






- YOLOv2理论篇
- YOLOv2实践篇
工程框架:
YOLOv2引入anchor机制后,在目标的回归上比v1版本效果好了很多。下面是一些代码实现,因为自己建的工程,所以这个系列的整体代码结构会比较相似。
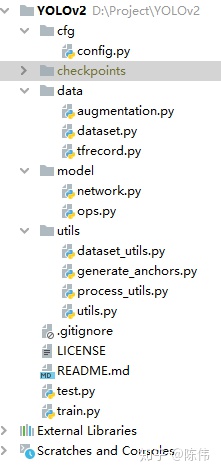
config作为参数文件用于保存训练参数、测试参数、模型参数、路径参数等信息;
dataset文件夹下保存数据处理相关文件,包括用于数据增广的文件,用于TFRecord制作和读取的文件,图像预处理和真值编码的文件;
model文件夹下保存和网络模型相关文件,包括模型搭建的文件,子操作实现的文件;
utils文件夹下保存周边计算相关文件,包括数据文本操作、anchor生成、网络后处理等文件;
train/test分别是训练代码和预测代码;
数据相关:
本模型我们采用的是FDDB2016人脸数据集做的训练,依然把数据集制作成TFRecord的格式,但是不同于之前YOLOv1的代码,这里的数据解析没有使用队列的方式,而是直接用TF提供的tf.data接口做的数据读取,具体代码如下:
# 数值形式的数据,首先转换为string,再转换为int形式进行保存
def _int64_feature(self, value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=value))
def _float_feature(self, value):
return tf.train.Feature(float_list=tf.train.FloatList(value=[value]))
# 数组形式的数据,首先转换为string,再转换为二进制形式进行保存
def _bytes_feature(self, value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def create_tfrecord(self):
# 获取作为训练验证集的图片序列
trainval_path = os.path.join(self.data_path, 'trainval.txt')
tf_file = os.path.join(self.tfrecord_dir, self.train_tfrecord_name)
if os.path.exists(tf_file):
os.remove(tf_file)
writer = tf.python_io.TFRecordWriter(tf_file)
with open(trainval_path, 'r') as read:
lines = read.readlines()
for line in lines:
filename = line[0:-1]
image_raw, bbox_raw, image_shape = self.dataset.load_data(filename)
example = tf.train.Example(features=tf.train.Features(
feature={
'image': tf.train.Feature(bytes_list=tf.train.BytesList(value=[image_raw])),
'bbox': tf.train.Feature(bytes_list=tf.train.BytesList(value=[bbox_raw])),
'height': tf.train.Feature(int64_list=tf.train.Int64List(value=[image_shape[0]])),
'width': tf.train.Feature(int64_list=tf.train.Int64List(value=[image_shape[1]])),
}))
writer.write(example.SerializeToString())
writer.close()
print('Finish trainval.tfrecord Done')
def parse_single_example(self, serialized_example):
"""
:param serialized_example:待解析的tfrecord文件的名称
:return: 从文件中解析出的单个样本的相关特征,image, label
"""
# 解析单个样本文件
features = tf.parse_single_example(
serialized_example,
features={
'image': tf.FixedLenFeature([], tf.string),
'bbox': tf.FixedLenFeature([], tf.string),
'height': tf.FixedLenFeature([], tf.int64),
'width': tf.FixedLenFeature([], tf.int64)
})
# 进行解码
tf_image = tf.decode_raw(features['image'], tf.uint8)
tf_bbox = tf.decode_raw(features['bbox'], tf.float32)
tf_height = features['height']
tf_width = features['width']
# 转换为网络输入所要求的形状
tf_image = tf.reshape(tf_image, [tf_height, tf_width, 3])
tf_label = tf.reshape(tf_bbox, [150, 5])
tf_image, y_true = tf.py_func(self.dataset.preprocess_true_data, inp=[tf_image, tf_label], Tout=[tf.float32, tf.float32])
y_true = tf.reshape(y_true, [self.grid_height, self.grid_width, 5, 6])
return tf_image, y_true
def create_dataset(self, filenames, batch_num, batch_size=1, is_shuffle=False):
"""
:param filenames: record file names
:param batch_size: batch size
:param is_shuffle: whether shuffle
:param n_repeats: number of repeats
:return:
"""
dataset = tf.data.TFRecordDataset(filenames)
dataset = dataset.map(self.parse_single_example, num_parallel_calls=4)
if is_shuffle:
dataset = dataset.shuffle(batch_num)
