







DSSM学习报告
从文本挖掘的知识图谱开始
-
当对一个领域只了解某些部分的时候,从一个知识图出发是最好的。


-
查概念可以查到,DSSM是通过搜索引擎里 Query 和 Title 的海量的点击曝光日志,用 DNN 把 Query 和 Title 表达为低纬语义向量,并通过 cosine 距离来计算两个语义向量的距离,最终训练出语义相似度模型。该模型既可以用来预测两个句子的语义相似度,又可以获得某句子的低纬语义向量表达。
-
主要解决的问题有:
- 解决了LSA、LDA、Autoencoder等方法存在的一个最大的问题:字典爆炸(导致计算复杂度非常高),因为在英文单词中,词的数量可能是没有限制的,但是字母 [公式] -gram的数量通常是有限的
- 基于词的特征表示比较难处理新词,字母的 [公式] -gram可以有效表示,鲁棒性较强
- 使用有监督方法,优化语义embedding的映射问题
- 省去了人工的特征工程
-
看关键词的话,感觉应该是在这个片区

-
表达为低纬向量,走的时候word embedding区域的隐语义分析区域的那块。
-
cosine距离计算两个语义向量距离,则是document片区的string distance。
-
几乎没怎么搜到涉及到text mining的document关键词的内容,猜测是词向量方向涉及到的专有名词,描述词向量相关属性的内容。
代码及相关研究
权威论文及相关博客
DSSM & Multi-view DSSM TensorFlow实现:
https://github.com/InsaneLife/dssm
https://blog.csdn.net/shine19930820/article/details/79042567
Learning Deep Structured Semantic Models for Web Search using Clickthrough Data ※
https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/cikm2013_DSSM_fullversion.pdf
A Latent Semantic Model with Convolutional-Pooling (CNN-DSSM)
http://www.iro.umontreal.ca/~lisa/pointeurs/ir0895-he-2.pdf
SEMANTIC MODELLING WITH LONG-SHORT-TERM MEMORY FOR INFORMATION RETRIEVAL
https://arxiv.org/pdf/1412.6629.pdf
A Multi-View Deep Learning Approach for Cross Domain User Modeling in Recommendation Systems
https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/frp1159-songA.pdf
微软关于DSSM研究一个主页
https://www.microsoft.com/en-us/research/project/dssm/#!publications
我们选用第二篇作为我们的实验研究的代码
了解DSSM解决的背景
- 一般的搜索引擎往往都是搜索与query中词汇重复的内容。
- 但是人们在搜索的时候,往往无法准确的描述自己想要的内容(或者存在同义异词的情况)
- 这个时候搜索出的内容往往是不准确的。
- 此时就需要用潜在语义模型来匹配“query-需要的结果”。
- 然后因为以前的主题模型基本都是非监督,依赖上下文,所以经常出现不准的情况。
- 现在我们【写论文的人】拿到了clickthrough的数据,就可以做出一个query-document匹配的模型了。
- 【以上论文第一页INTRODUCTION部分】
数据
-
由于英文的clickthrough数据论文方不提供,我从另外一份代码中找了一份中文的数据。
-
数据来自天池大数据比赛,是OPPO手机搜索排序query-title语义匹配的问题。
-
数据的格式大概是这样的
桂鱼 | {“桂鱼多少钱一斤”: “0.071”, “桂鱼价格”: “0.013”, “桂鱼图片大全”: “0.012”, “桂鱼汤”: “0.010”, “桂鱼的营养价值与功效”: “0.011”, “桂鱼图片”: “0.178”, “桂鱼怎么钓”: “0.024”, “桂鱼的做法”: “0.054”, “桂鱼多少钱一斤2018”: “0.012”, “桂鱼怎么做好吃”: “0.116”} | 石桂鱼 | 百科 | 0
- “|”为分界。
- 第一个是prefix,代表用户一开始输入了什么。
- 第二个是预测的结果,根据当前前缀,预测的用户完整需求查询词,最多10条;预测的查询词可能是前缀本身,数字为统计概率 。
- 第三个是文章标题(应该是指最后点进去的文章标题)。
- 第四个是文章内容标签 。
- 第五个是是否点击。
- 为了应用来训练DSSM demo,将prefix和title作为正样,prefix和query_prediction(除title以外)作为负样本。

- 英文版的clickthrough数据没有公布,但是可以预见形式应该差不多。
- 中英文的wordhash方法不一样,英文的用word-ngram,但是中文以词汇为单位,向量空间太大了;所以中文以字为单位,用的是charactergram.
