







前言
文章性质:学习笔记 📖
学习资料:吴茂贵《 Python 深度学习基于 PyTorch ( 第 2 版 ) 》【ISBN】978-7-111-71880-2
主要内容:根据学习资料撰写的学习笔记,该篇主要介绍了如何使用 PyTorch 实现 Transformer 。
目录
一、使用 PyTorch 实现 Transformer
Transformer 的原理在前面已经分析得较为详细,本文重点介绍如何使用 PyTorch 来实现。我们将使用 PyTorch 1.0+ 版本完整实现 Transformer 架构,并用简单实例进行验证。本文代码参考了哈佛大学 OpenNMT 团队针对 Transformer 实现的代码。该代码是用 PyTorch 0.3.0 实现的,代码地址为:The Annotated Transformer 。
1、构建完整网络
把前面创建的各网络层整合成一个完整网络。具体代码如下:
def make_model(src_vocab,tgt_vocab,N=6,d_model=512, d_ff=2048, h=8, dropout=0.1):
" 构建模型 "
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab))
# 随机初始化参数,这非常重要用 Glorot/fan_avg.
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model首先把 copy.deepcopy 命名为 c ,这样可以使下面的代码简洁些。
然后构造 MultiHeadedAttention 、PositionwiseFeedForward 和 PositionalEncoding 对象。
接着构造 EncoderDecoder 对象,需要 5 个参数:Encoder、Decoder、src-embed、tgt-embed 和 Generator 。
我们先看后面三个简单的参数,Generator 直接构造即可,它的作用是把模型的隐含单元变成输出词的概率。
而 src-embed 是一个嵌入 Embeddings 层和一个位置编码层,tgt-embed 也与此类似。
由于 Encoder 和 Decoder 类似,我们看 Decoder 即可。
解码器 Decoder 由 N 个 DecoderLayer 组成,DecoderLayer 需要传入 self-attn 、src-attn 、全连接层、Dropout 。
因为所有的 MultiHeadedAttention 都是一样的,因此我们直接深度复制 deepcopy 即可。
同理,所有的 PositionwiseFeedForward 的结果也是一样的,我们可以深度复制 deepcopy 而不需要再构造一个。
实例化这个类,可以看到模型包含哪些组件。
# 测试一个简单模型,输入、目标语句长度分别为 10 ,Encoder、Decoder 各 2 层。
tmp_model = make_model(10, 10, 2)
tmp_model2、训练模型
① 训练前,先介绍便于批次训练的一个 Batch 类。
class Batch:
" 在训练其间,构建带有掩码的批量数据 "
def __init__(self, src, trg=None, pad=0):
self.src = src
self.src_mask = (src != pad).unsqueeze(-2)
if trg is not None:
self.trg = trg[:, :-1]
self.trg_y = trg[:, 1:]
self.trg_mask = \
self.make_std_mask(self.trg, pad)
self.ntokens = (self.trg_y != pad).data.sum()
@staticmethod
def make_std_mask(tgt, pad):
" Create a mask to hide padding and future words. "
tgt_mask = (tgt != pad).unsqueeze(-2)
tgt_mask = tgt_mask & subsequent_mask(tgt.size(-1)).type_as(tgt_mask.data).clone().detach()
return tgt_maskBatch 构造函数的输入是 src 、trg 和 pad ,其中 trg 的默认值为 None ,刚预测的时候是没有 tgt 的。上述代码是训练阶段的一个 Batch 代码,它假设 src 的维度为 (40, 20) ,其中 40 是批量大小,而 20 是最长的句子长度,如果句子不够长,则填充为 20 。而 trg 的维度为 (40, 25) ,表示翻译后最长的句子长度是 25 ,不足的需要填充对齐。
那么 src_mask 如何实现呢?
