







目录
前言
这篇文章是我根据 B 站 霹雳吧啦Wz 的《深度学习:语义分割篇章》中的 DeepLabV3 网络简介(语义分割)所作的学习笔记,涵盖内容如目录所示,希望能为正在学习语义分割的小伙伴们提供一些帮助ヾ(^▽^*))) 因为才刚刚开始接触语义分割,所以在表达上可能比较幼稚,希望王子公主们多多包涵啦!如果存在问题的话,请大家直接指出噢~
- 在做笔记的过程中,我还参考了这篇博客:DeepLabV3网络简析_deeplabv3网络结构-CSDN博客
- 在做笔记的过程中,我还参考了这篇博客:语义分割学习笔记 P8-CSDN博客
Preparation
相关论文:Rethinking Atrous Convolution for Semantic Image Segmentation
相较于 DeepLab V2 ,DeepLab V3 存在以下区别:
- 引入 Multi-Grid
- 改进 ASPP 结构
- 移除 CRFs 后处理
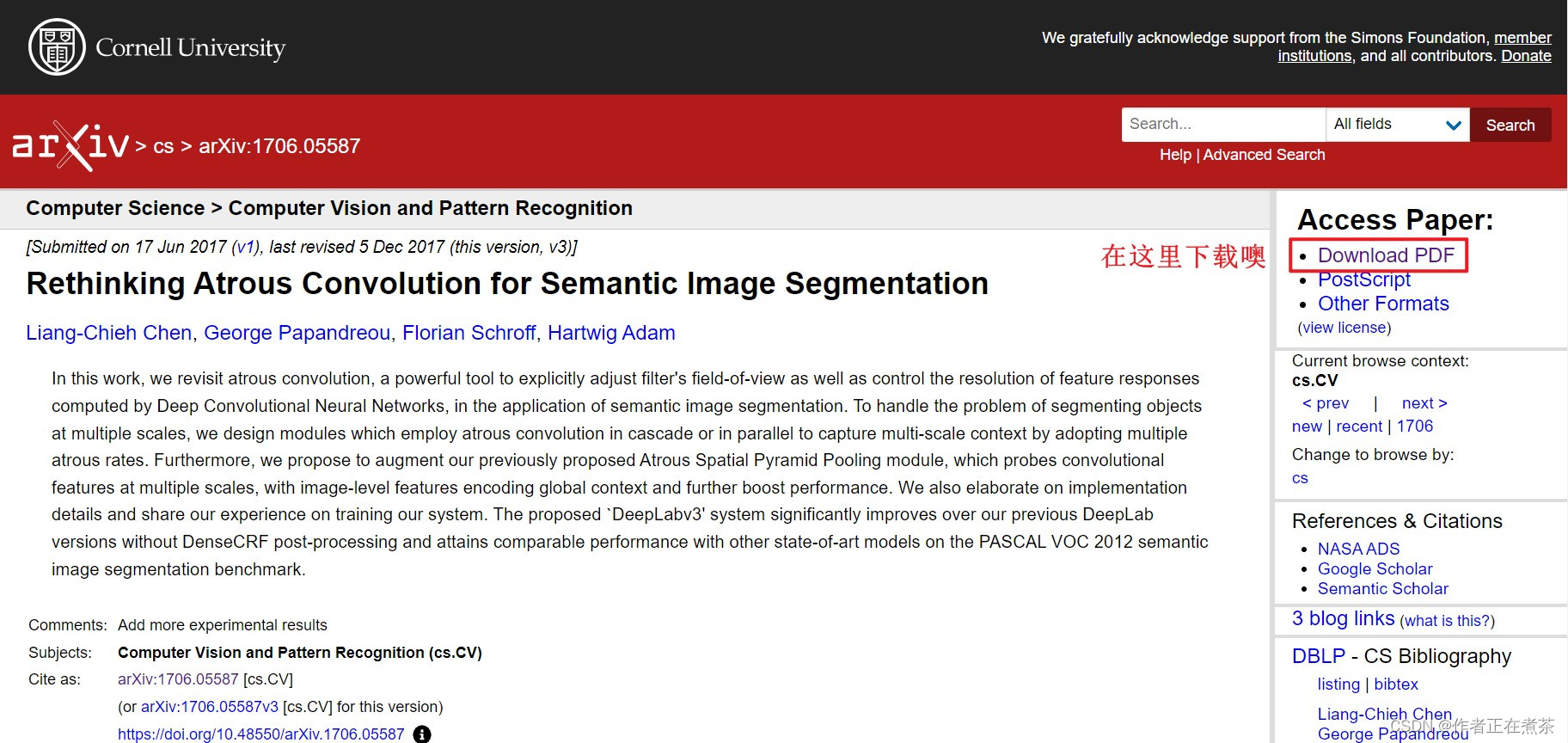
关于获取多尺度范围信息的可选结构:
- Image Pyramid :将图片缩放到不同的尺度,然后分别输入到网络中进行正向推理,再融合多个尺度的输出得到最终输出。
- Encoder-Decoder :按照分类网络 backbone 进行一系列下采样,将最后的特征层进行上采样,再和浅层的特征层做融合,再进行上采样,然后再融合,以此类推,直到还原至原图的尺寸。
