






WordCloud 词云 + LDA 主题模型

何小嫚&刘峰原图.jpg

人物词云效果.jpg
电影《芳华》在春节重映了一波,加上之前的热映,最终取得了 14 亿票房的好成绩。严歌苓的原著也因此被更多的人细细品读。用文本分析的一些技术肢解小说向来是自然语言处理领域的一大噱头,这次当然也不能放过,本篇达成的成就有:
1、提取两大主角刘峰和何小嫚(萍)的关键词并绘制好看的人物词云;
2、以章节为单位探索小说的主题分布并画图展示。
主要功能包:
jieba
lda
wordcloud
seaborn
安装命令: pip install ***
需要的外部文件:
- 小说全文, 芳华-严歌苓.txt
- 中文停用词,stopwords.txt
- 小说人物名称,person.txt,作为 jieba 的用户自定义词典
- 两个人物的 png 图片
- 你喜欢的中文字体的 ttf 文件,我用的楷体
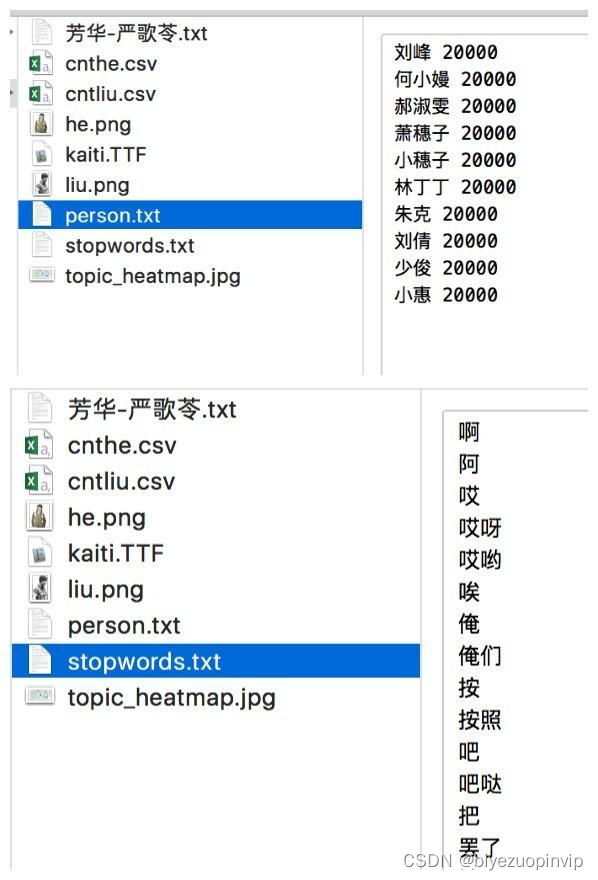
人物名和停用词文件示例.jpg
文本预处理
分词,并过滤无意义词
文本挖掘的必备步骤,毕竟理解中文的最小单位是词汇。这里没有使用简单的 jieba.cut 进行分词,因为我们需要知道单词的词性,便于稍后根据词性过滤不重要的词。
采用 jieba.posseg.cut 分词可以输出词性。我们并不能拍脑门决定是要动词还是名词等等,词性有非常多个,我把全部分词结果按照词性分好类,看了一下每个词性对应哪些词,最后决定保留词性为[“a”, “v”, “x”, “n”, “an”, “vn”, “nz”, “nt”, “nr”]的词,例如图中,m 代表量词,这是对语义没有帮助的词,应该舍弃。
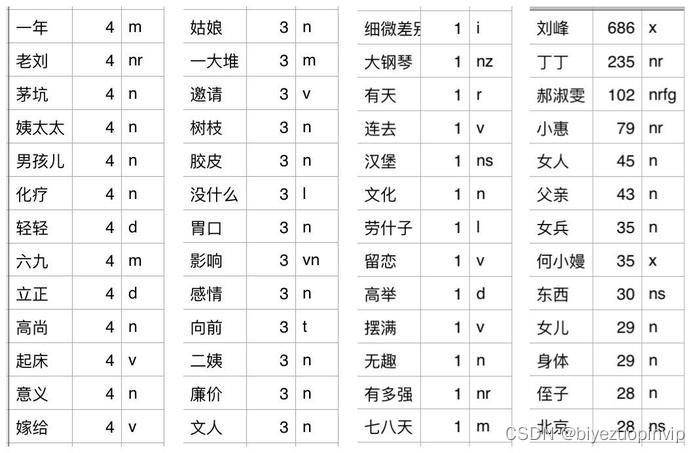
词性示例.jpg
import jieba.posseg
jieba.load_userdict("data/person.txt")
STOP_WORDS = set([w.strip() for w in open("data/stopwords.txt").readlines()])
def cut_words_with_pos(text):
seg = jieba.posseg.cut(text)
res = []
for i in seg:
if i.flag in ["a", "v", "x", "n", "an", "vn", "nz", "nt", "nr"] and is_fine_word(i.word):
res.append(i.word)
return list(res)
# 过滤词长,过滤停用词,只保留中文
def is_fine_word(word, min_length=2):
rule = re.compile(r"^[\u4e00-\u9fa5]+$")
if len(word) >= min_length and word not in STOP_WORDS and re.search(rule, word):
return True
else:
return False