注意表达式 ( src != pad ) 中把 src 中大于 0 的时刻置为 1 ,这样表示它已在关注的范围。
然后 unsqueeze(-2) 把 src_mask 变成 (40/batch, 1, 20/time) 。它的用法可以参考前面的 attention 函数。
对于训练来说,Decoder 有一个输入和一个输出。
比如句子 “ it is a good day ”,输入会变成 “ it is a good day ”,而输出为 “ it is a good day ”。
对应到代码里,self.trg 就是输入,而 self.trg_y 就是输出。
接着对输入 self.trg 进行掩码,使得自注意力不能访问未来的输入。这是通过 make_std_mask 函数实现的。
这个 make_std_mask 函数会调用之前详细介绍过的 subsequent_mask 函数。
最终得到的 trg_mask 的 shape 是 (40/batch, 24, 24) ,表示 24 个时刻的掩码矩阵,这是一个对角线以及之下都是 1 的矩阵。
注意,src_mask 的 shape 是 (batch, 1, time) ,而 trg_mask 是 (batch, time, time) 。
因为 src_mask 的每一个时刻都能关注所有时刻(填充的除外),一次只需要一个向量即可,而 trg_mask 需要一个矩阵。
② 构建训练迭代函数。
def run_epoch(data_iter, model, loss_compute):
" Standard Training and Logging Function "
start = time.time()
total_tokens = 0
total_loss = 0
tokens = 0
for i, batch in enumerate(data_iter):
out = model.forward(batch.src, batch.trg, batch.src_mask, batch.trg_mask)
loss = loss_compute(out, batch.trg_y, batch.ntokens)
total_loss += loss
total_tokens += batch.ntokens
tokens += batch.ntokens
if i % 50 == 1:
elapsed = time.time() - start
print("Epoch Step: %d Loss: %f Tokens per Sec: %f" %
(i, loss / batch.ntokens, tokens / elapsed))
start = time.time()
tokens = 0
return total_loss / total_tokens它遍历一个 epoch 的数据,然后调用 forward 函数,接着调用 loss_compute 函数计算梯度,更新参数并且返回 loss 。
3)对数据进行批量处理。
global max_src_in_batch, max_tgt_in_batch
def batch_size_fn(new, count, sofar):
" Keep augmenting batch and calculate total number of tokens + padding. "
global max_src_in_batch, max_tgt_in_batch
if count == 1:
max_src_in_batch = 0
max_tgt_in_batch = 0
max_src_in_batch = max(max_src_in_batch, len(new.src))
max_tgt_in_batch = max(max_tgt_in_batch, len(new.trg) + 2)
src_elements = count * max_src_in_batch
tgt_elements = count * max_tgt_in_batch
return max(src_elements, tgt_elements)④ 定义优化器。
class NoamOpt:
" 包括优化学习率的优化器 "
def __init__(self, model_size, factor, warmup, optimizer):
self.optimizer = optimizer
self._step = 0
self.warmup = warmup
self.factor = factor
self.model_size = model_size
self._rate = 0
def step(self):
" 更新参数及学习率 "
self._step += 1
rate = self.rate()
for p in self.optimizer.param_groups:
p['lr'] = rate
self._rate = rate
self.optimizer.step()
def rate(self, step = None):
" Implement `lrate` above "
if step is None:
step = self._step
return self.factor * \
