int i = r / 2; i < len - r; i += r)Sort2(arr + i, r, cmp);//最后一次排序
}其中的sort2是调用别的排序算法,比如插入排序。
相关代码和接口定义参见 排序算法,下同。
四,比较网络
来自 OI之外的一些东西:简单谈谈排序网络 | Matrix67: The Aha Moments
1,比较算子
对于一个数列{ai},任取2个数ai和aj,比较大小并(可能)交换位置,使得ai<=aj成立,这样的一个操作叫比较算子。
PS:可以理解为这是递增比较算子,对应的还有一个递减比较算子。
2,比较网络
一系列有序的比较算子,构成一个比较网络。
例如下面是4个比较算子构成的网络:
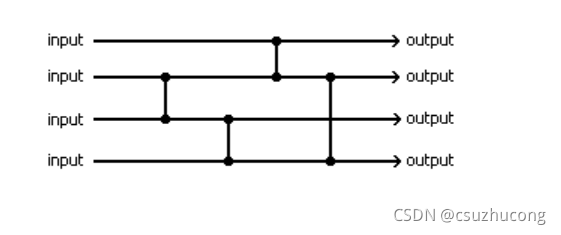
一般的比较网络,所有的算子都是一个方向的,即要么都是递增算子要么都是递减算子,所以用图表示比较网络可以省略方向。
而对于既有递增算子又有递减算子的网络,需要用带箭头的线表示。
3,比较网络的可并行性
以上面的网络为例,中间的2个比较算子,如果改变先后顺序,或者说同时操作,显然整个网络的结果是一样的。
更一般地,如果把一个比较网络的若干比较算子的顺序交换,使得对于任意下标i,涉及到第i个元素的所有比较算子之间的前后顺序不变,那么整个网络就和原网络等价。
PS:这是我的推理,没有严格的论证。
五,排序网络
1,排序网络
如果一个比较网络对于任何输入数列,输出的都是有序数列,那么称这个比较网络为排序网络。
上面的比较网络不是排序网络,如输入3 1 4 2输出的是1 3 2 4,不是有序的。
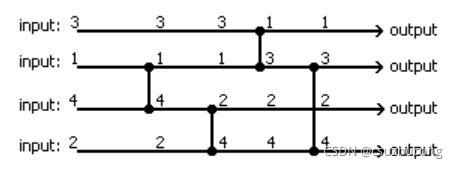
2,排序网络的判定
排序网络和遗忘比较交换算法是对应的。
所以判定一个比较网络是不是排序网络,可以用0-1排序引理。
即如果一个比较网络能够对所有只包含0和1的输入序列排序,那么它就是排序网络。
3,冒泡排序的排序网络
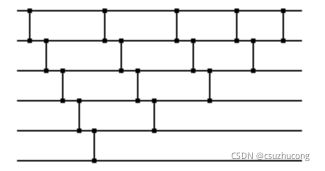
可以调整为:
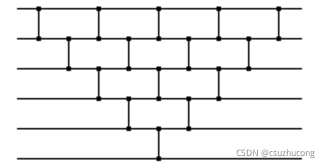
这样,就可以提高并行程度,加快速度。
4,希尔排序的排序网络
六,奇偶排序
1,奇偶排序网络
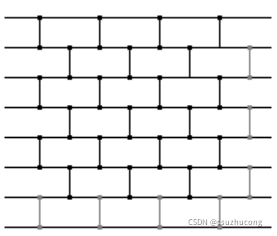
不带浅色的是7个元素的排序网络,带浅色的是8个元素的排序网络。
排序网络一目了然,算法步骤就不用描述了。
matrix67的博文中用0-1排序引理和数学归纳法证明了此算法的正确性。
2,实现
template<typename T>
void Sort(T* arr, int len, bool(*cmp)(T a, T b))
{
for (int i = 0; i < len; i++) {
for (int j = i % 2; j + 1 < len; j += 2) {
if (cmp(arr[j + 1], arr[j]))exchange(arr + j, arr + j + 1);
}
}
}七,双调排序
双调就是单峰的意思。
1,双调排序网络
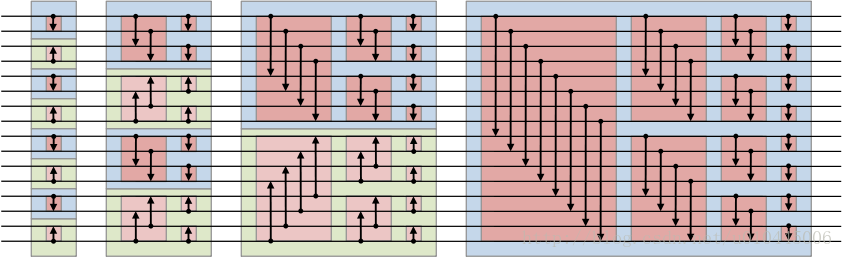
算法可以分为三块:
左上就是一个排序,和整个图是一样的。
左下和左上是对称的,也就是说,经过左边2个步骤之后,整个数列是单峰的。
右边的是把一个单峰数列变成一个有序数列。
2,实现
对于长度不是2的幂的数列,需要补齐长度。
template<typename T>
bool cmp2(T a, T b, int dir)
{
if (dir == 0)return cmp(a, b);
else return cmp(b, a);
}
template<typename T>
void Sort(T* arr, int len, bool(*cmp)(T a, T b), int dir) // dir: 0 默认cmp 1 相反顺序
{
if (len <= 1)return;
Sort(arr, len / 2, cmp, dir);
Sort(arr + len / 2, len / 2, cmp, 1 - dir);
for (int k = 1; k < len; k *= 2) {
int d = len / k;
for (int s = 0; s < len; s += d) {
for (int i = s; i < s + d / 2; i++)
if (cmp2(arr[i + d / 2], arr[i], dir))exchange(arr + i + d / 2, arr + i);
}
}
}
template<typename T>
void Sort(T* arr, int len, bool(*cmp)(T a, T b))
