







 本文介绍了ICCV 2017论文中提出的R-C3D网络,该网络基于C3D并借鉴Faster RCNN,能对任意长度视频进行行为检测。网络包括特征提取、时序提案子网、活动分类子网和损失函数四个部分。通过共享参数,R-C3D在THUMOS'14、ActivityNet和Charades等数据集上表现出良好的性能和高效的速度。
本文介绍了ICCV 2017论文中提出的R-C3D网络,该网络基于C3D并借鉴Faster RCNN,能对任意长度视频进行行为检测。网络包括特征提取、时序提案子网、活动分类子网和损失函数四个部分。通过共享参数,R-C3D在THUMOS'14、ActivityNet和Charades等数据集上表现出良好的性能和高效的速度。
这篇文章是ICCV 2017的一篇文章,作者主要是以C3D网络为基础。借鉴了Faster RCNN的思路,对于任意的输入视频L,先进行proposal,然后3D-pooling,最后后进行分类和回归操作。文章主要贡献点有3个:
- 可以针对任意长度视频、任意长度行为进行端到端的检测
- 速度很快(是目前网络的5倍),通过共享Progposal generation 和Classification网络的C3D参数
- 作者测试了3个不同的数据集,效果都很好,显示了通用性。
一、网络结构
整个网络可以分为四个部分:
- 特征提取网络:对于输入任意长度的视频进行特征提取
- Temporal Proposal Subnet: 用来提取可能存在行为的时序片段(Proposal Segments)
- Activity Classification Subnet: 行为分类子网络
- Loss Function
下图是整个网络结构图。
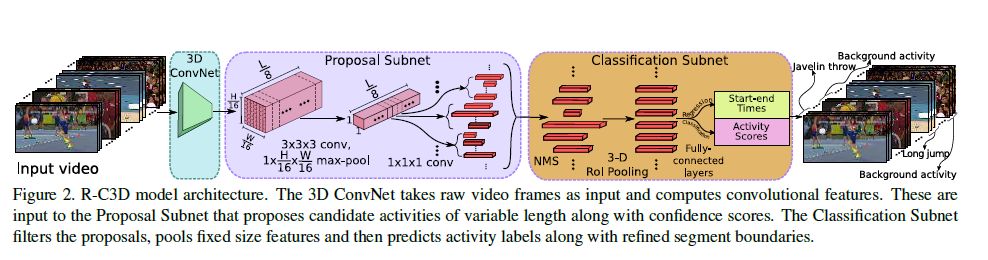
1.1 特征提取网络
骨干网络作者选择了C3D网络,经过C3D网络的5层卷积后,可以得到512 x L/8 x H/16 x W/16大小的特征图。这里不同于C3D网络的是,R-C3D允许任意长度的视频L作为输入。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