- Deeper w. Atrous Convolution :将分类网络中的最后几个下采样层的步距设置为 1 ,再引入膨胀卷积来增大网络的感受野。
- Spatial Pyramid Pooling :引入 ASPP 结构,增加模型获取多尺度上下文的能力。
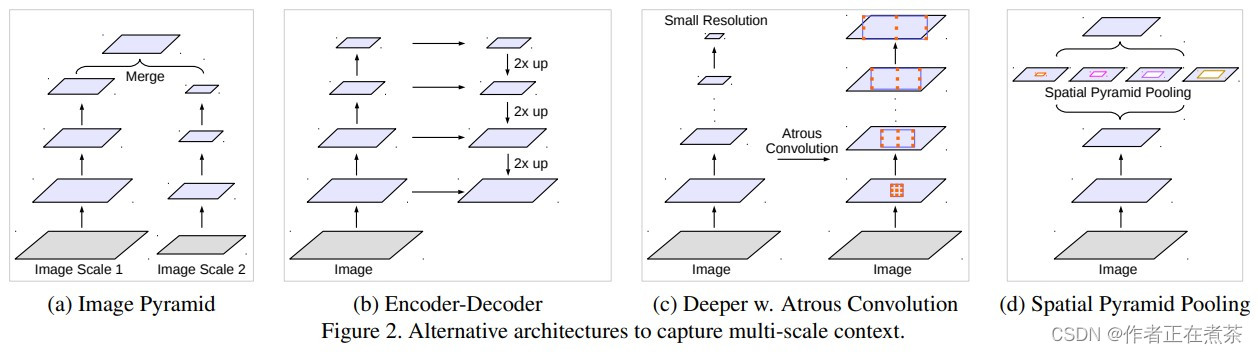
一、DeepLab V3 两种模型结构
这篇论文给出了 DeepLab V3 的两种模型结构,分别为 cascaded model 和 ASPP model ,在 cascaded model 中未使用 ASPP 模块,在 ASPP model 中未使用 cascaded blocks 模块。原论文作者认为 ASPP model 比 cascaded model 较好些。
1、cascaded model 模型结构
这篇论文提出的 cascaded model 如下图 (b) 所示,其中的 Block1~Block4 都是原始 ResNet 网络中的层结构,但在 Block4 中将第一个残差结构里的 3 x 3 卷积层以及捷径分支上的 1 x 1 卷积层的步距 stride 由 2 改为了 1 ,不再进行下采样操作,并且所有残差结构里的 3 x 3 的普通卷积层都换成了膨胀卷积层。而 Block5~Block7 是额外新增的层结构,同 Block4 相同,也是由三个残差结构构成的。
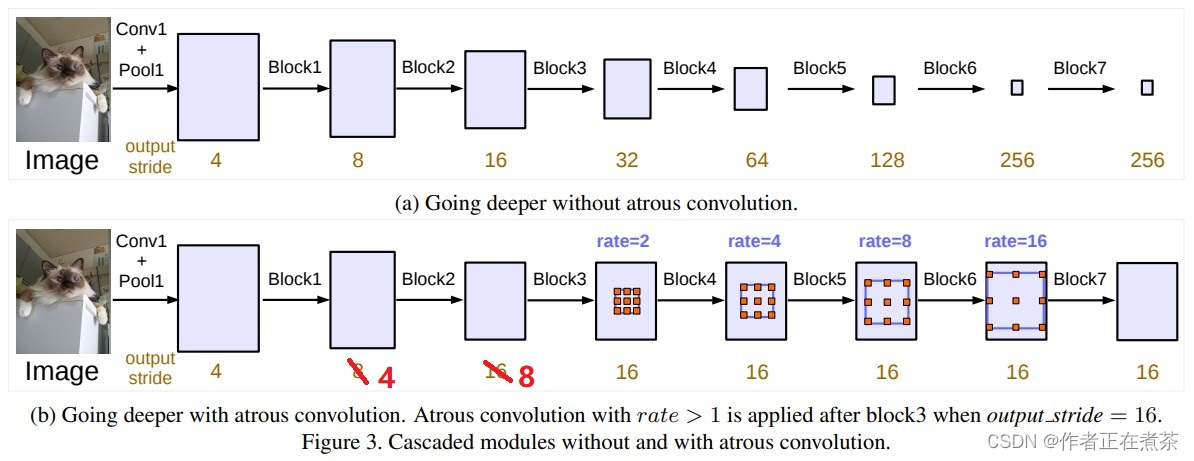