{
int maxLen = 1;
while (maxLen < len)maxLen *= 2;
T* arr2 = new T[maxLen];
T m = GetMax(arr, len);
for (int i = 0; i < len; i++)arr2[i] = arr[i];
for (int i = len; i < maxLen; i++)arr2[i] = m;
Sort(arr2, maxLen, cmp, 0);
for (int i = 0; i < len; i++)arr[i] = arr2[i];
delete[]arr2;
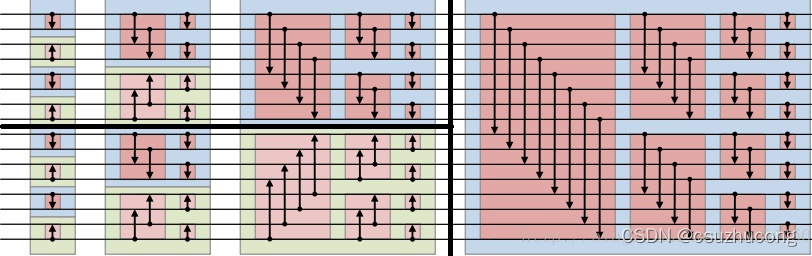
}3,等价形式
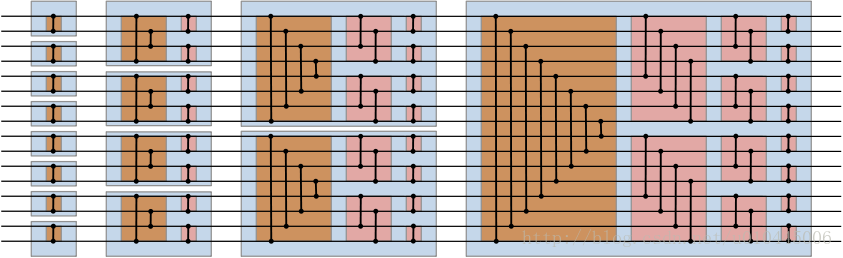
相当于把上面的网络的左下部分翻转一下,经过递归就得到方向一致的网络。
实现:
template<typename T>
void Sort2(T* arr, int len, bool(*cmp)(T a, T b))
{
if (len <= 1)return;
Sort2(arr, len / 2, cmp);
Sort2(arr + len / 2, len / 2, cmp);
for (int i = 0, j = len - 1; i < j; i++, j--) {
if (cmp(arr[j], arr[i]))exchange(arr + j, arr + i);
}
for (int k = 2; k < len; k *= 2) {
int d = len / k;
for (int s = 0; s < len; s += d) {
for (int i = s; i < s + d / 2; i++)
if (cmp(arr[i + d / 2], arr[i]))exchange(arr + i + d / 2, arr + i);
}
}
}
template<typename T>
void Sort(T* arr, int len, bool(*cmp)(T a, T b))
{
int maxLen = 1;
while (maxLen < len)maxLen *= 2;
T* arr2 = new T[maxLen];
T m = GetMax(arr, len);
for (int i = 0; i < len; i++)arr2[i] = arr[i];
for (int i = len; i < maxLen; i++)arr2[i] = m;
Sort2(arr2, maxLen, cmp);
for (int i = 0; i < len; i++)arr[i] = arr2[i];
delete[]arr2;
}八,奇偶移项排序
1,算法思路
奇偶移项排序和归并排序类似,差别在于合并过程是遗忘算法,所以整个排序是遗忘算法。
奇偶移项排序和双调排序一样,首先补齐元素,使得元素个数是2的幂,然后前面一半和后面一半递归排序,最后进行合并。
合并过程也是一个递归的过程,首先合并所有的奇数项,然后合并所有的偶数项,最后把所有的偶数项(除了最后一个)和它下一项比较交换,这样就完成了合并。
整个排序的时间复杂度是 O(n*logn*logn)
2,排序网络
以n=8为例:
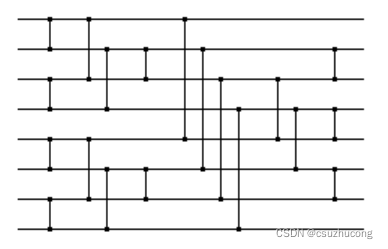
3,实现
template<typename T>
void Merge(T* arr, int len, int d, bool(*cmp)(T a, T b))
{
if (d >= len / 2) {
if (cmp(arr[d], arr[0]))exchange(arr + d, arr);
return;
}
Merge(arr, len, d * 2, cmp);
Merge(arr + d, len - d, d * 2, cmp);
for (int i = d; i < len - d; i += d * 2) {
if (cmp(arr[i + d], arr[i]))exchange(arr + i + d, arr + i);
}
}
template<typename T>
void Sort2(T* arr, int len, bool(*cmp)(T a, T b))
{
if (len <= 1)return;
Sort2(arr, len / 2, cmp);
Sort2(arr + len / 2, len / 2, cmp);
Merge(arr, len, 1, cmp);
}

















 2348
2348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