dataset = dataset.batch(batch_size)
dataset = dataset.repeat()
dataset = dataset.prefetch(batch_size)
return dataset在load_data函数中,考虑不同图片中的box数量不等,从二进制中解析得到的标签信息无法reshape到固定尺寸,所以我们设置最大box数量150个,解析后去掉无效数值。
在preprocess_true_data函数中,对数据做了简单的增广(水平翻转,裁剪,平移),然后编码真值标签,将[num, 5]的boxes转换成shape形如[feature_height, feature_width, per_anchor_num, 5 + numclasses]的y_true,图像数据进行常规归一化操作,原则上减少模型内部的隐式转换。
def load_data(self, filename):
"""
load image and label
:param filename: file name
:return: image_raw, bbox_raw, image_shape
"""
image_path = os.path.join(self.data_path, "images", filename+'.jpg')
image = cv2.imread(image_path)
image_shape = image.shape
label_path = os.path.join(self.data_path, "labels", filename+'.txt')
lines = [line.rstrip() for line in open(label_path)]
bboxes = []
for line in lines:
data = line.split(' ')
data[0:] = [float(t) for t in data[0:]]
box = self.convert(data)
bboxes.append(box)
while len(bboxes) < 150:
bboxes = np.append(bboxes, [[0.0, 0.0, 0.0, 0.0, 0.0]], axis=0)
bboxes = np.array(bboxes, dtype=np.float32)
image_raw = image.tobytes()
bbox_raw = bboxes.tobytes()
return image_raw, bbox_raw, image_shape
def preprocess_true_data(self, image, labels):
"""
preprocess true boxes to train input format
:param image: numpy.ndarray of shape [416, 416, 3]
:param labels: numpy.ndarray of shape [20, 5]
shape[0]: the number of labels in each image.
shape[1]: x_min, y_min, x_max, y_max, class_index, yaw
:return:
image_norm is normalized image[0~1]
y_true shape is [feature_height, feature_width, per_anchor_num, 5 + num_classes]
"""
# 数据增广,包括水平翻转,裁剪,平移
image = np.array(image)
image, labels = random_horizontal_flip(image, labels)
image, labels = random_crop(image, labels)
image, labels = random_translate(image, labels)
# 图像尺寸缩放到416*416,并进行归一化
image_rgb = cv2.cvtColor(np.copy(image), cv2.COLOR_BGR2RGB).astype(np.float32)
image_rgb, labels = letterbox_resize(image_rgb, (self.input_height, self.input_width), np.copy(labels), interp=0)
image_norm = image_rgb / 255.
input_shape = np.array([self.input_height, self.input_width], dtype=np.int32)
assert input_shape[0] % 32 == 0
assert input_shape[1] % 32 == 0
feature_sizes = input_shape // 32
# anchors 归一化到图像空间0~1
num_anchors = len(self.anchors)
anchor_array = np.array(model_params['anchors'])
# labels 去除空标签
valid = (np.sum(labels, axis=-1) > 0).tolist()
labels = labels[valid]
y_true = np.zeros(shape=[feature_sizes[0], feature_sizes[1], num_anchors, 4 + 1 + len(self.num_classes)], dtype=np.float32)
boxes_xy = (labels[:, 0:2] + labels[:, 2:4]) / 2
boxes_wh = labels[:, 2:4] - labels[:, 0:2]
true_boxes = np.concatenate([boxes_xy, boxes_wh], axis=-1)
anchors_max = anchor_array / 2.
anchors_min = - anchor_array / 2.
valid_mask = boxes_wh[:, 0] > 0
wh = boxes_wh[valid_mask]
# [N, 1, 2]
wh = np.expand_dims(wh, -2)
boxes_max = wh / 2.
boxes_min = - wh / 2.
# [N, 1, 2] & [5, 2] ==> [N, 5, 2]
intersect_mins = np.maximum(boxes_min, anchors_min)
intersect_maxs = np.minimum(boxes_max, anchors_max)
# [N, 5, 2]
intersect_wh = np.maximum(intersect_maxs - intersect_mins, 0.)