【说明】原论文提到 训练 cascaded model 时 output_stride = 16 (特征层相对输入图片的下采样率),但 验证 时 output_stride = 8 ,因为 output_stride = 8 得到的最终特征图的宽高更小,这意味着可以设置更大的 batch_size 并加快训练速度。但特征层的宽高变小会导致特征层的细节信息丢失,所以验证时采用 output_stride = 8 。当 GPU 显存足够时,可以直接将 output_stride 设置成 8 。
【注意】图中的 rate 并不是膨胀卷积真正采用的膨胀系数,真正采用的膨胀系数是 rate 乘 multi-grid 参数(后面会具体说)。
2、ASPP model 模型结构
这篇论文提出的 ASPP model 如下图所示,同样,原论文提到 训练 时 output_stride = 16 (特征层相对输入图片的下采样率),但 验证 时 output_stride = 8 。但在 PyTorch 官方实现的 DeepLab V3 源码中直接将 output_stride 设置成 8 来进行训练。
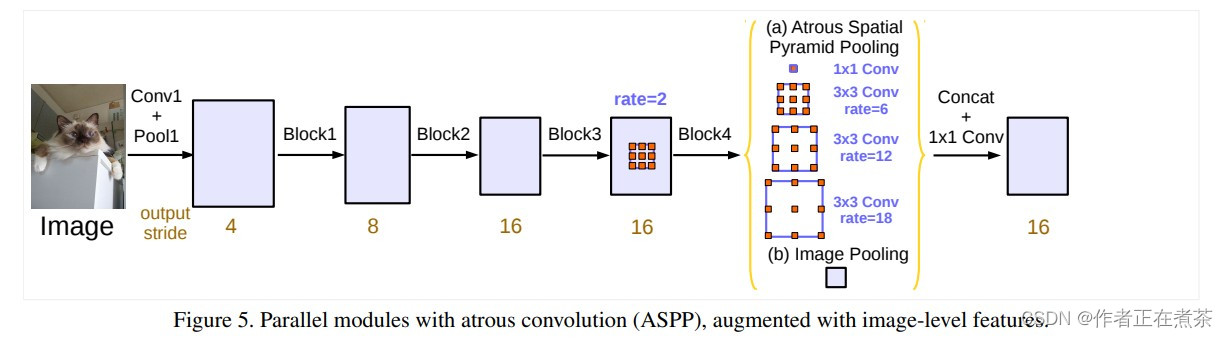
【说明】上图中的 (b) 是 Image Pooling 全局池化层,用于获取全局信息。后面的融合是先通过 Concat 拼接,再通过 1 x 1 的卷积层。
(1)DeepLab V2 中的 ASPP 结构