代码研究
- 研究的代码来自这个仓库: https://github.com/LiangHao151941/dssm
- 文件为:dssm_v3.py
- 最核心的就是参考这张图

- 最核心的内容还是结合这张图来看。代码里无论是层级,还是权重输入和输出,图片基本都是相对应的。
- 下面是代码和详细的注释。
import pickle
import random
import time
import sys
import numpy as np
import tensorflow as tf
flags = tf.app.flags
FLAGS = flags.FLAGS
# f.app.flags.DEFINE_xxx()就是添加命令行的optional argument(可选参数),而tf.app.flags.FLAGS可以从对应的命令行参数取出参数。
# 可以认为是一个训练时,别人不懂文档参数的时候,打印出的帮助界面。
# https://blog.csdn.net/m0_37041325/article/details/77448971
flags.DEFINE_string('summaries_dir', '/tmp/dssm-400-120-relu', 'Summaries directory')
flags.DEFINE_float('learning_rate', 0.1, 'Initial learning rate.')
flags.DEFINE_integer('max_steps', 900000, 'Number of steps to run trainer.')
flags.DEFINE_integer('epoch_steps', 18000, "Number of steps in one epoch.")
flags.DEFINE_integer('pack_size', 2000, "Number of batches in one pickle pack.")
flags.DEFINE_bool('gpu', 1, "Enable GPU or not")
# 获得当前的时间戳
start = time.time()
doc_train_data = None
query_train_data = None
# load test data for now
# rb 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。
# pickle.load(file)
# file:对象保存到的类文件对象。file必须有write()接口, file可以是一个以’w’方式打开的文件或者一个StringIO对象或者其他任何实现write()接口的对象。
# tocsr() https://blog.csdn.net/gaoborl/article/details/82869858
# 仔细多读几遍会明白什么意思的
# 好处:高效的CSR + CSR, CSR *CSR算术运算;高效的行切片操作;高效的矩阵内积内积操作。
query_test_data = pickle.load(open('../data/query.test.pickle', 'rb')).tocsr()
doc_test_data = pickle.load(open('../data/doc.test.pickle', 'rb')).tocsr()
doc_train_data = pickle.load(open('../data/doc.train.pickle', 'rb')).tocsr()
query_train_data = pickle.load(open('../data/query.train.pickle', 'rb')).tocsr()
end = time.time()
# 计算读到硬盘的时间
print("Loading data from HDD to memory: %.2fs" % (end - start))
# Trigram_D数目
TRIGRAM_D = 49284
# NEG表示负样本的个数
NEG = 50
# BS表示batch_size,计算batch平均损失
BS = 1024
# 论文里面都是300,参考
L1_N = 400
L2_N = 120
# 创建BS*TRIGRAM_D大小的数组,shape更像是表示长度和宽度
query_in_shape = np.array([BS, TRIGRAM_D], np.int64)
doc_in_shape = np.array([BS, TRIGRAM_D], np.int64)
def variable_summaries(var, name):
"""Attach a lot of summaries to a Tensor."""
# TF有两种作用域类型:命名域(name scope),通过tf.name_scope或tf.op_scope创建;
# 还有一种是变量域,通过tf.variable_scope或tf.variable_op_scope创建
# 主要用于管理一个图里面的各种操作,返回的是一个以scope_name命名的context+manager。
# 这里可以认为是定义数据总结的操作
with tf.name_scope('summaries'):
# 计算矩阵竖列的平均值
mean = tf.reduce_mean(var)
# 用来显示标量信息,一般绘图会用到
tf.scalar_summary('mean/' + name, mean)
# standard deviation 标准差(同样绘图用)
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_sum(tf.square(var - mean)))
tf.scalar_summary('sttdev/' + name, stddev)
tf.scalar_summary('max/' + name, tf.reduce_max(var))
tf.scalar_summary('min/' + name, tf.reduce_min(var))
# 画出参数直方图
tf.histogram_summary(name, var)
# 对应的是输入层
with tf.name_scope('input'):