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
box_area = wh[..., 0] * wh[..., 1]
anchor_area = anchor_array[:, 0] * anchor_array[:, 1]
# [N, 5]
iou = intersect_area / (box_area + anchor_area - intersect_area + tf.keras.backend.epsilon())
# Find best anchor for each true box [N]
best_anchor = np.argmax(iou, axis=-1)
for t, k in enumerate(best_anchor):
i = int(np.floor(true_boxes[t, 0] / 32.))
j = int(np.floor(true_boxes[t, 1] / 32.))
c = labels[t, 4].astype('int32')
y_true[j, i, k, 0:4] = true_boxes[t, 0:4]
y_true[j, i, k, 4] = 1
y_true[j, i, k, 5 + c] = 1
return image_norm, y_true网络模型:
模型搭建这块比较简单,二维卷积和最大池化的堆叠操作,最后生成的特征图尺寸为[13*13*5*(5+numclass)],本例子中是13*13*5*6表示原始416*416大小的图像进过5次下采样变为13*13的大小,5表示每个cell(一共13*13个cell)预测的框的个数即anchor数量,也可以说是每个cell中最多预测的物体数。6表示(4+1+1,4:坐标x y and 长宽,1:预测概率,1:类别个数(人脸))
def build_network(self, inputs, scope='yolo_v2'):
"""
定义前向传播过程
:param inputs:待输入的样本图片
:param scope: 命名空间
:return: 网络最终的输出
"""
net = conv2d(inputs, filters_num=32, filters_size=3, pad_size=1, is_train=self.is_train, name='conv1')
net = maxpool(net, size=2, stride=2, name='pool1')
net = conv2d(net, 64, 3, 1, is_train=self.is_train, name='conv2')
net = maxpool(net, 2, 2, name='pool2')
net = conv2d(net, 128, 3, 1, is_train=self.is_train, name='conv3_1')
net = conv2d(net, 64, 1, 0, is_train=self.is_train, name='conv3_2')
net = conv2d(net, 128, 3, 1, is_train=self.is_train, name='conv3_3')
net = maxpool(net, 2, 2, name='pool3')
net = conv2d(net, 256, 3, 1, is_train=self.is_train, name='conv4_1')
net = conv2d(net, 128, 1, 0, is_train=self.is_train, name='conv4_2')
net = conv2d(net, 256, 3, 1, is_train=self.is_train, name='conv4_3')
net = maxpool(net, 2, 2, name='pool4')
net = conv2d(net, 512, 3, 1, is_train=self.is_train, name='conv5_1')
net = conv2d(net, 256, 1, 0, is_train=self.is_train, name='conv5_2')
net = conv2d(net, 512, 3, 1, is_train=self.is_train, name='conv5_3')
net = conv2d(net, 256, 1, 0, is_train=self.is_train, name='conv5_4')
net = conv2d(net, 512, 3, 1, is_train=self.is_train, name='conv5_5')
# 存储这一层特征图,以便后面passthrough层
shortcut = net
net = maxpool(net, 2, 2, name='pool5')
net = conv2d(net, 1024, 3, 1, is_train=self.is_train, name='conv6_1')
net = conv2d(net, 512, 1, 0, is_train=self.is_train, name='conv6_2')
net = conv2d(net, 1024, 3, 1, is_train=self.is_train, name='conv6_3')
net = conv2d(net, 512, 1, 0, is_train=self.is_train, name='conv6_4')
net = conv2d(net, 1024, 3, 1, is_train=self.is_train, name='conv6_5')
net = conv2d(net, 1024, 3, 1, is_train=self.is_train, name='conv7_1')
net = conv2d(net, 1024, 3, 1, is_train=self.is_train, name='conv7_2')
# shortcut增加了一个中间卷积层,先采用64个1*1卷积核进行卷积,然后再进行passthrough处理
# 这样26*26*512 -> 26*26*64 -> 13*13*256的特征图
shortcut = conv2d(shortcut, 64, 1, 0, is_train=self.is_train, name='conv_shortcut')
shortcut = reorg(shortcut, 2)
net = tf.concat([shortcut, net], axis=-1)
net = conv2d(net, 1024, 3, 1, is_train=self.is_train, name='conv8')
# 用一个1*1卷积去调整channel,该层没有bn层和激活函数
logits = conv2d(net, filters_num=self.output_size, filters_size=1, batch_normalize=False, activation=None, use_bias=True, name='conv_dec')
return logits在reorg_layer函数中,我们对网络的输出特征图进行解码操作,生成预测box相对于原图的中心xy,长宽wh。由于box的中心点预测是相对于特征图网格的偏移,所以在解码过程中要在预测值的基础上加上网格位置信息;box的长宽预测是相对于anchor的缩放,所以在解码过程中要乘上anchor的长宽。
