







这篇文章是2017年ICCV的一篇文章《Convolutional-De-Convolutional Networks for Precise Temporal Action Localization in Untrimmed Videos》,下面是这篇文章的主要贡献点。
- 第一次将卷积、反卷积操作应用到行为检测领域,文章同时在空间下采样,在时间域上上采样。
- 利用CDC网络结果可以做到端到端的学习
- 这篇文章可以做到per-frame action lableling,也就是每一帧都可以做预测。而且取到了现在的state-of-art结果
一、网络结构
这篇文章的网络结构其实是比较简单的。假设都已经知道了C3D网络,不知道可以移步到:http://vlg.cs.dartmouth.edu/c3d/ 。这篇文章在C3D网络上做了改进,改进后的网络结构如下图所示。
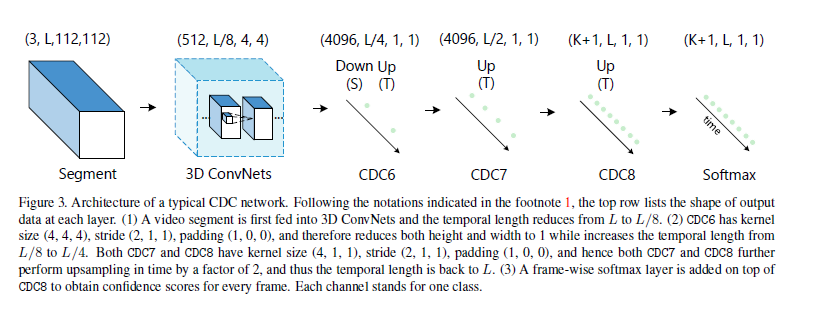
网络步骤如下所示。
- 输入的视频段是112x112xL,连续L帧112x112的图像
- 经过C3D网络后,时间域上L下采样到 L/8, 空间上图像的大小由 112x112下采样到了4x4
- CDC6: 时间域上上采样到 L/4, 空间上继续下采样到 1x1
- CDC7: 时间域上上采样到 L/2
- CDC8:时间域上上采样到 L,而且全连接层用的是 4096xK+1, K是类别数
- softmax层
二、设计细节
这里主要阐述作者对于CDC
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1632
1632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