# Shape [BS, TRIGRAM_D].
# tf.sparse_placeholder 函数返回一个可以用作提供值的句柄的 SparseTensor,但不能直接计算.
query_batch = tf.sparse_placeholder(tf.float32, shape=query_in_shape, name='QueryBatch')
# Shape [BS, TRIGRAM_D]
doc_batch = tf.sparse_placeholder(tf.float32, shape=doc_in_shape, name='DocBatch')
# word hashing
# trigram是一种词汇的哈希方法
with tf.name_scope('L1'):
# TRIGRAM_D指的是TRIGRAM的dimension
# L1_N则是第一层的层数
# 这段公式来自论文第4页3.3部分,作者没有详细解释这条公式
# 说是引用了这本书,Neural Networks: Tricks of the Train
l1_par_range = np.sqrt(6.0 / (TRIGRAM_D + L1_N))
# SGD,随机均匀初始化权值
weight1 = tf.Variable(tf.random_uniform([TRIGRAM_D, L1_N], -l1_par_range, l1_par_range))
bias1 = tf.Variable(tf.random_uniform([L1_N], -l1_par_range, l1_par_range))
variable_summaries(weight1, 'L1_weights')
variable_summaries(bias1, 'L1_biases')
# 基本就是通过第一层的query和doc的权值和偏置,给出第二层的权值和偏置
# query_l1 = tf.matmul(tf.to_float(query_batch),weight1)+bias1
query_l1 = tf.sparse_tensor_dense_matmul(query_batch, weight1) + bias1
# doc_l1 = tf.matmul(tf.to_float(doc_batch),weight1)+bias1
doc_l1 = tf.sparse_tensor_dense_matmul(doc_batch, weight1) + bias1
# 计算激活函数relu,将大于0的保持不变,小于0的置为0
query_l1_out = tf.nn.relu(query_l1)
doc_l1_out = tf.nn.relu(doc_l1)
# 第二到第四层是典型的MLP网络,最终得到128维的句子表示
with tf.name_scope('L2'):
l2_par_range = np.sqrt(6.0 / (L1_N + L2_N))
weight2 = tf.Variable(tf.random_uniform([L1_N, L2_N], -l2_par_range, l2_par_range))
bias2 = tf.Variable(tf.random_uniform([L2_N], -l2_par_range, l2_par_range))
variable_summaries(weight2, 'L2_weights')
variable_summaries(bias2, 'L2_biases')
query_l2 = tf.matmul(query_l1_out, weight2) + bias2
doc_l2 = tf.matmul(doc_l1_out, weight2) + bias2
query_y = tf.nn.relu(query_l2)
doc_y = tf.nn.relu(doc_l2)
# 看不懂,猜测是随机选NEG个(按照论文里应该是128个)输出,组成semantic feature的y
with tf.name_scope('FD_rotate'):
# Rotate FD+ to produce 50 FD-
temp = tf.tile(doc_y, [1, 1])
for i in range(NEG):
rand = int((random.random() + i) * BS / NEG)
doc_y = tf.concat(0,
[doc_y,
tf.slice(temp, [rand, 0], [BS - rand, -1]),
tf.slice(temp, [0, 0], [rand, -1])])
with tf.name_scope('Cosine_Similarity'):
# Cosine similarity
# tensorflow中的tile()函数是用来对张量(Tensor)进行扩展的,其特点是对当前张量内的数据进行一定规则的复制。
# 就是对某一维张量进行拓展,称为原来的某倍
# reduce_sum就是通过相加的方式进行张量降维,例如有一个2*3*4的矩阵,通过把两个3*4的矩阵相加
# 即可完成张量降维,但是如果给与True,则会保持原来的张量降维
# 这一步应该是在拓展query_norm使得query可以和doc相乘
# 论文3.1 公式5
query_norm = tf.tile(tf.sqrt(tf.reduce_sum(tf.square(query_y), 1, True)), [NEG + 1, 1])