def reorg_layer(self, feature_maps, anchors=None):
"""
解码网络输出的特征图
:param feature_maps:网络输出的特征图
:param anchors:
:return: 网络最终的输出
"""
feature_shape = tf.shape(feature_maps)[1:3]
ratio = tf.cast([self.input_height, self.input_width] / feature_shape, tf.float32)
# 将传入的anchors转变成tf格式的常量列表
rescaled_anchors = [(anchor[0] / ratio[1], anchor[1] / ratio[0]) for anchor in anchors]
# 网络输出转化——偏移量、置信度、类别概率
feature_maps = tf.reshape(feature_maps, [-1, feature_shape[0] * feature_shape[1], self.num_anchors, self.class_num + 5])
# 中心坐标相对于该cell左上角的偏移量,sigmoid函数归一化到0-1
xy_offset = tf.nn.sigmoid(feature_maps[:, :, :, 0:2])
# 相对于anchor的wh比例,通过e指数解码
wh_offset = tf.clip_by_value(tf.exp(feature_maps[:, :, :, 2:4]), 1e-9, 50)
# 置信度,sigmoid函数归一化到0-1
obj_probs = tf.nn.sigmoid(feature_maps[:, :, :, 4:5])
# 网络回归的是得分,用softmax转变成类别概率
class_probs = tf.nn.softmax(feature_maps[:, :, :, 5:])
# 构建特征图每个cell的左上角的xy坐标
height_index = tf.range(tf.cast(feature_shape[0], tf.float32), dtype=tf.float32) # range(0,13)
width_index = tf.range(tf.cast(feature_shape[1], tf.float32), dtype=tf.float32) # range(0,13)
# 变成x_cell=[[0,1,...,12],...,[0,1,...,12]]和y_cell=[[0,0,...,0],[1,...,1]...,[12,...,12]]
x_cell, y_cell = tf.meshgrid(height_index, width_index)
x_cell = tf.reshape(x_cell, [1, -1, 1]) # 和上面[H*W,num_anchors,num_class+5]对应
y_cell = tf.reshape(y_cell, [1, -1, 1])
xy_cell = tf.stack([x_cell, y_cell], axis=-1)
bboxes_xy = (xy_cell + xy_offset) * ratio[::-1]
bboxes_wh = (rescaled_anchors * wh_offset) * ratio[::-1]
if self.is_train == False:
bboxes_xywh = tf.concat([bboxes_xy, bboxes_wh], axis=-1)
bboxes_corners = tf.stack([bboxes_xywh[..., 0] - bboxes_xywh[..., 2] / 2,
bboxes_xywh[..., 1] - bboxes_xywh[..., 3] / 2,
bboxes_xywh[..., 0] + bboxes_xywh[..., 2] / 2,
bboxes_xywh[..., 1] + bboxes_xywh[..., 3] / 2], axis=3)
return bboxes_corners, obj_probs, class_probs
bboxes_xy = tf.reshape(bboxes_xy, [-1, feature_shape[0], feature_shape[1], self.num_anchors, 2])
bboxes_wh = tf.reshape(bboxes_wh, [-1, feature_shape[0], feature_shape[1], self.num_anchors, 2])
return bboxes_xy, bboxes_wh损失函数:
在calc_loss函数中,我们把真值和预测值放在原始图像空间计算,定位损失采用diou计算,置信度和分类损失采用sigmoid_cross_entropy_with_logits计算,细节部分见如下代码:
def calc_loss(self, logits, y_true):
"""
计算预测值和标签直接的损失
:param logits: shape is [batch_size, grid_size, grid_size, anchor_num, 5 + num_class]
:param y_true: shape is [batch_size, grid_size, grid_size, anchor_num, 5 + num_class]
:return: 网络最终的输出
"""
feature_size = tf.shape(logits)[1:3]
ratio = tf.cast([self.input_height, self.input_width] / feature_size, tf.float32)
# ground truth
object_coords = y_true[:, :, :, :, 0:4]
object_masks = y_true[:, :, :, :, 4:5]
object_probs = y_true[:, :, :, :, 5:]
# shape: [N, 13, 13, 5, 4] & [N, 13, 13, 5] ==> [V, 4]
valid_true_boxes = tf.boolean_mask(object_coords, tf.cast(object_masks[..., 0], 'bool'))
# shape: [V, 2]
valid_true_box_xy = valid_true_boxes[:, 0:2]
valid_true_box_wh = valid_true_boxes[:, 2:4]
# predicts
pred_box_xy, pred_box_wh = self.reorg_layer(logits, self.anchors)
predictions = tf.reshape(logits, [-1, feature_size[0], feature_size[1], self.num_anchors, self.class_num + 5])
pred_conf_logits = predictions[:, :, :, :, 4:5]
pred_prob_logits = predictions[:, :, :, :, 5:]