划分章节
我们按照“第*章”这样的字眼将小说的不同章节分割开来,作为独立的文档,用于之后的主题分析。定义了一个名为 MyChapters 的生成器,存储每章分好的词汇,是为了避免章节过多带来的一些程序运行问题。其实《芳华》仅有 15 章,用一个简单的列表也是可以的。
class MyChapters(object):
def __init__(self, chapter_list):
self.chapter_list = chapter_list
def __iter__(self):
for chapter in self.chapter_list:
yield cut_words_with_pos(chapter)
def split_by_chapter(filepath):
text = open(filepath).read()
chapter_list = re.split(r'第.{1,3}章\n', text)[1:]
return chapter_list
人物关键词提取
要提取人物关键词,首先要解决的问题是,在不借助外部的人物描述(比如百度百科和豆瓣电影上的角色介绍)的情况下,如何确定跟这个人物相关的内容。这里采用的比较简单的策略是,对小说文件中的每一行,如果该人物的名称存在,则将该行加入到此人的相关语料中去。再以此为基础统计词频,结果大致 ok,为了人物词云更精确的展示,我将词频输出到了文件,手动删除了一些词,并简单调整了一些词的词频,下图是调整过后的词和词频,左为何小嫚,右为刘峰。
import pandas as pd
def person_word(name):
lines = open("data/芳华-严歌苓.txt", "r").readlines()
word_list = []
for line in lines:
if name in line:
words = cut_words_with_pos(line)
word_list += words
# 统计词频并按照词频由大到小排序,取top500
cnt = pd.Series(word_list).value_counts().head(500)
# 可以把结果输出到文件,进行一些手动调整
# cnt.to_csv("data/cntliu.csv")
# 返回字典格式
return cnt.to_dict()
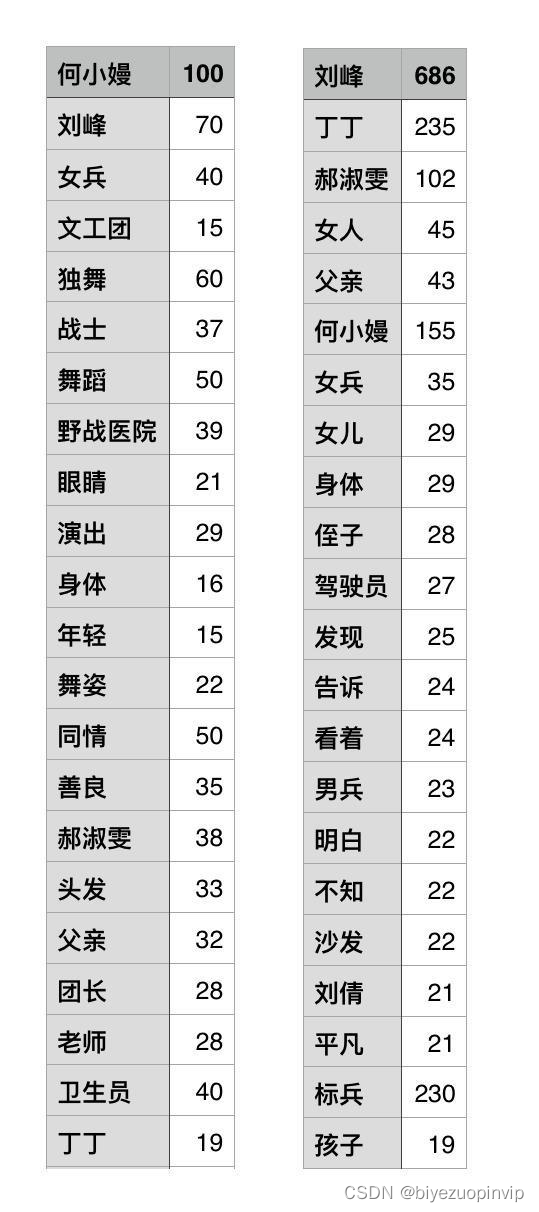
人物关键词提取结果示例.jpg
词云绘制
python 有 wordcloud 包可以用于词云绘制,在使用过程中需要注意:
用于定义形状的外部图片必须是 png 格式,默认纯白色部分为非图像区域;
中文词云必须载入一个字体文件;
字的颜色可以自己定义,也可以使用图片本身的底色。本例中何小嫚的图片 底色很鲜艳明晰,可以用本身的底色(ImageColorGenerator);而刘峰的图片是单色,且色浅,我使用了自定义颜色(my_color_func);
绘制词云需要用到的数据格式为 dict,key 为词,value 为词频,词频越大,在图片中的字体越大。