doc_norm = tf.sqrt(tf.reduce_sum(tf.square(doc_y), 1, True))
# product 应该是点积,在计算cos距离
prod = tf.reduce_sum(tf.mul(tf.tile(query_y, [NEG + 1, 1]), doc_y), 1, True)
norm_prod = tf.mul(query_norm, doc_norm)
# cos_sim_raw = query * doc / (||query|| * ||doc||)
cos_sim_raw = tf.truediv(prod, norm_prod)
# gamma = 20
# tf.transpose(a, perm = None, name = 'transpose')
# 将a进行转置,并且根据perm参数重新排列输出维度。这是对数据的维度的进行操作的形式。
cos_sim = tf.transpose(tf.reshape(tf.transpose(cos_sim_raw), [NEG + 1, BS])) * 20
with tf.name_scope('Loss'):
# Train Loss
# 利用平滑后的softmax得到概率
prob = tf.nn.softmax((cos_sim))
# 只取第一列,即正样本列概率。
hit_prob = tf.slice(prob, [0, 0], [-1, 1])
loss = -tf.reduce_sum(tf.log(hit_prob)) / BS
tf.scalar_summary('loss', loss)
# tf.train.GradientDescentOptimizer(learning_rate, use_locking=False,name=’GradientDescent’)
# learning_rate: A Tensor or a floating point value. 要使用的学习率
# use_locking: 要是True的话,就对于更新操作(update operations.)使用锁
# name: 名字,可选,默认是”GradientDescent”
with tf.name_scope('Training'):
# Optimizer
train_step = tf.train.GradientDescentOptimizer(FLAGS.learning_rate).minimize(loss)
# with tf.name_scope('Accuracy'):
# correct_prediction = tf.equal(tf.argmax(prob, 1), 0)
# accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# tf.scalar_summary('accuracy', accuracy)
merged = tf.merge_all_summaries()
with tf.name_scope('Test'):
average_loss = tf.placeholder(tf.float32)
loss_summary = tf.scalar_summary('average_loss', average_loss)
def pull_batch(query_data, doc_data, batch_idx):
# start = time.time()
query_in = query_data[batch_idx * BS:(batch_idx + 1) * BS, :]
doc_in = doc_data[batch_idx * BS:(batch_idx + 1) * BS, :]
if batch_idx == 0:
print(query_in.getrow(53))
# COO矩阵,在之前将CSR矩阵的那个文章里有讲
query_in = query_in.tocoo()
doc_in = doc_in.tocoo()
# 创建一个系数张量的实例
query_in = tf.SparseTensorValue(
np.transpose([np.array(query_in.row, dtype=np.int64), np.array(query_in.col, dtype=np.int64)]),
np.array(query_in.data, dtype=np.float),
np.array(query_in.shape, dtype=np.int64))
doc_in = tf.SparseTensorValue(
np.transpose([np.array(doc_in.row, dtype=np.int64), np.array(doc_in.col, dtype=np.int64)]),
np.array(doc_in.data, dtype=np.float),
np.array(doc_in.shape, dtype=np.int64))
# end = time.time()
# print("Pull_batch time: %f" % (end - start))
return query_in, doc_in
# 把数据丢到tensor的placeholders里面
def feed_dict(Train, batch_idx):
"""Make a TensorFlow feed_dict: maps data onto Tensor placeholders."""