# calc iou 计算每个pre_boxe与所有true_boxe的交并比.
# valid_true_box_xx: [V,2]
# pred_box_xx: [13,13,5,2]
# shape: [N, 13, 13, 5, V],
iou = self.broadcast_iou(valid_true_box_xy, valid_true_box_wh, pred_box_xy, pred_box_wh)
# shape : [N,13,13,5]
best_iou = tf.reduce_max(iou, axis=-1)
# get_ignore_mask shape: [N,13,13,5,1] 0,1张量
ignore_mask = tf.expand_dims(tf.cast(best_iou < self.iou_threshold, tf.float32), -1)
# shape: [N, 13, 13, 3, 1]
box_loss_scale = 2. - (y_true[..., 2:3] / tf.cast(self.input_height, tf.float32)) * (y_true[..., 3:4] / tf.cast(self.input_width, tf.float32))# y_true[..., 2:3] * y_true[..., 3:4]
pred_xywh = tf.concat([pred_box_xy, pred_box_wh], axis=-1)
diou = tf.expand_dims(self.bbox_diou(pred_xywh, object_coords), axis=-1)
diou_loss = object_masks * box_loss_scale * (1 - diou)
# shape: [N, 13, 13, 3, 1]
conf_pos_mask = object_masks
conf_neg_mask = (1 - object_masks) * ignore_mask
conf_loss_pos = conf_pos_mask * tf.nn.sigmoid_cross_entropy_with_logits(labels=object_masks, logits=pred_conf_logits)
conf_loss_neg = conf_neg_mask * tf.nn.sigmoid_cross_entropy_with_logits(labels=object_masks, logits=pred_conf_logits)
conf_loss = conf_loss_pos + conf_loss_neg
# shape: [N, 13, 13, 3, 1]
class_loss = object_masks * tf.nn.sigmoid_cross_entropy_with_logits(labels=object_probs, logits=pred_prob_logits)
diou_loss = tf.reduce_mean(tf.reduce_sum(diou_loss, axis=[1, 2, 3, 4]))
conf_loss = tf.reduce_mean(tf.reduce_sum(conf_loss, axis=[1, 2, 3, 4]))
class_loss = tf.reduce_mean(tf.reduce_sum(class_loss, axis=[1, 2, 3, 4]))
total_loss = diou_loss + conf_loss + class_loss
return total_loss, diou_loss, conf_loss, class_loss训练代码:
训练代码加入了预训练权重,因为FDDB2016数据集本身只有几千张图,所以给Darknet19加载了coco上的预训练权重再进行finetune。
def train():
start_step = 0
log_step = solver_params['log_step']
restore = solver_params['restore']
checkpoint_dir = path_params['checkpoints_dir']
checkpoints_name = path_params['checkpoints_name']
tfrecord_dir = path_params['tfrecord_dir']
tfrecord_name = path_params['train_tfrecord_name']
log_dir = path_params['logs_dir']
batch_size = solver_params['batch_size']
# 配置GPU
gpu_options = tf.GPUOptions(allow_growth=True)
config = tf.ConfigProto(gpu_options=gpu_options)
# 解析得到训练样本以及标注
data = tfrecord.TFRecord()
train_tfrecord = os.path.join(tfrecord_dir, tfrecord_name)
data_num = total_sample(train_tfrecord)
batch_num = int(math.ceil(float(data_num) / batch_size))
dataset = data.create_dataset(train_tfrecord, batch_num, batch_size=batch_size, is_shuffle=True)
iterator = dataset.make_one_shot_iterator()
images, y_true = iterator.get_next()
images.set_shape([None, 416, 416, 3])
y_true.set_shape([None, 13, 13, 5, 6])
# 构建网络
network = Network(is_train=True)
logits = network.build_network(images)
# 计算损失函数
total_loss, diou_loss, confs_loss, class_loss = network.calc_loss(logits, y_true)
global_step = tf.Variable(0, trainable=False)
learning_rate = tf.train.exponential_decay(solver_params['lr'], global_step, solver_params['decay_steps'], solver_params['decay_rate'], staircase=True)
optimizer = tf.train.AdamOptimizer(learning_rate)
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
train_op = optimizer.minimize(total_loss, global_step=global_step)
# 配置tensorboard
tf.summary.scalar("learning_rate", learning_rate)
tf.summary.scalar('total_loss', total_loss)
