






 Deep3DBox是一种经典的单目3D目标检测方法,通过深度学习回归目标的3D特性,结合几何约束估计3D位姿。使用MS-CNN检测2D目标,VGG网络回归3D尺寸和方向,最小二乘法解算3D中心。
Deep3DBox是一种经典的单目3D目标检测方法,通过深度学习回归目标的3D特性,结合几何约束估计3D位姿。使用MS-CNN检测2D目标,VGG网络回归3D尺寸和方向,最小二乘法解算3D中心。
Deep3DBox是早期的一篇来自于CVPR上经典的单目3D检测的文章《3D Bounding Box Estimation Using Deep Learning and Geometry》
文章链接:CSDL | IEEE Computer Society
核心思想:
首先使用深度神经网络回归出相对稳定的3D目标的特性,再利用估计出来的3D特征和由2D bounding box转换为3D bounding box时的几何约束来产生最终的结果。文章先回归方向和尺寸,再结合几何约束产生3D位姿。
第一层网络输出一个混合离散-连续损失(MultiBin)来表示3D物体的方向,这个损失优于L2.
第二层网络回归3D物体的尺寸(可以从很多物体类别中得到先验)
框架结构:
文章实现了从单目图像预测目标物体3D位置、大小以及朝向的功能。整个算法框架分为三个部分:
1、2D图像目标检测网络:文章采用MS-CNN网络检测2D目标,
2、目标大小姿态估计网络:获取2D检测框之后将其截取出来Resize到224x244,送入VGG网络来回归3D包围框的长宽高以及朝向角
3、目标3D中心点解算模块:利用预测的长宽高以及角度的几何投影的关系来求解一个最小二乘方程组计算3D包围框中心点的三维坐标(相机坐标系)
值得注意的是也可以把一二部分结合起来,在目标检测网络后面直接加了大小和朝向的回归分支,所以整体框架又可以理解为:2D图像目标检测以及大小姿态估计网络+目标3D中心点解算模块。
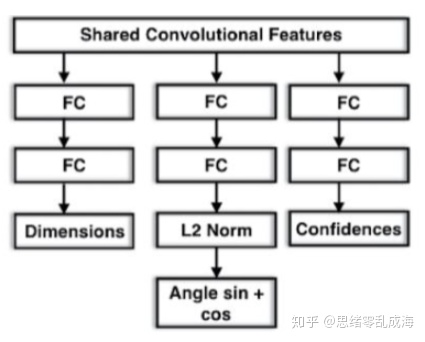
上图的CNN参数估计模型的结构在公共的特征图后网络有三个分支,分别估计3D物体的长宽高、每个Bin的置信度和每个Bin的角度估计。所有的分支得到相同的卷积特征,并且所有的损害权重结合为:

实现细节:
2D box的回归:文中采用MS-CNN网络进行2D检测,该网络类似RCNN系列,分为proposal提取ROI和目标检测两个部分。该检测器的设计之初是为了解决目标大小不一致的问题,采用的多尺度目标检测器能够解决这种目标大小与感受野不一致的现象,每一个检测层只着重检测与这一层尺寸相匹配的目标。
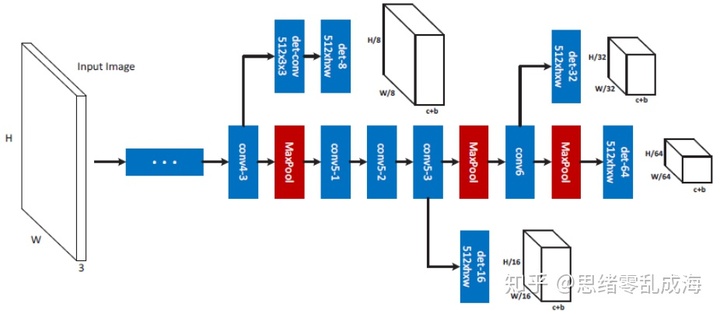
中间是网络的主干,在一些卷积层中带有分支结构。其中每个分支都是一个单一尺度的目标检测器。
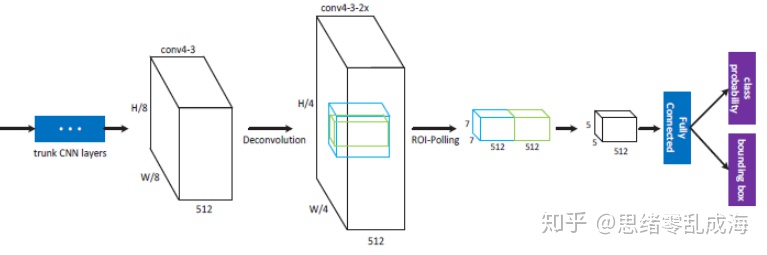
绿色框代表检测到的目标候选框,蓝色框为带有该目标的上下文信息的候选框,其中蓝色框为绿色框的1.5倍,通过将这两个框进行堆叠,在通过一个降维卷积层将冗余的信息进行压缩,在不损失准确率的情况下减少了参数。
3D box的长宽高回归:在 KITTI 数据库中,车,货车,卡车 和 公交车都是不同的类并且不同类的区分方差很小且单峰,所以直接使用 L2损失。首先对不同类别的物体统计真实尺寸,获得每个类别的先验长宽高,通过网络回归真实物体尺寸相对于该类物体先验的残差:

 代表真实尺寸,
代表真实尺寸,
 代表该类物体的先验尺寸,
代表该类物体的先验尺寸,
 代表要拟合的残差。
代表要拟合的残差。
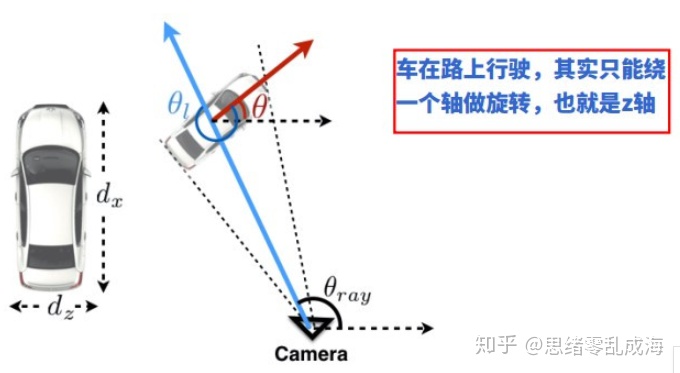
角度回归:估计全局物体方向角 R 需要相机的参考帧中检测窗口的crop和 crop 的位置。考虑到R(θ)参数只由 θ(yaw) 决定。下图是一辆车沿直线行驶的例子。尽管全局的方向R(θ) 没有变,但是它的局部角 θ( 全局方向和相机中心穿过 crop 中心的射线形成的角度) 一直在改变。