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator
from scipy.misc import imread
from random import choice
# 定义颜色,方法很多,这里用到的方法是在四个颜色中随机抽取
def my_color_func(word, font_size, position, orientation, random_state=None, **kwargs):
return choice(["rgb(94,38,18)", "rgb(41,36,33)", "rgb(128,128,105)", "rgb(112,128,105)"])
def draw_cloud(mask_path, word_freq, save_path):
mask = imread(mask_path) #读取图片
wc = WordCloud(font_path='data/kaiti.TTF', # 设置字体
background_color="white", # 背景颜色
max_words=500, # 词云显示的最大词数
mask=mask, # 设置背景图片
max_font_size=80, # 字体最大值
random_state=42,
)
# generate_from_frequencies方法,从词频产生词云输入
wc.generate_from_frequencies(word_freq)
plt.figure()
# 刘峰, 采用自定义颜色
plt.imshow(wc.recolor(color_func=my_color_func), interpolation='bilinear')
# 何小嫚, 采用图片底色
# image_colors = ImageColorGenerator(mask)
# plt.imshow(wc.recolor(color_func=image_colors), interpolation='bilinear')
plt.axis("off")
wc.to_file(save_path)
plt.show()
# 获取关键词及词频
input_freq = person_word("刘峰")
# 经过手动调整过的词频文件,供参考
# freq = pd.read_csv("data/cntliu.csv", header=None, index_col=0)
# input_freq = freq[1].to_dict()
draw_cloud("data/liu.png", input_freq, "output/liufeng.png")
对人物进行抠图,背景设置为纯白,存储为 png 格式。
为了使形状更鲜明,对小嫚的辫子还有腰的部分做了加白处理,可以对比文章开头原图感受一下。

何小嫚&刘峰用作生成词云的图片.jpg

人物词云效果.jpg

















 1286
1286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









