






Complex-YOLO是2018年的一篇点云目标检测的文章,发表于arXiv[cs.CV]。
文章链接:An Euler-Region-Proposal for Real-time 3D Object Detection on Point Clouds
核心思想:
本文基于YOLOv2版本的变异,通过把3D点云降维到2D鸟瞰图的方式,将图像检测的网络用于点云的目标检测中。出于降维后信息的损失考虑,本文采用点云多种特征综合起来填充输入通道,以达到目标信息的弥补。
框架结构:
网络仍然以三通道作为输出,区别与图片中的RGB色系不同,这里先将三维点云进行栅格化,将点集分布到鸟瞰图空间的网格中,然后编码网格内点集的最大高度,最大强度,点云密度三种信息归一化后分别填充到R,G,B三个通道中形成RGB-Map,然后采用YOLOv2的Darknet19进行特征提取并回归出目标的相对中心点
 ,
,
 ;相对宽高
;相对宽高
 ,
,
 ;复角
;复角
 ,
,
 ,以及类别
,以及类别
 。如下图所示:
。如下图所示:
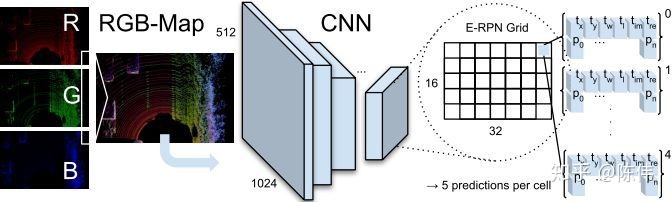
实现细节:
点云预处理:本文将单帧三维点云转换成一张俯视的三通道图片,帅选出传感器正前方ROI区域(80米x 40米)高度限定3米以内,并将点云栅格化到网格分辨率为8cm的二维网格图中:
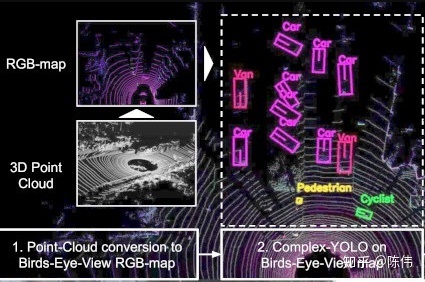
三通道分别由点云高度信息、点云强度信息、点云密度信息编码所得,编码方式如下:
![z_{g}(S_{j}) = max(P_{\Omega i\rightarrow j} \cdot [0, 0, 1]^{T})](https://i-blog.csdnimg.cn/blog_migrate/95d23df151f1138b8c1b774c6213c22f.png)


其中
 表示最大高度,
表示最大高度,
 表示最大强度,
表示最大强度,
 表示网格内归一化的密度,
表示网格内归一化的密度,
 每个网格内的点云映射函数,
每个网格内的点云映射函数,
 表示感兴趣区域范围内的所有点集。
表示感兴趣区域范围内的所有点集。
网络结构:本文的网络结构在YOLOv2版本的基础上使用E-RPN进行扩展。基本同Darket-19,只是在最后的输出层增加了两个复数角度的回归,如下图所示:
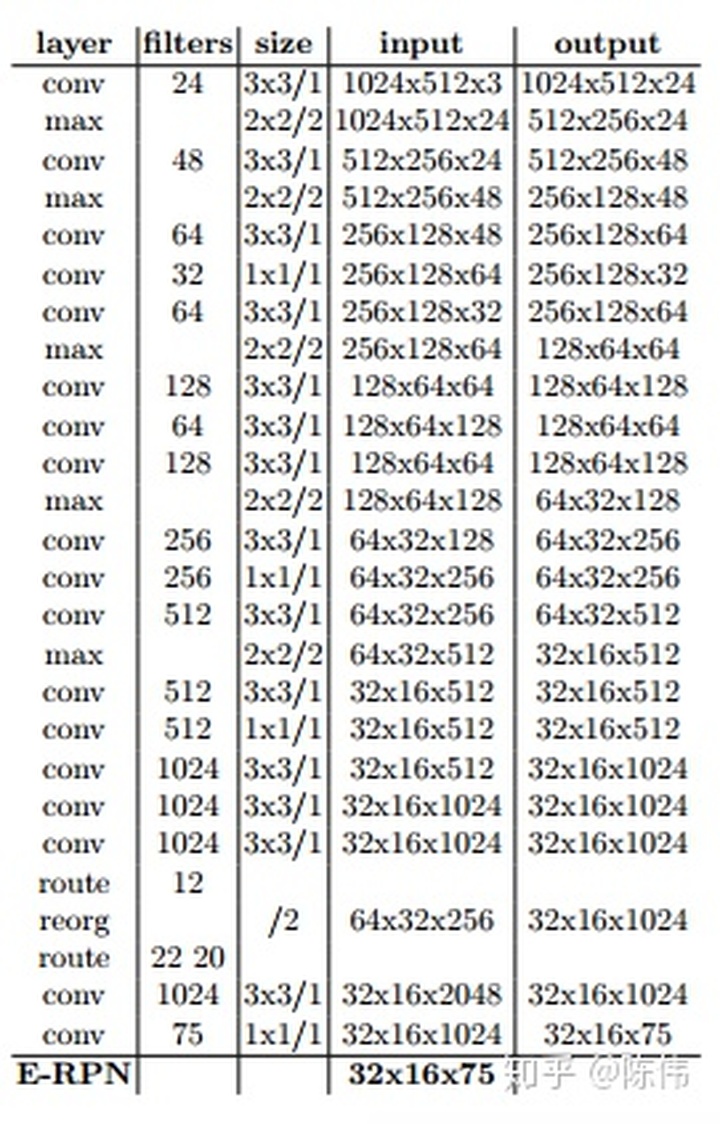
将网络输出的特征图解码成目标的3D位置,大小,类别概率和朝向角:





其中预测的中心点
,
通过sigmoid函数归一化到每个网格的相对位置,
 ,
,
 为输出特征图上网格索引位置,预测的长宽
,
通过对数函数表征的是相对于anchor长宽
为输出特征图上网格索引位置,预测的长宽
,
通过对数函数表征的是相对于anchor长宽
 ,
,
 的偏移,预测的复数实部和虚部通过反正切求得朝向角。
的偏移,预测的复数实部和虚部通过反正切求得朝向角。
锚点设计:考虑在鸟瞰图视角下,同一类目标的长宽尺寸变化不大,但是目标存在方向信息,所以在设计锚点的时候,本文根据数据集内的外接框分布,定义了三种不同尺寸和两个角度方向:i)车辆尺寸(朝上);i i)车辆尺寸(朝下);i i i)自行车尺寸(朝上);i v)自行车尺寸(朝下);v)行人尺寸(朝左)。
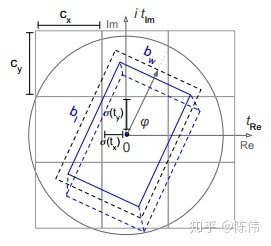
复角回归:目标的朝向角
 可以通过相应的回归参数
和
计算得出,他们对应于复数的相位,角度只需使用
可以通过相应的回归参数
和
计算得出,他们对应于复数的相位,角度只需使用
 即可求出。采用复数的方式主要考虑:
即可求出。采用复数的方式主要考虑:
- 避免奇异性;
- 在一个封闭的数学空间,能对模型的推广产生有利影响;
损失函数:本文的损失函数在YOLO的基础上增加了欧拉角度回归损失,使用复数进行角度回归,总体上来说叠加的比较生硬,我们知道后面的版本将中心点和宽高放在一起保留bbox完整性然后计算损失,如果能把旋转角也和bbox其他属性整合在一个定位损失中会更好,下面是本文的损失函数:

YOLO自身的损失如下:

Euler角度损失如下:
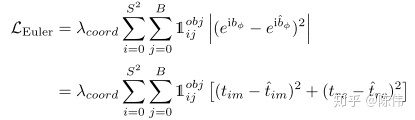
要点分析:
- 将图像检测网络YOLOv2应用到点云检测中,把三维点云转换成鸟瞰图的形式作为输入;
- 编码点云的高度,强度,密度信息到输入通道中;
- 在网络输出的位置信息,尺度信息,类别信息后增加了角度信息的输出;