(self.model_size ** (-0.5) *
min(step ** (-0.5), step * self.warmup ** (-1.5)))
def get_std_opt(model):
return NoamOpt(model.src_embed[0].d_model, 2, 4000,
torch.optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9))⑤ 可视化在不同场景下学习率的变化情况。
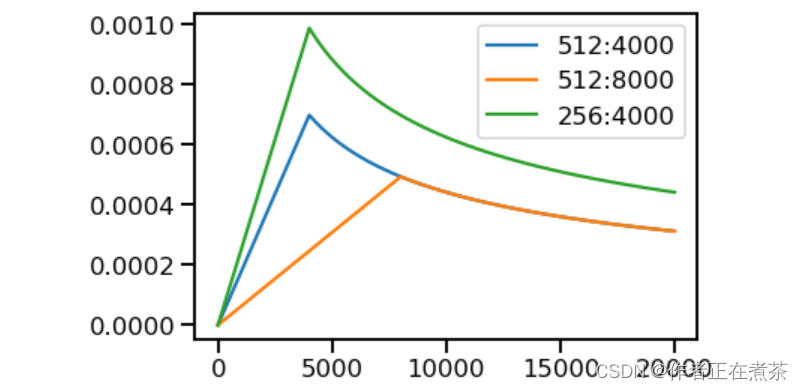
# 超参数学习率 3 个场景
opts = [NoamOpt(512, 1, 4000, None),
NoamOpt(512, 1, 8000, None),
NoamOpt(256, 1, 4000, None)]
plt.plot(np.arange(1, 20000), [[opt.rate(i) for opt in opts] for i in range(1, 20000)])
plt.legend(["512:4000", "512:8000", "256:4000"])运行结果如下图所示:
⑥ 正则化。对标签做正则化平滑处理,这样处理有利于提高模型的准确率和 BLEU 分数。
class LabelSmoothing(nn.Module):
" Implement label smoothing. "
def __init__(self, size, padding_idx, smoothing=0.0):
super(LabelSmoothing, self).__init__()
# self.criterion = nn.KLDivLoss(size_average=False)
self.criterion = nn.KLDivLoss(reduction='sum')
self.padding_idx = padding_idx
self.confidence = 1.0 - smoothing
self.smoothing = smoothing
self.size = size
self.true_dist = None
def forward(self, x, target):
assert x.size(1) == self.size
true_dist = x.data.clone()
true_dist.fill_(self.smoothing / (self.size - 2))
true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence)
true_dist[:, self.padding_idx] = 0
mask = torch.nonzero(target.data == self.padding_idx)
if mask.dim() > 0:
true_dist.index_fill_(0, mask.squeeze(), 0.0)
self.true_dist = true_dist
return self.criterion(x, true_dist.clone().detach())对标签进行平滑处理。
# Example of label smoothing.
crit = LabelSmoothing(5, 0, 0.4)
predict = torch.FloatTensor([[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0]])
v = crit(predict.log().clone().detach(), torch.LongTensor([2, 1, 0]).clone().detach())
# Show the target distributions expected by the system.
plt.imshow(crit.true_dist)运行结果如下图所示:
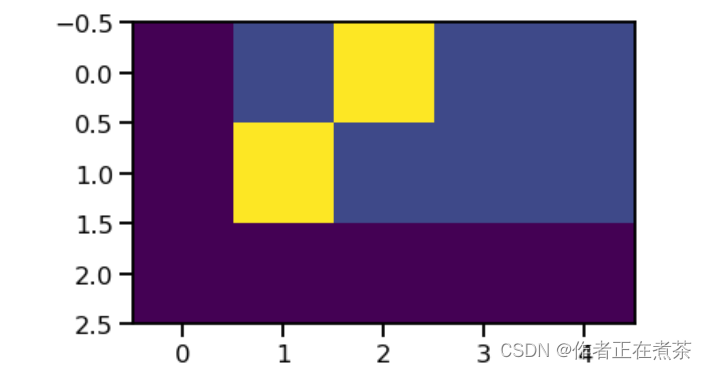
上面这张图可以看到如何基于置信度将质量分配给单词。
crit = LabelSmoothing(5, 0, 0.1)
def loss(x):
d = x + 3 * 1
predict = torch.FloatTensor([[0, x / d, 1 / d, 1 / d, 1 / d],])
# print(predict)
return crit(predict.log().clone().detach(),torch.LongTensor([1]).clone().detach()).item()
plt.plot(np.arange(1, 100), [loss(x) for x in range(1, 100)])运行结果如下图所示:
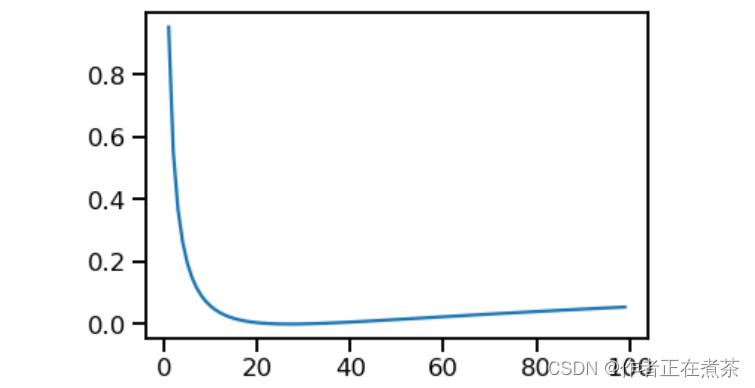
从上面这张图可以看出,如果标签平滑化对于给定的选择非常有信心,那么标签平滑处理实际上已经开始对模型造成不利影响。
3、实现一个简单实例
① 生成合成数据。
def data_gen(V, batch, nbatches):
