









需要使用这2个函数的场景,可能是Distinct,可能是Dictionary,都是和HashTable有关,所以有必要先介绍一下哈希表。
哈希表
哈希表是一种数据结构,又叫散列表。这种数据结构有2部分组成:
- 动态数组,即左边一列0-15,每个元素称之为bucket
- 每个bucket,对应了一个单向链表,可能为空链表
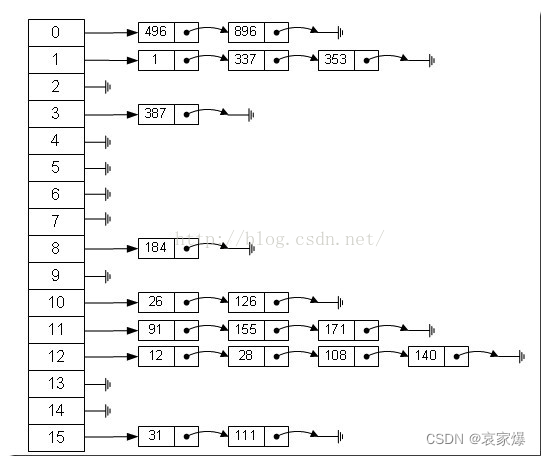
新插入的元素通过哈希函数(常用的是除取余法),对应到每一个bucket中,然后再插入到链表尾部。
GetHashCode
其实就是哈希函数的实现,返回值就是哈希码,
equals
找到了bucket之后,还会再判断是否与bucket中已有的元素相等,若不相等,则插入。
执行顺序:
- 先执行GetHashCode用于快速判断,
- 若没有相同的hashcode,则放入一个新的bucket,无需执行equals
- 若有相同的hashcode,则放入相同的hashcode对应的bucket,再执行equals
- 若equals返回true,即相等,则不放入(去重的时候,就认为2个元素相同)
- 若equals返回false,即不相等,则放入
Distinct
情况1
public class Point
{
public double X { get; set; }
public double Y { get; set; }
public double Z { get; set; }
public Point(double x, double y, double z)
{
X= x;
Y= y;
Z= z;
}
public override bool Equals(object obj)
{
var result = base.Equals(obj);
return result;
}
public override int GetHashCode()
{
int result = base.GetHashCode();
return result;
}
}
Point p0 = new Point(1.0001, 2.0001, 3.0001);
Point p1 = new Point(1, 2, 3);
Point p2 = new Point(1, 2, 3);
var points = new List<Point> { p0, p1, p2 };
var newPoints = points.Distinct().ToList();
执行了Distinct去重函数,会自动调用Point自身的GetHashCode和Equals,本例中,我们实现的是默认重载,
- GetHashCode,对于引用类型,返回的是对象的地址,所以只要不是同一个对象,一定返回不同的hashcode,因此在本地中,GetHashCode对于p0、p1、p2返回3个不同的值,所以无需再进行equals的验证。
因此Distinct的结果包含了p0、p1、p2共3个点
情况2
我们来修改一下GetHashCode和Equals,即不管是不是同一个对象,我们只来比较Point类型的实例是不是挨的很近,如果在给定范围内,就认为是相同的点
public class Point
{
public double X { get; set; }
public double Y { get; set; }
public double Z { get; set; }
public Point(double x, double y, double z)
{
X= x;
Y= y;
Z= z;
}
public override bool Equals(object obj)
{
var other = obj as Point;
return Math.Abs(X-other.X)<0.01&&
Math.Abs(Y - other.Y) < 0.01 &&
Math.Abs(Z - other.Z) < 0.01 ;
}
public override int GetHashCode()
{
return 1;
}
}
Point p0 = new Point(1.0001, 2.0001, 3.0001);
Point p1 = new Point(1, 2, 3);
Point p2 = new Point(1, 2, 3);
var points = new List<Point> { p0, p1, p2 };
var newPoints = points.Distinct().ToList();
Distinct执行过程:
- 插入p0点,并计算其hashcode,放入某一个bucket,p0为该bucket中的链表中的第一个元素
- 插入p1点,并计算其hashcode,发现与p0相同,放入p0所在的bucket,再执行equals,发现与p0相同,丢弃
- 插入p2点,并计算其hashcode,发现与p0相同,放入p0所在的bucket,再执行equals,发现与p0相同,丢弃
因此Distinct的结果包含了p0共1个点
情况3
public override bool Equals(object obj)
{
var other = obj as Point;
return X == other.X &&
Y == other.Y &&
Z == other.Z;
}
public override int GetHashCode()
{
return 1;
}
Distinct执行过程:
- 插入p0点,并计算其hashcode,放入某一个bucket,p0为该bucket中的链表中的第一个元素
- 插入p1点,并计算其hashcode,发现与p0相同,放入p0所在的bucket,再执行equals,发现与p0不同,挂在p0后面,此时链表中有2个元素
- 插入p2点,并计算其hashcode,发现与p0相同,放入p0所在的bucket,再执行equals,发现与p0不同,但是与p1相同,丢弃
因此Distinct的结果包含了p0、p1共2个点。
小结
不同的场景,不同的实现。但是如果偷懒GetHashCode返回同样的值,最终通过equal去判断,虽然可以实现想要的效果,但是同一个bucket中最终挂的元素太多的话,链表的查找也是很慢的。。。所以最好在GetHashCode也需要对应重写,尽量在第一步中,就能把不同的元素放到不同的bucket中。
HashSet和Dictionary
Point p0 = new Point(1.0001, 2.0001, 3.0001);
Point p1 = new Point(1, 2, 3);
Point p2 = new Point(1, 2, 3);
HashSet<Point> set = new HashSet<Point>();
set.Add(p0);
set.Add(p1);
set.Add(p2);
Dictionary<Point, string> keyValuePairs = new Dictionary<Point, string>();
keyValuePairs.Add(p0, "0");
keyValuePairs.Add(p1, "1");
keyValuePairs.Add(p2, "2");
调用方式及顺序和Distinct一模一样。
IEqualityComparer
上面是把2个函数的实现,放在Point内部进行的。有时候我们拿到的是别人提供的API,没有权限对其进行修改,那怎么重写呢?
