







一 项目介绍
1.项目背景介绍
大数据的不断发展影响消费者生活的各个方面,也对企业的营销模式提出挑站对大数据量化分析,分析数据中的相关性分析,单因素分析等技术对消费者相关数据进行分析,能够挖掘出对企业真正有意义的信息。这就要求企业在有现的人力、物力资源下,更新并找出合理的销售方案。
对于医药企业来说,大数据为企业带来了危机也带来了商机,企业应根据自身发展阶段及药品特征,以及顾客价值最大化作为方向,以信息化为手段,并根据市场对药品需求的变化,把握消费者的个性需求,进行精准营销,与消费者建立起良性有效的互动,及时获得消费者反馈,整合传统媒体与新媒体宣传资源,选择合适的企业发展的营销战略。
随着经济的不断发展,人民生活水平文化水平的不断提升,药品超市和药房如雨后春笋般勃勃而生,很多市民都会自行购买一些常用于家庭健康的需求。药品知识由于其专业性很强 因此进行药品数据分析对医药销售起着非常重要的作用。
2.项目的目的和意义
目的:分析药品销售数据, 分析销售数据并根据历史数据预测未来的销售.
意义:便于医院提前储备未来的药品数量.
3.项目所需数据介绍
数据集网盘链接:https://pan.baidu.com/s/1oBipkEZkd4F0x1ZdZISY0g
提取码:4679
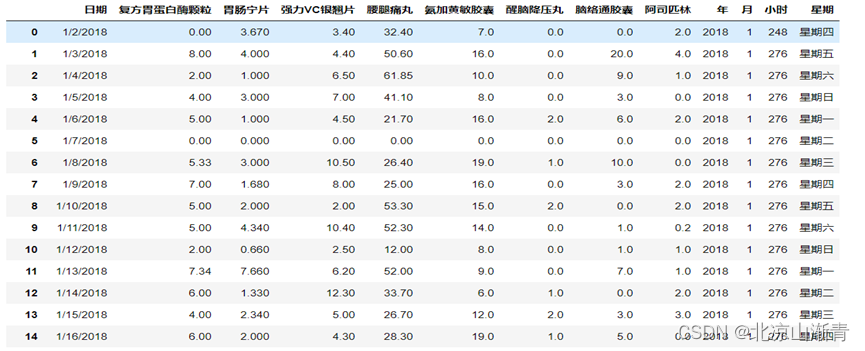
此次数据分析的数据是根据药品的销售数据,共有1461行13列数据。数据中主要包含日期, 复方胃蛋白酶颗粒, 胃肠宁片,强力VC银翘片, 腰腿痛丸,氨加黄敏胶囊,醒脑降压丸, 脑络通胶囊, 阿司匹林,年,月,小时,星期十三个基本单位。
4.项目所用算法介绍
时间序列算法
时间序列中常用预测技术 一个时间序列是一组对于某一变量连续时间点或连续时段上的观测值。
(1)移动平均法 (MA)
1.1. 简单移动平均法
设有一时间序列y1,y2,…, 则按数据点的顺序逐点推移求出N个数的平均数,即可得到一次移动平均数.
1.2 趋势移动平均法
当时间序列没有明显的趋势变动时,使用一次移动平均就能够准确地反映实际情况,直接用第t周期的一次移动平均数就可预测第1t+周期之值。
时间序列出现线性变动趋势时,用一次移动平均数来预测就会出现滞后偏差。修正的方法是在一次移动平均的基础上再做二次移动平均,利用移动平均滞后偏差的规律找出曲线的发展方向和发展趋势,然后才建立直线趋势的预测模型。故称为趋势移动平均法。
(2) 自回归模型(AR)
AR模型是一种线性预测,即已知N个数据,可由模型推出第N点前面或后面的数据(设推出P点).
本质类似于插值,其目的都是为了增加有效数据,只是AR模型是由N点递推,而插值是由两点(或少数几点)去推导多点,所以AR模型要比插值方法效果更好。
(3)自回归滑动平均模型(ARMA)
其建模思想可概括为:逐渐增加模型的阶数,拟合较高阶模型,直到再增加模型的阶数而剩余残差方差不再显著减小为止。
二项目制作过程
1.项目功能介绍
本案例的分析目标是从销售数据中分析以下几项:
(1)运用滑动平均法展示某种药品2018年~2020年情况
(2)运用时间序列预测某种药品在2022年整年的销售情况
(3)分析出某种药品在某一时间段销售情况
(4)运用不同的回归模型预测药品在2022年整年的销售情况
2.主要代码实现和解释说明
1.导入所需要的库
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import re
from statsmodels.graphics.tsaplots import plot_acf,plot_pacf
from statsmodels.tsa.arima_model import ARMA
import statsmodels.tsa.stattools as st
from statsmodels.graphics.api import qqplot
from statsmodels.stats.stattools import durbin_watson
# 设置字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus']=False
2.查看数据的缺失值和重复值并预览数据
data = pd.read_csv("C:\\Users\\山渐青\\Desktop\\数据分析实训\\drug_1.csv",engine='python')
# 缺失值
print(data.isnull().sum())
# 重复值
print(data.duplicated().sum())
data
3.统计其中某一药品的销售数据随时间变化趋势
orig = pd.Series(data.胃肠宁片.tolist( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1803
1803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