if Train:
query_in, doc_in = pull_batch(query_train_data, doc_train_data, batch_idx)
else:
query_in, doc_in = pull_batch(query_test_data, doc_test_data, batch_idx)
return {query_batch: query_in, doc_batch: doc_in}
config = tf.ConfigProto() # log_device_placement=True)
config.gpu_options.allow_growth = True
#if not FLAGS.gpu:
#config = tf.ConfigProto(device_count= {'GPU' : 0})
with tf.Session(config=config) as sess:
# 用 tf.global_variables_initializer() 替代 tf.initialize_all_variables()
sess.run(tf.initialize_all_variables())
# 总结性文件会放的位置
train_writer = tf.train.SummaryWriter(FLAGS.summaries_dir + '/train', sess.graph)
test_writer = tf.train.SummaryWriter(FLAGS.summaries_dir + '/test', sess.graph)
# Actual execution
start = time.time()
# fp_time = 0
# fbp_time = 0
# 跑batch和输出一些东西的循环
for step in range(FLAGS.max_steps):
batch_idx = step % FLAGS.epoch_steps
# if batch_idx % FLAGS.pack_size == 0:
# load_train_data(batch_idx / FLAGS.pack_size + 1)
# # setup toolbar
# sys.stdout.write("[%s]" % (" " * toolbar_width))
# #sys.stdout.flush()
# sys.stdout.write("\b" * (toolbar_width + 1)) # return to start of line, after '['
if batch_idx == 0:
temp = sess.run(query_y, feed_dict=feed_dict(True, 0))
print(np.count_nonzero(temp))
sys.exit()
if batch_idx % (FLAGS.pack_size / 64) == 0:
progress = 100.0 * batch_idx / FLAGS.epoch_steps
sys.stdout.write("\r%.2f%% Epoch" % progress)
sys.stdout.flush()
# t1 = time.time()
# sess.run(loss, feed_dict = feed_dict(True, batch_idx))
# t2 = time.time()
# fp_time += t2 - t1
# #print(t2-t1)
# t1 = time.time()
sess.run(train_step, feed_dict=feed_dict(True, batch_idx % FLAGS.pack_size))
# t2 = time.time()
# fbp_time += t2 - t1
# #print(t2 - t1)
# if batch_idx % 2000 == 1999:
# print ("MiniBatch: Average FP Time %f, Average FP+BP Time %f" %
# (fp_time / step, fbp_time / step))
if batch_idx == FLAGS.epoch_steps - 1:
end = time.time()
epoch_loss = 0
for i in range(FLAGS.pack_size):
loss_v = sess.run(loss, feed_dict=feed_dict(True, i))
epoch_loss += loss_v
epoch_loss /= FLAGS.pack_size
train_loss = sess.run(loss_summary, feed_dict={average_loss: epoch_loss})
train_writer.add_summary(train_loss, step + 1)
# print ("MiniBatch: Average FP Time %f, Average FP+BP Time %f" %
# (fp_time / step, fbp_time / step))
#
print ("\nEpoch #%-5d | Train Loss: %-4.3f | PureTrainTime: %-3.3fs" %
(step / FLAGS.epoch_steps, epoch_loss, end - start))
epoch_loss = 0
for i in range(FLAGS.pack_size):
loss_v = sess.run(loss, feed_dict=feed_dict(False, i))
epoch_loss += loss_v
epoch_loss /= FLAGS.pack_size
test_loss = sess.run(loss_summary, feed_dict={average_loss: epoch_loss})
test_writer.add_summary(test_loss, step + 1)
start = time.time()
print ("Epoch #%-5d | Test Loss: %-4.3f | Calc_LossTime: %-3.3fs" %
(step / FLAGS.epoch_steps, epoch_loss, start - end))
关于预处理方式和结果的关系
- 它就说这个mean Normalized Discounted Cumulative Gain(NDCG)就是衡量这个模型的标准.
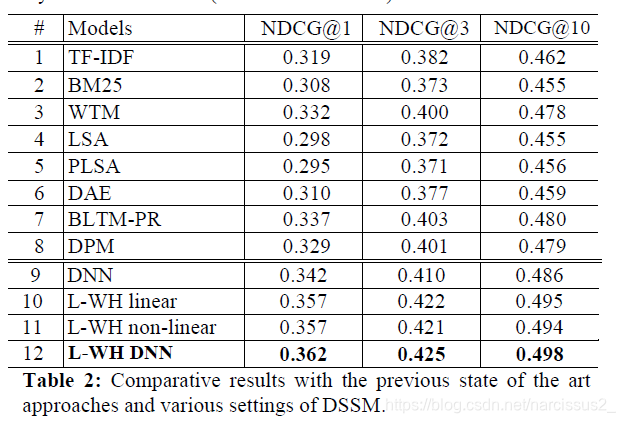
- 然后得到结论,显然是Letter-WordHashing + DNN是最好的。














 5418
5418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