" Generate random data for a src-tgt copy task. "
for i in range(nbatches):
# 把 torch.Embedding 的输入类型改为 LongTensor
data = torch.from_numpy(np.random.randint(1, V, size=(batch, 10))).long()
data[:, 0] = 1
src = data.clone().detach()
tgt = data.clone().detach()
yield Batch(src, tgt, 0)② 定义损失函数。
class SimpleLossCompute:
" 一个简单的计算损失的函数 "
def __init__(self, generator, criterion, opt=None):
self.generator = generator
self.criterion = criterion
self.opt = opt
def __call__(self, x, y, norm):
x = self.generator(x)
loss = self.criterion(x.contiguous().view(-1, x.size(-1)), y.contiguous().view(-1)) / norm
loss.backward()
if self.opt is not None:
self.opt.step()
self.opt.optimizer.zero_grad()
return loss.item() * norm③ 训练简单任务。
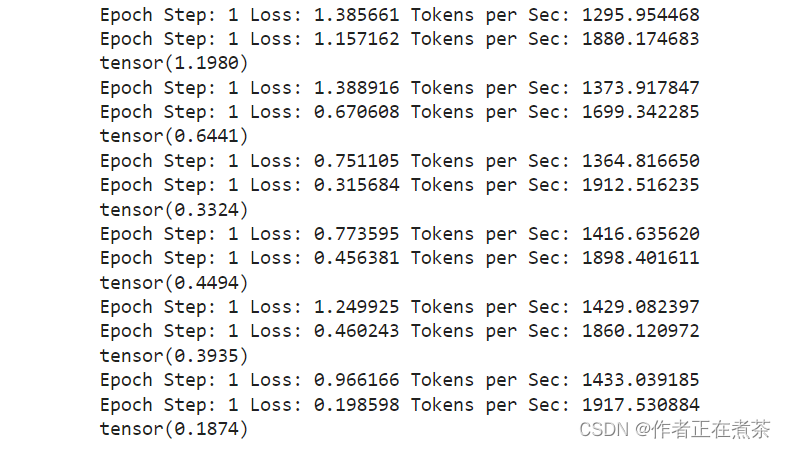
# Train the simple copy task.
V = 11
criterion = LabelSmoothing(size=V, padding_idx=0, smoothing=0.0)
model = make_model(V, V, N=2)
model_opt = NoamOpt(model.src_embed[0].d_model, 1, 400,
torch.optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9))
for epoch in range(10):
model.train()
run_epoch(data_gen(V, 30, 20), model,SimpleLossCompute(model.generator, criterion, model_opt))
model.eval()
print(run_epoch(data_gen(V, 30, 5), model,SimpleLossCompute(model.generator, criterion, None)))运行结果(最后几次迭代)如下:
④ 为了简单起见,此代码使用贪婪解码来预测翻译。
def greedy_decode(model, src, src_mask, max_len, start_symbol):
memory = model.encode(src, src_mask)
ys = torch.ones(1, 1).fill_(start_symbol).type_as(src.data)
for i in range(max_len-1):
# add torch.tensor 202005
out = model.decode(memory, src_mask,ys, subsequent_mask(torch.tensor(ys.size(1)).type_as(src.data)))
prob = model.generator(out[:, -1])
_, next_word = torch.max(prob, dim = 1)
next_word = next_word.data[0]
ys = torch.cat([ys, torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=1)
return ys
model.eval()
src = torch.LongTensor([[1,2,3,4,5,6,7,8,9,10]])
src_mask = torch.ones(1, 1, 10)
print(greedy_decode(model, src, src_mask, max_len=10, start_symbol=1))运行结果如下:
tensor([[ 1, 2, 3, 4, 4, 6, 7, 8, 9, 10]])第八章の小结
首先介绍了注意力机制及其相应的架构,然后介绍了以自注意力机制为核心的 Transformer 架构,最后介绍了几种基于 Transformer 结构的典型应用,如用于图像分类任务的 ViT 和用于图像分类、目标检测、语义分割等任务的 Swin-T 。从这些架构的性能来看,基于 Transformer 的架构在 CV 和 NLP 领域的发展潜力巨大,将日益受到大家的重视。
















 20万+
20万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