tf.summary.scalar("diou_loss", diou_loss)
tf.summary.scalar("confs_loss", confs_loss)
tf.summary.scalar("class_loss", class_loss)
# 配置tensorboard
summary_op = tf.summary.merge_all()
summary_writer = tf.summary.FileWriter(log_dir, graph=tf.get_default_graph(), flush_secs=60)
# 模型保存
save_variable = tf.global_variables()
saver = tf.train.Saver(save_variable, max_to_keep=50)
with tf.Session(config=config) as sess:
sess.run([tf.global_variables_initializer(), tf.local_variables_initializer()])
if restore == True:
ckpt = tf.train.get_checkpoint_state(checkpoint_dir)
if ckpt and ckpt.model_checkpoint_path:
stem = os.path.basename(ckpt.model_checkpoint_path)
restore_step = int(stem.split('.')[0].split('-')[-1])
start_step = restore_step
sess.run(global_step.assign(restore_step))
saver.restore(sess, ckpt.model_checkpoint_path)
print('Restoreing from {}'.format(ckpt.model_checkpoint_path))
else:
print("Failed to find a checkpoint")
if solver_params['pre_train']:
pretrained = np.load(path_params['pretrain_weights'], allow_pickle=True).item()
for variable in tf.trainable_variables():
for key in pretrained.keys():
key2 = variable.name.rstrip(':0')
if (key == key2):
sess.run(tf.assign(variable, pretrained[key]))
summary_writer.add_graph(sess.graph)
print('\n----------- start to train -----------\n')
for epoch in range(start_step + 1, solver_params['epoches']):
train_epoch_loss, train_epoch_diou_loss, train_epoch_confs_loss, train_epoch_class_loss = [], [], [], []
for index in tqdm(range(batch_num)):
_, summary_, loss_, diou_loss_, confs_loss_, class_loss_, global_step_, lr = sess.run([train_op, summary_op, total_loss, diou_loss, confs_loss, class_loss, global_step, learning_rate])
train_epoch_loss.append(loss_)
train_epoch_diou_loss.append(diou_loss_)
train_epoch_confs_loss.append(confs_loss_)
train_epoch_class_loss.append(class_loss_)
summary_writer.add_summary(summary_, global_step_)
train_epoch_loss, train_epoch_diou_loss, train_epoch_confs_loss, train_epoch_class_loss = np.mean(train_epoch_loss), np.mean(train_epoch_diou_loss), np.mean(train_epoch_confs_loss), np.mean(train_epoch_class_loss)
print("Epoch: {}, global_step: {}, lr: {:.8f}, total_loss: {:.3f}, diou_loss: {:.3f}, confs_loss: {:.3f}, class_loss: {:.3f}".format(epoch, global_step_, lr, train_epoch_loss, train_epoch_diou_loss, train_epoch_confs_loss, train_epoch_class_loss))
saver.save(sess, os.path.join(checkpoint_dir, checkpoints_name), global_step=epoch)
sess.close()测试代码:
测试部分有单帧测试和视频测试,代码其实差不多,用视频预测函数来说,主要是对每帧先进行图像预处理,颜色空间由BGR转RGB,并做归一化操作;之后加载权重进行前向传播;最后对网络的输出做nms过滤并可视化出来。
def predict_video():
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
capture = cv2.VideoCapture(0)
input = tf.placeholder(shape=[1, None, None, 3], dtype=tf.float32)
network = Network(is_train=False)
logits = network.build_network(input)
output = network.reorg_layer(logits, model_params['anchors'])
checkpoints = "./checkpoints/model.ckpt-128"
saver = tf.train.Saver()
with tf.Session(config=config) as sess:
saver.restore(sess, checkpoints)
while (True):
ref, image = capture.read()
image_size = image.shape[:2]
input_shape = [model_params['input_height'], model_params['input_width']]
image_data = preprocess(image, input_shape)
image_data = image_data[np.newaxis, ...]