DeepLab V2 中的 ASPP 结构:通过四个并行的膨胀卷积层,每个分支上的膨胀卷积层所采用的膨胀系数不同,最后通过 add 相加的方式将四个分支上的输出进行融合。
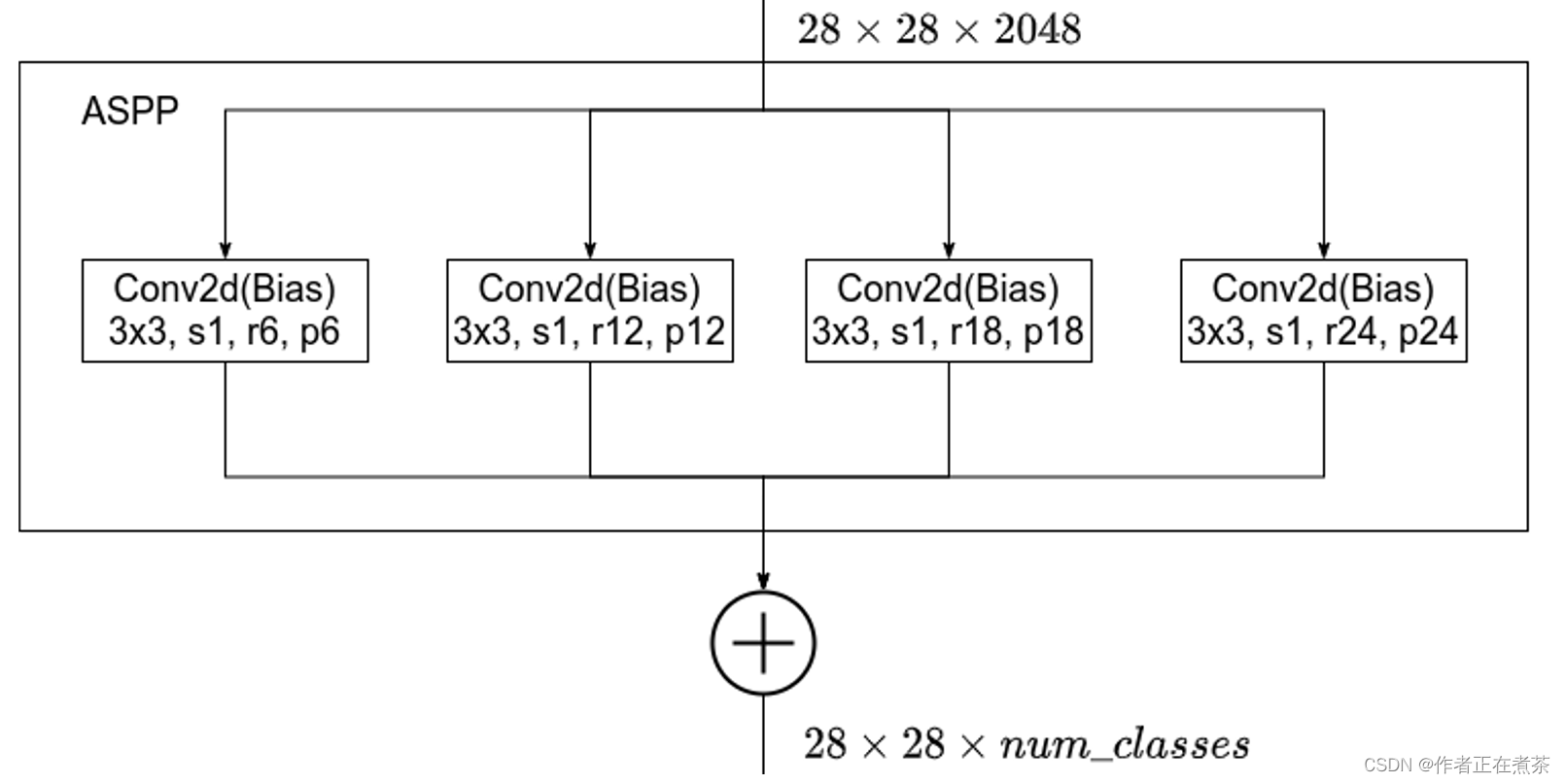
【注意】这里的膨胀卷积层后没有接 BatchNorm 层,并且还使用了 Bias 偏执。
(2)DeepLab V3 中的 ASPP 结构
DeepLab V3 中的 ASPP 结构:通过五个并行分支,分别为一个 1 x 1 的普通卷积层,三个 3 x 3 的膨胀卷积层,以及一个 全局平均池化层 。这五个分支输出特征图的宽高相同,在 channel 方向用 Concat 方式进行拼接,再经过一个 1 x 1 的卷积进行进一步的融合。
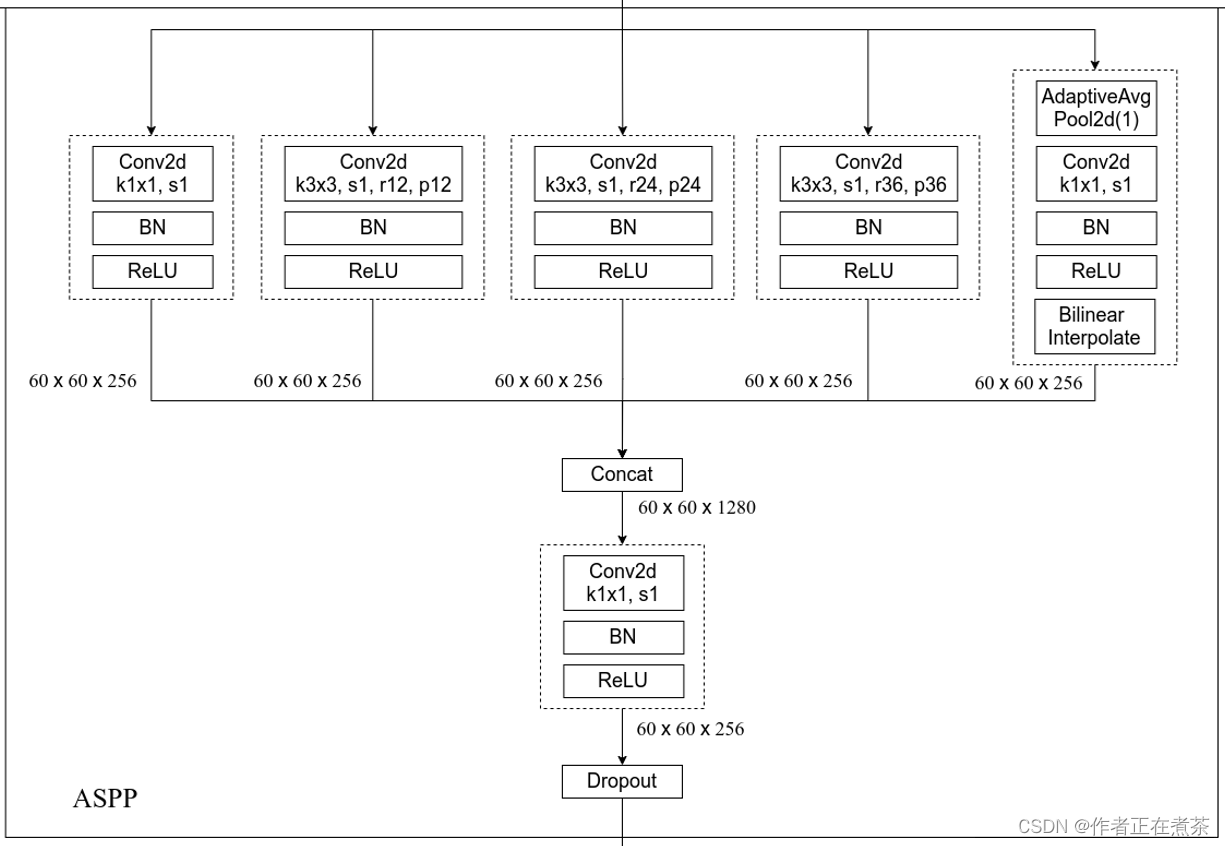
【注意】当下采样率为 8 时,膨胀系数需要进行 翻倍处理 ,因此上图中膨胀卷积的膨胀系数分别为 12 、24 和 36 。
【补充】在最后一个分支中,先经过全局平均池化层,将其池化成 1 x 1 的大小,再经过 1 x 1 的卷积层调整其 channel ,最后通过双线性插值法将其还原回输入特征图的宽高。原论文作者提出全局平均池化层的作用为:增加全局上下文信息 global context information 。
二、Multi-Grid
在之前讲过的 DeepLab V1 和 DeepLab V2 模型中,虽然也使用了膨胀卷积,但设置的膨胀系数都比较随意。
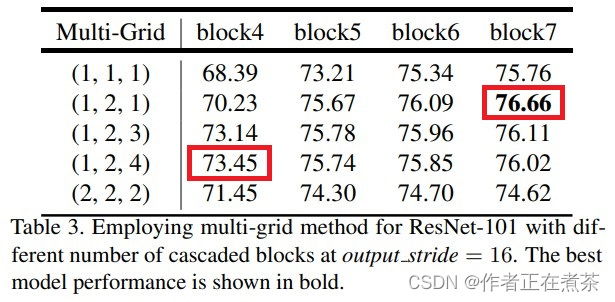