- 采用复角的方式表征朝向角避免了单纯回归一个值所存在的奇异值问题(0°突变360°);
实验结果:
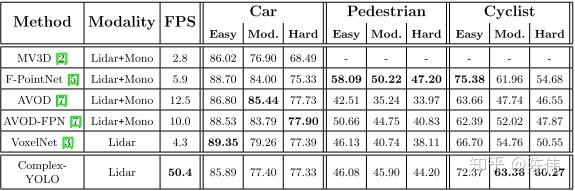
从下表中可以明显的看出该方法的速度确实快,毕竟是基于单阶段的YOLO系列,但是这个速度应该是纯网络预测耗时,其点云转换成鸟瞰图部分还会消耗一部分时间:
思考与展望:
- 很多点云检测网络在其预处理部分需要消耗大量精力时间,本文也不例外,虽然网络的前向传播时效性比较好(或者升级到v5版本),但是对点云的预处理部分仍然拖累整体耗时;
- 采用鸟瞰图形式的检测,由于点云近密远稀的特征,限制了其有效检测距离,所以本文只在40M以内的效果比较好;
代码复现:
由于采用的YOLOv2框架,所以大致代码与之前的v2实践篇基本相同,这里贴出点云数据预处理的部分:
def load_pcd(self, pcd_path):
pts = []
f = open(pcd_path, 'r')
data = f.readlines()
f.close()
line = data[9].strip('\n')
pts_num = eval(line.split(' ')[-1])
for line in data[11:]:
line = line.strip('\n')
xyzi = line.split(' ')
x, y, z, i = [eval(i) for i in xyzi[:4]]
pts.append([x, y, z, i])
assert len(pts) == pts_num
res = np.zeros((pts_num, len(pts[0])), dtype=np.float)
for i in range(pts_num):
res[i] = pts[i]
return res
def scale_to_255(self, a, min, max, dtype=np.uint8):
return (((a - min) / float(max - min)) * 255).astype(dtype)
def calc_xyz(self, data):
center_x = (data[16] + data[19] + data[22] + data[25]) / 4.0
center_y = (data[17] + data[20] + data[23] + data[26]) / 4.0
center_z = (data[18] + data[21] + data[24] + data[27]) / 4.0
return center_x, center_y, center_z
def calc_hwl(self, data):
height = (data[15] - data[27])
width = math.sqrt(math.pow((data[17] - data[26]), 2) + math.pow((data[16] - data[25]), 2))
length = math.sqrt(math.pow((data[17] - data[20]), 2) + math.pow((data[16] - data[19]), 2))
return height, width, length
def calc_yaw(self, data):
angle = math.atan2(data[17] - data[26], data[16] - data[25])
if (angle < -1.57):
return angle + 3.14 * 1.5
else:
return angle - 1.57
def cls_type_to_id(self, data):
type = data[1]
if type not in model_params['classes']:
return -1
return model_params['classes'].index(type)
def calc_angle(self, im, re):
"""
param: im(float): imaginary parts of the plural
param: re(float): real parts of the plural
return: The angle at which the objects rotate
around the Z axis in the velodyne coordinate system
"""
if re > 0:
return np.arctan(im / re)
elif im < 0:
return -np.pi + np.arctan(im / re)
else:
return np.pi + np.arctan(im / re)
def load_label(self, label_path):
lines = [line.rstrip() for line in open(label_path)]
label_list = []
for line in lines:
data = line.split(' ')
data[4:] = [float(t) for t in data[4:]]
type = data[1]
if type not in model_params['classes']:
continue
label = np.zeros([8], dtype=np.float32)
label[0], label[1], label[2] = self.calc_xyz(data)
label[3], label[4], label[5] = self.calc_hwl(data)
label[6] = self.calc_yaw(data)
label[7] = self.cls_type_to_id(data)
label_list.append(label)
return np.array(label_list)
def transform_bev_label(self, label):
image_width = (self.y_max - self.y_min) / self.voxel_size
image_height = (self.x_max - self.x_min) / self.voxel_size
boxes_list = []
boxes_num = label.shape[0]
for i in range(boxes_num):
center_x = (-label[i][1] / self.voxel_size).astype(np.int32) - int(np.floor(self.y_min / self.voxel_size))
center_y = (-label[i][0] / self.voxel_size).astype(np.int32) + int(np.ceil(self.x_max / self.voxel_size))
width = label[i][4] / self.voxel_size
height = label[i][5] / self.voxel_size
left = center_x - width / 2
right = center_x + width / 2
top = center_y - height / 2
bottom = center_y + height / 2
if ((left > image_width) or right < 0 or (top > image_height) or bottom < 0):
continue
if (left < 0):
center_x = (0 + right) / 2
width = 0 + right
if (right > image_width):
center_x = (image_width + left) / 2
width = image_width - left
if (top < 0):
center_y = (0 + bottom) / 2
height = 0 + bottom
if (bottom > image_height):
center_y = (top + image_height) / 2
height = image_height - top
box = [center_x, center_y, width, height, label[i][6], label[i][7]]
boxes_list.append(box)
while len(boxes_list) < 300:
boxes_list.append([0.0, 0.0, 0.0, 0.0, 0.0, 0.0])
return np.array(boxes_list, dtype=np.float32)
def transform_bev_image(self, pts):
x_points = pts[:, 0]
y_points = pts[:, 1]
z_points = pts[:, 2]
i_points = pts[:, 3]
# convert to pixel position values
x_img = (-y_points / self.voxel_size).astype(np.int32) # x axis is -y in LIDAR