bboxes, obj_probs, class_probs = sess.run(output, feed_dict={input: image_data})
bboxes, scores, class_id = postprocess(bboxes, obj_probs, class_probs, image_shape=image_size, input_shape=input_shape)
img_detection = visualization(image, bboxes, scores, class_id, model_params["classes"])
cv2.imshow("result", img_detection)
cv2.waitKey(1)
cv2.destroyAllWindows()图像预处理部分,OPENCV加载图片默认是BGR格式,保持和训练时相同转换成RGB,图像尺寸采用letter resize的方式保留特征一致性。
def preprocess(image, target_size, gt_boxes=None):
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB).astype(np.float32)
ih, iw = target_size
h, w, _ = image.shape
scale = min(iw / w, ih / h)
nw, nh = int(scale * w), int(scale * h)
image_resized = cv2.resize(image, (nw, nh))
image_paded = np.full(shape=[ih, iw, 3], fill_value=128.0, dtype=np.float32)
dw, dh = (iw - nw) // 2, (ih - nh) // 2
image_paded[dh:nh + dh, dw:nw + dw, :] = image_resized
image_paded = image_paded / 255.
if gt_boxes is None:
return image_paded
else:
gt_boxes[:, [0, 2]] = gt_boxes[:, [0, 2]] * scale + dw
gt_boxes[:, [1, 3]] = gt_boxes[:, [1, 3]] * scale + dh
return image_paded, gt_boxes图像后处理部分,将输出的box尺寸恢复到原始图像空间,再做NMS过滤置信度和IOU较小的box:
def postprocess(bboxes, obj_probs, class_probs, image_shape=(416,416), input_shape=(416, 416), threshold=0.5):
# boxes shape——> [num, 4] (xmin, ymin, xmax, ymax)
bboxes = np.reshape(bboxes, [-1, 4])
image_height, image_width = image_shape
resize_ratio = min(input_shape[1] / image_width, input_shape[0] / image_height)
dw = (input_shape[1] - resize_ratio * image_width) / 2
dh = (input_shape[0] - resize_ratio * image_height) / 2
bboxes[:, 0::2] = 1.0 * (bboxes[:, 0::2] - dw) / resize_ratio
bboxes[:, 1::2] = 1.0 * (bboxes[:, 1::2] - dh) / resize_ratio
bboxes[:, 0::2] = np.clip(bboxes[:, 0::2], 0, image_width)
bboxes[:, 1::2] = np.clip(bboxes[:, 1::2], 0, image_height)
bboxes = bboxes.astype(np.int32)
# 置信度 * 类别条件概率 = 类别置信度scores
obj_probs = np.reshape(obj_probs, [-1])
class_probs = np.reshape(class_probs, [len(obj_probs), -1])
class_max_index = np.argmax(class_probs, axis=1)
class_probs = class_probs[np.arange(len(obj_probs)), class_max_index]
scores = obj_probs * class_probs
# 类别置信度scores > threshold的边界框bboxes留下
keep_index = scores > threshold
class_max_index = class_max_index[keep_index]
scores = scores[keep_index]
bboxes = bboxes[keep_index]
# 排序取前400个
class_max_index, scores, bboxes = bboxes_sort(class_max_index, scores, bboxes)
# 计算nms
class_max_index, scores, bboxes = bboxes_nms(class_max_index, scores, bboxes)
return bboxes, scores, class_max_index其他相关:
Diou实现,具体原理可参考之前的文章,链接如下:
陈伟:目标检测回归损失函数——IOU、GIOU、DIOU、CIOU
def bbox_diou(self, boxes_1, boxes_2):
"""
calculate regression loss using diou
:param boxes_1: boxes_1 shape is [x, y, w, h]
:param boxes_2: boxes_2 shape is [x, y, w, h]
:return:
"""
# calculate center distance
center_distance = tf.reduce_sum(tf.square(boxes_1[..., :2] - boxes_2[..., :2]), axis=-1)
# transform [x, y, w, h] to [x_min, y_min, x_max, y_max]
boxes_1 = tf.concat([boxes_1[..., :2] - boxes_1[..., 2:] * 0.5,
boxes_1[..., :2] + boxes_1[..., 2:] * 0.5], axis=-1)
boxes_2 = tf.concat([boxes_2[..., :2] - boxes_2[..., 2:] * 0.5,
boxes_2[..., :2] + boxes_2[..., 2:] * 0.5], axis=-1)
boxes_1 = tf.concat([tf.minimum(boxes_1[..., :2], boxes_1[..., 2:]),
tf.maximum(boxes_1[..., :2], boxes_1[..., 2:])], axis=-1)
boxes_2 = tf.concat([tf.minimum(boxes_2[..., :2], boxes_2[..., 2:]),
tf.maximum(boxes_2[..., :2], boxes_2[..., 2:])], axis=-1)
# calculate area of boxes_1 boxes_2
boxes_1_area = (boxes_1[..., 2] - boxes_1[..., 0]) * (boxes_1[..., 3] - boxes_1[..., 1])