在 DeepLab V3 模型中,以 cascaded model 为实验对象,backbone 采用 ResNet101 网络,研究采用不同数量的 cascaded blocks 模型以及 cascaded blocks 采用不同的 Multi-Grid 参数的效果。上文提到过,cascaded model 的 blocks 中真正采用的膨胀系数是 rate 乘上 Multi-Grid 参数。通过实验发现,当采用额外的 Block5~Block7 并将 Multi-Grid 设置为 (1, 2, 1) 时效果最好。
另外,在 DeepLab V3 模型中,以 ASPP model 为实验对象时,未添加任何额外 Block ,当 Multi-Grid 设置为 (1, 2, 4) 时效果最好。
三、消融实验
1、cascaded model 消融实验
这张表是有关 cascaded model 的消融实验:
- MG :Multi-Grid ,上文已经提到 cascaded model 中采用 MG(1, 2, 1) 的效果最佳。
- OS :output_stride ,上文已经提到 cascaded model 验证时将 output_stride 设置为 8 的效果更佳。
- MS :多尺度,和 DeepLab V2 中类似,但在 DeepLab V3 中采用的尺度更多 scales = { 0.5, 0.75, 1.0, 1.25, 1.5, 1.75 } 。
- Flip :增加一个水平翻转后的图像输入。

2、ASPP model 消融实验
这张表是有关 cascaded model 的消融实验:
- MG :Multi-Grid ,上文已经提到 ASPP model 中采用 MG(1, 2, 4) 的效果最佳。
- ASPP :Atrous spatial pyramid pooling ,空洞空间卷积池化金字塔。
- Image Pooling :在 ASPP 中加入全局平均池化层分支。
- OS :output_stride ,上文已经提到 ASPP model 验证时将 output_stride 设置为 8 的效果更佳。
- MS :多尺度,和 DeepLab V2 中类似,但在 DeepLab V3 中采用的尺度更多 scales = { 0.5, 0.75, 1.0, 1.25, 1.5, 1.75 } 。
- Flip :增加一个水平翻转后的图像输入。
- COCO :在 MS-COCO 数据集上进行预训练。

四、训练细节
New training protocol: As mentioned in the main paper,we change the training protocol in [10, 11] with three maindifferences: (1) larger crop size, (2) upsampling logits duringtraining, and (3) fine-tuning batch normalization.