可以实现一个IEqualityComparer:
public class PointComparer : IEqualityComparer<Point>
{
public bool Equals(Point x, Point y)
{
return Math.Abs(x.X-y.X)<0.000001&& Math.Abs(x.Y - y.Y) < 0.01&&Math.Abs(x.Z - y.Z) < 0.01;
}
public int GetHashCode(Point obj)
{
return 1;
}
}
这样子,在调用Distinct的时候,手动指定比较器即可:
var newPoints = points.Distinct(new PointComparer()).ToList();
var set = new HashSet<Point>(new PointComparer());
var keyValuePairs = new Dictionary<Point, string>(new PointComparer());
C++STL中的相应容器
| c# | c++ | 底层数据结构 |
|---|---|---|
| Dictionary | unorder_map | hashtable |
| HashSet | unorder_set | hashtable |
| SortedDictionary(没用过) | map/set | rb_tree |
散列表与红黑树的对比:
相对散列表,二叉查找树好像并没有什么优势,那我们为什么还要用二叉查找树呢?
第一,散列表中的数据是无序存储的,如果要输出有序的数据,需要先进行排序。而对于二叉查找树来说,我们只需要中序遍历,就可以在 O(n) 的时间复杂度内,输出有序的数据序列。
第二,散列表扩容耗时很多,而且当遇到散列冲突时,性能不稳定,尽管二叉查找树的性能不稳定,但是在工程中,我们最常用的平衡二叉查找树的性能非常稳定,时间复杂度稳定在 O(logn)。
比如:红黑树的插入、删除、查找各种操作性能都比较稳定。对于工程应用来说,要面对各种异常情况,为了支撑这种工业级的应用,我们更倾向于这种性能稳定的平衡二叉查找树
第三,笼统地来说,尽管散列表的查找等操作的时间复杂度是常量级的,但因为哈希冲突的存在,这个常量不一定比 logn 小,所以实际的查找速度可能不一定比 O(logn) 快。加上哈希函数的耗时,也不一定就比平衡二叉查找树的效率高。
第四,散列表的构造比二叉查找树要复杂,需要考虑的东西很多。比如散列函数的设计、冲突解决办法、扩容、缩容等。平衡二叉查找树只需要考虑平衡性这一个问题,而且这个问题的解决方案比较成熟、固定。
性能稳定的平衡二叉查找树
第三,笼统地来说,尽管散列表的查找等操作的时间复杂度是常量级的,但因为哈希冲突的存在,这个常量不一定比 logn 小,所以实际的查找速度可能不一定比 O(logn) 快。加上哈希函数的耗时,也不一定就比平衡二叉查找树的效率高。
第四,散列表的构造比二叉查找树要复杂,需要考虑的东西很多。比如散列函数的设计、冲突解决办法、扩容、缩容等。平衡二叉查找树只需要考虑平衡性这一个问题,而且这个问题的解决方案比较成熟、固定。
==
Equals会调用对应类型的Equals函数,而==则是直接比较两者之间地址是否相同。
Tips:
c#中的string的 ==进行了重载,即string的==和equals效果是相同的,都是比较值是否相等
IEquatable
class Person:IEquatable<Person>
{
public string Name { get; set; }
public bool Equals(Person other)
{
if (other == null)
{
return false;
}
return this.Name == other.Name;
}
}
效果上来说,其实和重写Equals和GetHashcode一样。
不过IEquatable是显示的接口,并且不需要重写GetHashcode,直接根据自身需要进行具体实现,更直观一些

















 1017
1017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