boxes_2_area = (boxes_2[..., 2] - boxes_2[..., 0]) * (boxes_2[..., 3] - boxes_2[..., 1])
# calculate the two corners of the intersection
left_up = tf.maximum(boxes_1[..., :2], boxes_2[..., :2])
right_down = tf.minimum(boxes_1[..., 2:], boxes_2[..., 2:])
# calculate area of intersection
inter_section = tf.maximum(right_down - left_up, 0.0)
inter_area = inter_section[..., 0] * inter_section[..., 1]
# calculate union area
union_area = boxes_1_area + boxes_2_area - inter_area
# calculate IoU, add epsilon in denominator to avoid dividing by 0
iou = inter_area / (union_area + tf.keras.backend.epsilon())
# calculate the upper left and lower right corners of the minimum closed convex surface
enclose_left_up = tf.minimum(boxes_1[..., :2], boxes_2[..., :2])
enclose_right_down = tf.maximum(boxes_1[..., 2:], boxes_2[..., 2:])
# calculate width and height of the minimun closed convex surface
enclose_wh = tf.maximum(enclose_right_down - enclose_left_up, 0.0)
# calculate enclosed diagonal distance
enclose_diagonal = tf.reduce_sum(tf.square(enclose_wh), axis=-1)
# calculate diou add epsilon in denominator to avoid dividing by 0
diou = iou - 1.0 * center_distance / (enclose_diagonal + tf.keras.backend.epsilon())
return diou从tfrecord文件中获取数据个数的函数:
def total_sample(file_name):
sample_nums = 0
for record in tf.python_io.tf_record_iterator(file_name):
sample_nums += 1
return sample_numskmeans聚类anchor的长宽,k按照YOLOv2的文章给的5。读者也可以优化成kmeans++,这样解决人工提供类别个数的弊端:
def kmeans(boxes, k):
"""
generate k anchors throught clustering
:param boxes: shape is (n, 2) ground truth, n is the number of ground truth
:param k: the number of anchors
:return: shape is (k, 2) anchors, k is the number of anchors
"""
num = boxes.shape[0]
distances = np.empty((num, k))
last_clusters = np.zeros((num,))
np.random.seed()
# randomly initialize k clustering center from num ground truth
clusters = boxes[np.random.choice(num, k, replace=False)]
while True:
# calculate the distance of each ground truth and k anchors
for i in range(num):
distances[i] = 1 - calc_iou(boxes[i], clusters)
# select nearest anchor index for each ground truth
nearest_clusters = np.argmin(distances, axis=1)
if (last_clusters == nearest_clusters).all():
break
# update clustering center using medium of every group cluster
for cluster in range(k):
clusters[cluster] = np.median((boxes[nearest_clusters == cluster]), axis=0)
last_clusters = nearest_clusters
return clusters, nearest_clusters结果可视化函数:
def visualization(image, bboxes, scores, cls_inds, labels, thr=0.3):
# Generate colors for drawing bounding boxes.
hsv_tuples = [(x / float(len(labels)), 1., 1.) for x in range(len(labels))]
colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples))
colors = list(map(lambda x: (int(x[0] * 255), int(x[1] * 255), int(x[2] * 255)), colors))
random.seed(10101) # Fixed seed for consistent colors across runs.
random.shuffle(colors) # Shuffle colors to decorrelate adjacent classes.
random.seed(None) # Reset seed to default.
# draw image
imgcv = np.copy(image)
h, w, _ = imgcv.shape
for i, box in enumerate(bboxes):
if scores[i] < thr:
continue
cls_indx = cls_inds[i]
thick = int((h + w) / 300)
cv2.rectangle(imgcv, (int(box[0]), int(box[1])), (int(box[2]), int(box[3])), colors[0], thick)
mess = '%s: %.3f' % (labels[0], scores[i])
if box[1] < 20:
text_loc = (int(box[0] + 2), int(box[1] + 15))
else:
text_loc = (int(box[0]), int(box[1] - 10))
cv2.putText(imgcv, mess, text_loc, cv2.FONT_HERSHEY_SIMPLEX, 1e-3 * h, (255, 255, 255), thick // 3)
return imgcv测试Demo:















 902
902











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