原论文提供了 DeepLab V3 在 PASCAL VOC 2012 测试数据集上不同网络模型的 mean IoU :
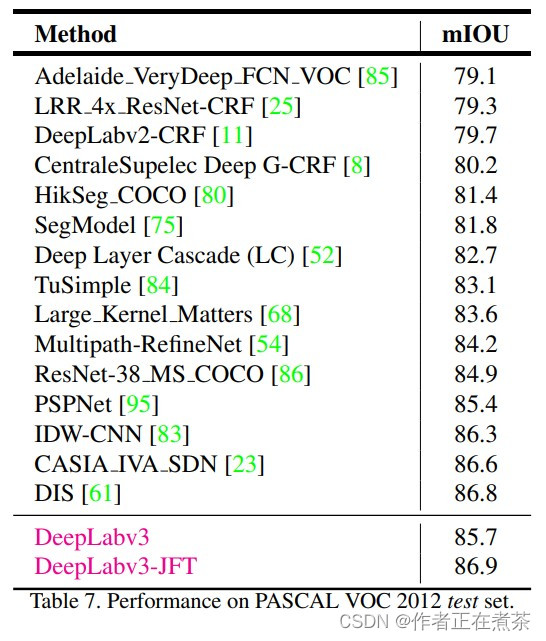
通过这张表可知,DeepLabv3 较 DeepLabv2-CRF 提升了 mean IoU 大约 6 个点,尽管这里未具体说明使用的是 cascaded model 还是 ASPP model ,但大概率是 ASPP model 。而之所以可以提升 6 个点,不仅是因为引入了 Multi-Grid 参数,还应该在训练过程中作出了其他改动,具体可查看论文中的 A. Effect of hyper-parameters 部分,训练策略中存在以下三个主要的不同点:
- 采用更大的 crop size,在训练过程中增大输入图片的尺寸,值得注意的是,当采用大的膨胀系数时,输入图片的尺寸不应太小,否则 3 x 3 的膨胀卷积可能退化成 1 x 1 的普通卷积。
- 将预测的结果通过双线性插值法上采样 8 倍还原回原图尺度后,再和真实标签图像计算损失,这样可以加快训练速度,减少所需的显存。之前在 DeepLab V1 - V2 中将真实标签图像下采样 8 倍后再和没有进行上采样的预测结果计算损失。
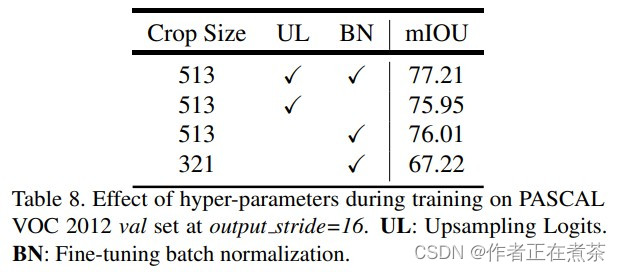
- 在训练结束后冻结 BN 层,再 fine-turn 其他参数。根据下面这张表可知,能够提升一个点。
五、PyTorch 官方实现 DeepLab V3
这张图是霹雳吧啦根据 PyTorch 官方实现的 DeepLab V3 源码绘制的网络结构图,与原论文的描述有所差异:
- 没有使用 Multi-Grid 。
- 多了一个 FCN Head 辅助训练分支,可以选择不使用。
- 无论是训练还是验证,output_stride 都使用的是 8 。
- ASPP 中三个膨胀卷积分支的膨胀系数是 12、24 和 36 ,因为原论文说 output_stride 为 8 时膨胀系数要翻倍。

【说明】在上面这张网络结构图中,backbone 采用的是 ResNet50 网络,其 Layer1~Layer5 对应 Block1~Block5 ,其中,从 7 x 7 卷积层到 Layer 2 都是和 ResNet 网络一样的。而在 ResNet 网络中,Layer3 的 Bottleneck1 是需要进行下采样操作的,但是之前提到过 PyTorch 官方在训练过程中直接将 output_stride 设置为 8 ,而在前面的卷积层、Layer1 、Layer2 中都已经各自下采样了 2 倍,即在通过 Layer2 后就已经下采样了 8 倍,因此在 Bottleneck1 这里没必要再进行下采样啦!故而将 stride 都设置为 1 了。除此之外,因为在 Layer3 中将 Bottleneck1 的膨胀系数设置为 1 ,因此那个 3 x 3 卷积就是普通卷积。DeepLab Head 中最后一个卷积的卷积核大小为分类类别个数 num_classes 。
















 444
444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











