






 本文深入探讨支持向量机(SVM)的理论基础,包括统计学习理论、最优分类超平面、核函数和各种训练算法,如二次规划、SMO等。SVM在模式识别和数据挖掘中的应用得到广泛关注,特别是其在处理高维数据和优化问题上的优势。当前研究焦点在于算法的改进、支持向量回归以及多值分类等方向。
本文深入探讨支持向量机(SVM)的理论基础,包括统计学习理论、最优分类超平面、核函数和各种训练算法,如二次规划、SMO等。SVM在模式识别和数据挖掘中的应用得到广泛关注,特别是其在处理高维数据和优化问题上的优势。当前研究焦点在于算法的改进、支持向量回归以及多值分类等方向。
目 录
- 绪论 1
1.1支持向量机的研究背景、意义 1
1.2 SVM算法研究现状 2
1.3 论文内容及结构安排 4 - 统计学习理论基础 4
2.1 学习问题的表示 4
2.2 期望风险、经验风险 5
2.3 学习过程一致性的条件 6
2.4 VC维理论 7
2.5 推广性的界 9
2.6 结构风险最小化 11 - 支持向量机理论基础 13
3.1 最优分类超平面 13
3.2 线性可分 14
3.3 线性不可分 16
3.4 核函数 17 - SVM训练算法 18
4.1 停机准则 19
4.2 二次规划算法 21
4.3 分解算法 23
4.3.1Chunking算法 23
4.3.2SVMLight算法 24
4.3.3SMO算法 26
4.4 增量算法 27 - SMO算法 28
5.1 SMO算法的理论基础 28
5.2 两变量的二次规划子问题 30
5.3 一次成功优化后相关变量的更新 34
5.4 待优化变量的选择及smo算法步骤 36
1.2 SVM算法研究现状
SVM是由Vapnik领导的AT&TBell实验室研究小组提出的分类技术,它开辟了学习高维数据新的天地,这种新的学习算法可以替代多层感知器、RBF神经网络和多项式神经网络等传统的学习算法,也是一种可实现一些表示问题的建设性方法。在多层感知器、RBF神经网络和小波神经网络中都有成功的运用,同时SVM方法在实际中的一些应用,如人脸识别和信号处理等都说明了VC理论的使用价值。
目前在国外,SVM已是一个研究的热门,并且已经取得了不少研究成果。但在国内,SVM的研究才刚刚发展起来。对SVM的研究主要包括下面几个方面:
(1)SVM算法的改进
对SVM算法的改进是目前SVM研究的主要内容,也是本文要介绍的主要内容。
(2)新型支持向量机的研究
基于惩罚常数的支持向量机有两个相互矛盾的目标,即:最大化间隔和最小化训练误差。其中惩罚常数C起着调和这两个目标的作用,但C没有明确的物理意义,所以C的选取比较困难。为此,Scholkopf B提出了另外一种类型的支持向量机:y - svm,它用另外一个参数Y代替了参数C,而这个参数具有一些直观的物理意义,其具体的几何意义请参见D.j.Crisp的论文。
(3)支持向量回归
支持向量的方法也可应用于回归问题中,具有很好的效果。
(4)多值分类的研究
SVM方法的基本理论只考虑了二值分类,如何进行多值分类,主要有以下方案:
一一区分模式,对n个分类的训练集进行两两区分;
逐一鉴别模式,仅构造n个SVM,每一个SVM分别将某一类数据从其他分类数据集中鉴别出来;
对SVM分类机理进行改革,适用于多类情况。
(5)应用研究
虽然SVM方法在理论上具有很突出的优势,但与其理论研究相比,应用研究尚还是相对比较落后的,只是在最近几年,应用研究才逐渐地多起来。在模式识别领域,包括手写体数字识别、人脸识别、语音识别、目标识别、文本分类等方面,取得了一定的成果。在数据挖掘领域,支持向量机也取得了很好的应用效果。
1.3 论文内容及结构安排
本文主要围绕支持向量机训练算法展开:
第一章是绪论,主要论及支持向量机的研究背景与意义、支持向量机算法研究现状等。
第二章是对统计学习理论的概述。从机器学习入手,逐步介绍了学习问题的表示、期望风险与经验风险、学习过程一致性的条件、VC维理论、推广性的界、结构风险最小化等,目的是对支持向量机的理论基础—统计学习理论有一个比较系统的认识和了解。
第三章先从SVM的理论基础最优化理论入手,然后针对不同类型的分类问题,讨论相应的支持向量分类机,对支持向量机的关键思想及其特点进行了分析;最后介绍了SVM研究的具体内容,为提出新的支持向量机算法做理论准备。
第四章介绍了SVM训练算法的停机准则,以及三种典型的SVM训练算法—二次规划算法、分解算法、增量算法。
第五章对分解算法中的SMO算法进行研究,主要从如何选择优化变量、如何优化变量以及一次优化成功后相应变量的更新等方面逐步详细的介绍SMO算法。
第六章对全文进行总结并指出需要进一步研究的问题。
2 统计学习理论基础
统计学习理论是研究利用经验数据进行机器学习的一种一般理论,属于计算机科学、模式识别和应用统计学相交叉与结合的范畴,其主要创立者是Vladimir N. Vapnik。统计学习理论的基本内容诞生于20世纪60~70年代,到90年代中期发展到比较成熟并受到世界机器学习界的广泛重视。由于较系统地考虑了有限样本的情况,本文转载自http://www.biyezuopin.vip/onews.asp?id=12687统计学习理论与传统统计学理论相比有更好的实用性,在这一理论下发展出的支持向量机(SVM)方法以其有限样本下良好的推广能力而备受重视。
2.1 学习问题的表示
我们把学习问题看作利用有限数量的观测来寻找待求的依赖关系的问题。
用下面三个部分来描述从样本学习的一般模型(图2.1)
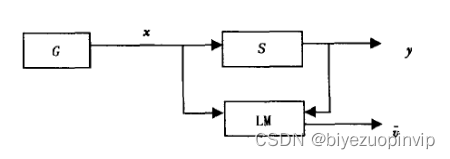
图2.1 样本学习的一个基本模型






















 1745
1745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