因此我们需要回归局部角 θ,下图展示了局部角 θ 和射线角度变化的关系由全局角约束。给定相机的内参,射线的具体像素可以不用计算。我们通过结合射线的防线和局部角来计算物体的全局角。
文章提出MultiBin的结构来进行姿态的估计,首先离散化旋转角到N个重叠的Bin,对个每一个Bin,CNN网络估计出姿态角度在当前Bin的概率,同时估计出角度值的Cos和Sin值。
还有一个注意点是,回归角度的分支实际是回归角度的正弦值以及余弦值,需要在fc层后加上L2 norm,因为这样才归一化到三角函数的值域范围。
3D box解算:已知相机内参矩阵:
![K = \left[ \begin{array}{ccc} f_{x} & 0 & c_{x} \\ 0 & f_{y} & c_{y} \\ 0 & 0 & 1 \\ \end{array} \right ]](https://i-blog.csdnimg.cn/blog_migrate/c1e46439539b74541a3f0971c0964eaf.png)
从目标坐标系(三维框中心为原点,向前为z轴正方向,向右是x轴正方向,向下为y轴正方向)转到相机系(与KITTI的定义一样,向前为z轴正方向,向右是x轴正方向,向下为y轴正方向)的旋转矩阵为:
![R = \left[ \begin{array}{ccc} r_{0} & r_{1} & r_{2} \\ r_{3} & r_{4} & r_{5} \\ r_{6} & r_{7} & r_{8} \\ \end{array} \right ]](https://i-blog.csdnimg.cn/blog_migrate/724f6b4fdc91ef36a13cb929506f0d27.png)
目标系原点在相机系中的坐标为:
![T = \left[ \begin{array}{ccc} T_{x}\\ T_{y} \\ T_{z} \\ \end{array} \right ]](https://i-blog.csdnimg.cn/blog_migrate/2702f20f01b65df84527c7edc54a7df7.png)
则目标三维框的8个顶点可以用下面的公式转化为平面的图像坐标:
![\lambda \left[ \begin{array}{ccc} x\\ y \\ z \\ \end{array} \right ] = K(R\left[ \begin{array}{ccc} X\\ Y \\ Z \\ \end{array} \right ]+T)](https://i-blog.csdnimg.cn/blog_migrate/035b86e54fa8bbe47b980566257f1dac.png)
其中,[X,Y,Z]为目标系中三维框顶点坐标,[x,y]为投影到图像坐标系的坐标,
 为归一化因子。把上面公式的右边换一个写法:
为归一化因子。把上面公式的右边换一个写法:
![K \left[ \begin{array}{ccc} 1 & 0 & 0 & r_{0}X+r_{1}Y + r_{2}Z\\ 0 & 1 & 0 & r_{3}X+r_{4}Y + r_{5}Z\\ 0 & 0 & 0 & r_{6}X+r_{7}Y + r_{8}Z\\ \end{array} \right ]\left[ \begin{array}{ccc} T_{x}\\ T_{y}\\ T_{z}\\ 1\\ \end{array} \right ]](https://i-blog.csdnimg.cn/blog_migrate/eb11685ca33b6540041db4d6f549d83d.png)
注意R可以用r_y角求得,[X,Y,Z]可以直接根据预测的H、W、L写出来,而[x,y]是由2D目标检测网络检测得到的2维框顶点坐标,所以这里未知数是[Tx,Ty,Tz]。
上面又可以写为:
![\left[ \begin{array}{ccc} m_{0} & m_{1} & m_{2} & m_{3}\\ m_{4} & m_{5} & m_{6} & m_{7}\\ m_{8} & m_{9} & m_{10} & m_{11}\\ \end{array} \right ]\left[ \begin{array}{ccc} T_{x}\\ T_{y}\\ T_{z}\\ 1\\ \end{array} \right ]](https://i-blog.csdnimg.cn/blog_migrate/da5ede27568e0421674218f4de4e24a4.png)
展开后有:


文中假设三维框的顶点投影到图上应该包含在图像目标2维框内,故8个点投影出的x的最小值应该等于2D框的最小的x,即左上点的x坐标;8个点投影出的y的最小值应该等于2D框的最小的y,即左上点的y坐标;8个点投影出的x的最大值应该等于2D框的最大的x,即右下点的x坐标;8个点投影出的y的最大值应该等于2D框的最大的y,即右下点的y坐标。故共有4个方程,求解用最小二乘即可。
要点分析:
1. 通过2D bounding box (方向和大小由CNN产生) 和几何约束估计物体3D位姿和尺寸。
2. 采用MultiBin回归的离散-连续 CNN 结构用来估计物体的方向。
3. 提出三个额外的判断3D box精度效果指标:box 中心离相机的距离,最近的bounding box 离相机的距离,所有的bounding box 跟ground truth 的 overlap(通过 3D intersection over Union (3DIoU))。
实验结果:

思考与展望:
文章的思路是将深度学习和多视几何相结合起来用2D检测加上几何约束回归3D信息,但是3D定位精度本质上受限于重投影误差, 2D box 的定位精度是有限的,所以瓶颈明显。
其一是部分目标有一部分出现在图像内一部分出现在图像外时,3D框是不准的,因为在求解三维位置时,假设了2D框的中心是3D框中心的投影。
其二是与2D目标检测器的位置回归精度有强依赖。
当然区别与该思路的其他方法有两个:
其一是走立体匹配的路线,先要做深度估计,然后可以直接使用深度图也可以转换成伪点云使用;
其二是结合时间信息在视频中完成物体的位姿和速度的预测;

















 3638
3638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