y_img = (-x_points / self.voxel_size).astype(np.int32) # y axis is -x in LIDAR
# shift pixels to (0, 0)
x_img -= int(np.floor(self.y_min / self.voxel_size))
y_img += int(np.floor(self.x_max / self.voxel_size))
# clip height value
pixel_values = np.clip(a=z_points, a_min=self.z_min, a_max=self.z_max)
# rescale the height values
pixel_values = self.scale_to_255(pixel_values, min=self.z_min, max=self.z_max)
# initalize empty array
x_max = math.ceil((self.y_max - self.y_min) / self.voxel_size)
y_max = math.ceil((self.x_max - self.x_min) / self.voxel_size)
# Height Map & Intensity Map & Density Map
height_map = np.zeros((y_max, x_max), dtype=np.float32)
intensity_map = np.zeros((y_max, x_max), dtype=np.float32)
density_map = np.zeros((y_max, x_max), dtype=np.float32)
for k in range(0, len(pixel_values)):
if pixel_values[k] > height_map[y_img[k], x_img[k]]:
height_map[y_img[k], x_img[k]] = pixel_values[k]
if i_points[k] > intensity_map[y_img[k], x_img[k]]:
intensity_map[y_img[k], x_img[k]] = i_points[k]
density_map[y_img[k], x_img[k]] += 1
for j in range(0, y_max):
for i in range(0, x_max):
if density_map[j, i] > 0:
density_map[j, i] = np.minimum(1.0, np.log(density_map[j, i] + 1) / np.log(64))
height_map /= 255.0
intensity_map /= 255.0
rgb_map = np.zeros((y_max, x_max, 3), dtype=np.float32)
rgb_map[:, :, 0] = density_map # r_map
rgb_map[:, :, 1] = height_map # g_map
rgb_map[:, :, 2] = intensity_map # b_map
return rgb_map
def filter_roi(self, pts):
mask = np.where((pts[:, 0] >= self.x_min) & (pts[:, 0] <= self.x_max) &
(pts[:, 1] >= self.y_min) & (pts[:, 1] <= self.y_max) &
(pts[:, 2] >= self.z_min) & (pts[:, 2] <= self.z_max))
pts = pts[mask]
return pts
大致流程是采用load_pcd函数加载待训练的pcd数据,通过calc_xyz,calc_hwl,calc_yaw等函数从txt文件中读取标签信息,然后调用transform_bev_image将三维点云编码成鸟瞰图空间高度,强度,密度三通道,调用transform_bev_label将标签转换到鸟瞰图中待输入的标签。鸟瞰图预测如下:


















 1781
1781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









